


“你能给我 X 的数据吗?” - 数据科学家可能会经常收到这样的问题 - 我们的团队也一样。
即使在大多数情况下,人们要求的数据并不是他们真正需要的,但这仍然是一个不寻常的迹象。
我们意识到,我们收到这些问题的原因之一是我们未能为自助分析实施基础。我们需要面对现实并承认手头的问题
- 我们在教育人们如何使用和分析数据方面做得不好;
- 由于不同数据源之间糟糕的集成,非工程师或没有数据库和 SQL 知识的人员无法组合数据进行分析;
- 数据科学成为数据驱动决策的瓶颈,甚至在我们速度太慢时会阻止决策的制定;
什么是 OKR,以及我们为什么决定将它们用于我们的数据科学团队
需要进行向更大数据可访问性和启用自助分析的战略转变,我们需要一个框架来正确地调整团队并能够衡量我们的进展。在那段时间里,我们公司开始研究 OKR(目标和关键结果)。OKR 是一种团队目标设定方法,可帮助您设定可衡量的目标。关键思想是您定义雄心勃勃的目标,这些目标可以通过3-5 个关键结果来衡量,其中可以使用以下模板
我将[目标],通过[关键结果]衡量。
我们的数据科学团队希望成为先驱并尝试该框架。我们选择这条道路的一些原因如下:
- 我们希望作为一个团队共同定义目标,以提高一致性和目标所有权;
