


作为一名数据工程师,我一直希望开发数据驱动的应用程序,为数据科学和商业智能提供动力。我希望构建能够增加价值并提供竞争优势的产品和服务,因为数据正在成为智能决策的源泉。
我了解到,准确和实时的数据是关键驱动因素。
我还看到一些组织缺少数据,并且对绩效、行业等没有真正的了解。他们倾向于根据不准确的信息或他们认为正确的信息来做出决策。
与此同时,利用数据的公司正在更好地了解其市场、业务和竞争对手的地位。这类信息建立信心。这是一种竞争优势。
数据管道是如何工作的?
那么,组织如何保持其数据最新并朝着这种优势努力呢?
数据管道……分析成功的基石。
通常,数据驱动型公司会聘请数据工程师/架构师来实施提取-转换-加载 (ETL) 工具,这些工具是其基础设施内的数据管道。
但他们究竟是如何做到的呢?
构建数据管道有哪些步骤?
数据管道将包含几个步骤,包括从源提取、数据预处理、验证以及数据目标。让我们看一个简单的例子。
在这个用例中,我正在从黑胶唱片市场抓取数据,并且我想对这些商品的价格进行分析。
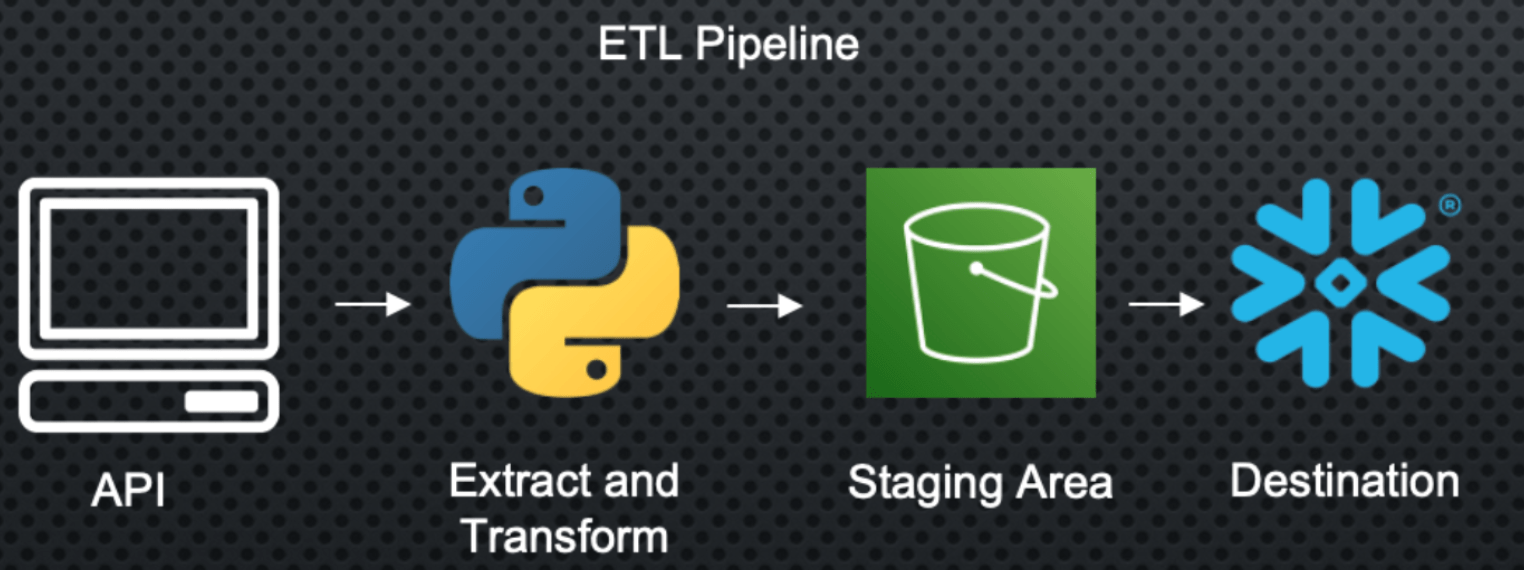
构建数据管道的过程
这里的第一步是访问 API 或数据库,并使用我制作的 python 脚本提取我们正在寻找的数据。
这太棒了,因为我现在有数据了!
问题在于,它不是我想要的格式,所以我需要执行一些转换才能获得所需的数据集。
完成此操作后,我可以将其加载到暂存区,例如 AWS S3 或 Azure Blob,用于数据存储。我称之为暂存区是因为我想将其用作最终目的地的垫脚石。
为了确保其可靠性,我需要构建一些测试、警报和备份计划,以防出现问题或耗时过长。最后,我的数据仓库将识别暂存区中的新记录,并摄取新数据,以便为组织内的分析师和数据科学家维护最新的数据集。
砰!现在,我的报告和机器学习模型已连接到这个最终数据源,该数据源以我选择的速度馈送数据!管道已就位、已部署,我不再需要手动触摸它们或摄取数据(希望如此)。
这只是一个数据源,但现在我可以找到其他来源,看看是否可以通过其他管道引入外部来源,以增强我的数据并继续构建数据管道的竞争优势。查看下面的代码,以更深入地了解 ETL 代码。
import psycopg2
import csv
import boto3
import configparser
import os
import pandas as pd
from bs4 import BeautifulSoup
import requests
from time import time
from datetime import datetime
# config credentials from env
access_key_id = os.environ.get('AWS_ACCESS_KEY_ID')
aws_secret_access_key = os.environ.get('AWS_SECRET_ACCESS_KEY')
bucket_name = 'discog-data'
# scrape data
startTime = time()
url = '...'
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
results = soup.find(id="pjax_container")
record_elements = results.find_all("tr", class_="shortcut_navigable")
item_list = []
price_list = []
sellers_list = []
total_price_list = []
link_list = []
for record_element in record_elements:
item_description = (record_element.find("a", class_="item_description_title"))
item_list.append(item_description.text)
price = (record_element.find("span", class_="price"))
price_list.append(price.text)
seller = record_element.find(lambda tag: tag.name == 'a' and tag.get('href') and tag.text and '/seller/' in tag.get('href'))
sellers_list.append(seller)
total_price = (record_element.find("span", class_="converted_price"))
total_price_list.append(total_price)
record_info = record_element.find(lambda tag: tag.name == 'a' and tag.get('href') and '/sell/' in tag.get('href'))
link = record_element.find("a", class_="item_description_title", href=True)
link_list.append(link['href'])
# create cols from item description
artists = [str(item).split('-')[0].rstrip() for item in item_list]
albums = [str(item).split('-')[1].lstrip() for item in item_list]
album_class = [str(item[item.find("(")+1:item.find(")")]) for item in item_list]
total_price_list = [item.text if item is not None else '0' for item in total_price_list]
my_dict = {'item_description': item_list,
'artists': artists,
'album': albums,
'album_class': album_class,
'seller': sellers_list,
'price': price_list,
'total price': total_price_list}
filename = f'discogs_market_data_{datetime.now().strftime("%Y%m%d-%H%M")}.csv'
df = pd.DataFrame(my_dict)
df.to_csv(filename, index=False)
# load file to S3
s3 = boto3.client('s3',
aws_access_key_id=access_key_id,
aws_secret_access_key=aws_secret_access_key)
s3_file = filename
s3.upload_file(filename, bucket_name, s3_file)
print(f' execution time: {(time() - startTime)}')