- 我们希望能够以透明的方式衡量我们的进展;
- 我们的日常工作应与我们想要实现的目标紧密联系;
我们共同坐下来分析当前情况,以得出目标和关键结果。我们的目标是为未来更大的步骤奠定基础,并开始建立具有预连接和处理表的数仓结构,以便我们的业务用户轻松分析。因此,我们为自己设定的一个示例目标是“公司中的每个人都可以访问数据”。
使用 Metabase 仪表盘跟踪数据科学的 OKR 进展情况
这包括以下我们用来衡量成功的关键结果
- Metabase 中的所有新问题仅使用数仓;
- Metabase 中的问题以清晰的结构存储;
- 所有数仓表都有描述;
- 数仓层中业务用户的所有表列都有描述;
乍一看,这些听起来像是非常基本的关键结果。但是,事实证明,它们在衡量基本可访问性方面发挥了关键作用。
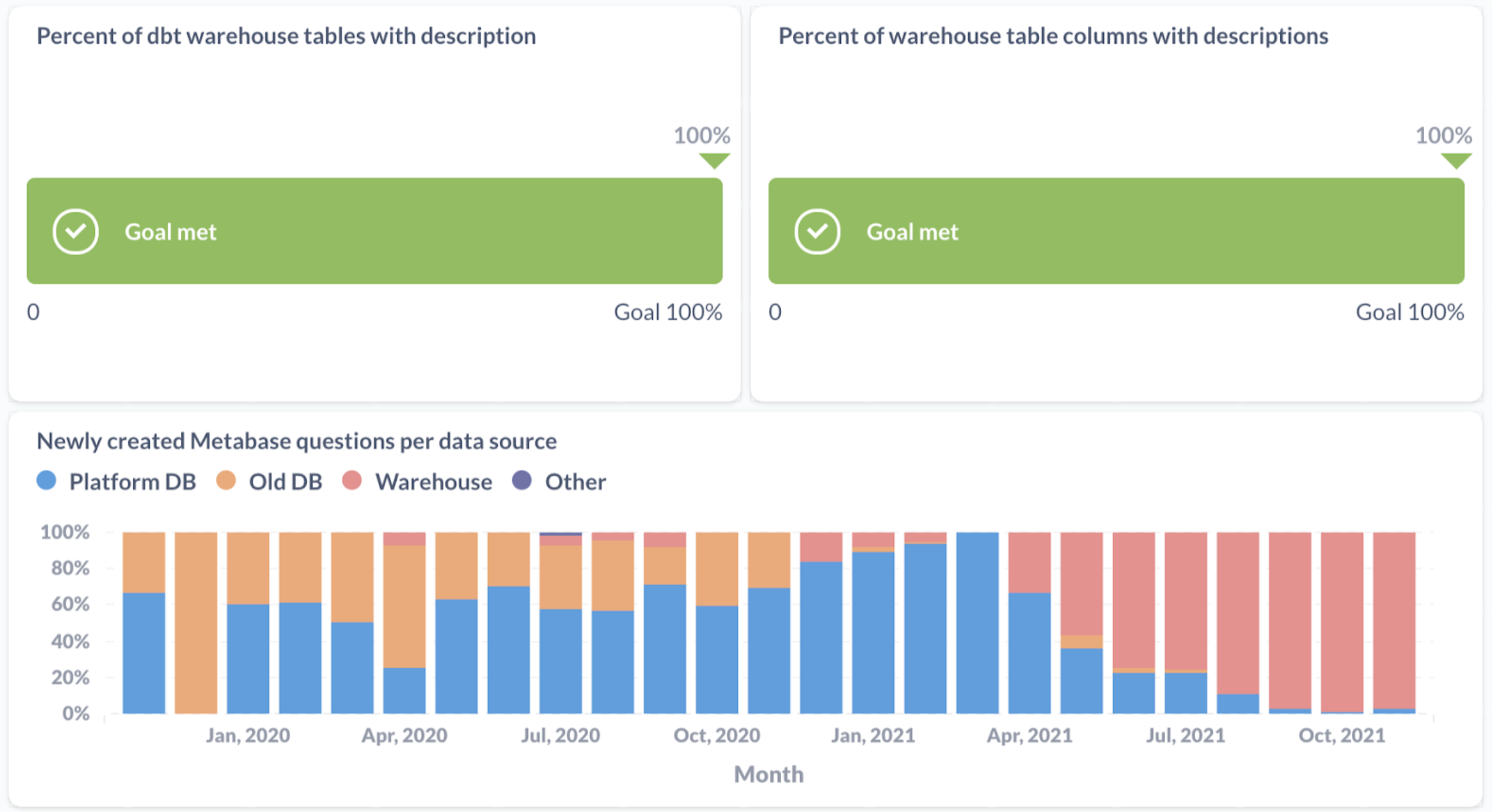
我们在 Metabase 中创建了一个仪表盘来衡量我们的进展,并在我们的每周 OKR 进展情况检查中查看数据
我们在 Metabase 中设置 OKR 仪表盘所采取的步骤
免责声明:以下步骤是为具有 BigQuery 的数仓设置和使用 Postgres 数据库运行的 Metabase 实例量身定制的
- 将 Metabase 与您的 BigQuery 项目连接 (文档)
- 将 Metabase 连接到存储 Metabase 数据的 Postgres 数据库 (有关如何连接到 Postgres 数据库的文档)
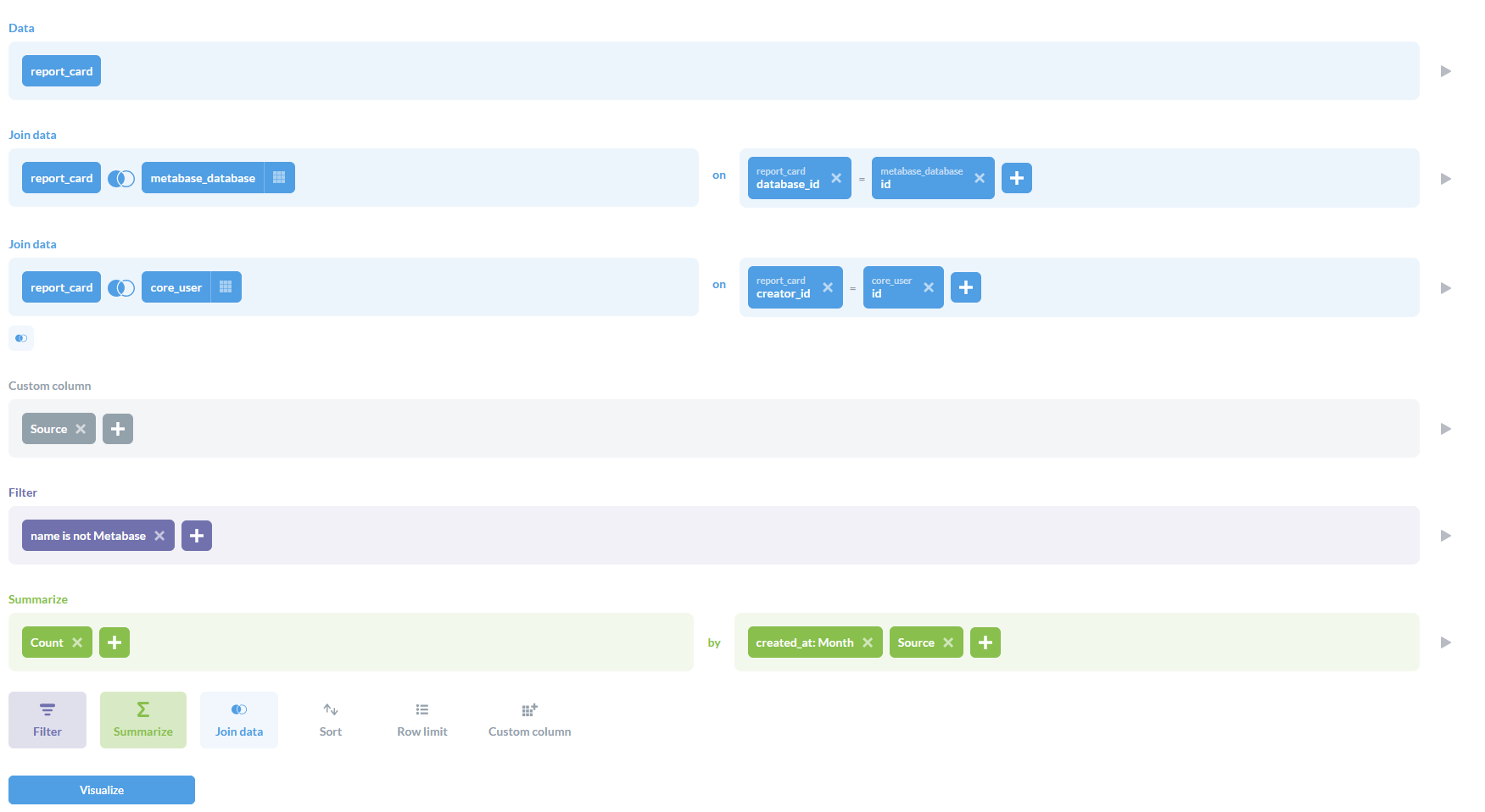
- 创建您想在仪表盘中看到的问题(与下面的模板查询进行比较)
- 将所有新创建的问题组合在一个仪表盘中。
查询模板
如果您想构建类似的东西,这里有一些查询模板可以帮助您入门。为了使其适用于您,您可能需要替换以下查询中的一些变量
<YOUR_DATA_REGION>:您的数据存储区域,例如 region-europe-west1 <YOUR_GOOGLE_PROJECT_NAME>:您的 Google Cloud 项目名称
带有描述的 dbt 数仓表的百分比
显示使用 dbt 创建的且带有描述的数仓表和视图的进度。
我们为此使用了这个 SQL 查询
WITH descriptions AS (
SELECT
table_name,
1 AS has_description,
FROM `<YOUR_DATA_REGION>.INFORMATION_SCHEMA.TABLE_OPTIONS`
WHERE
option_name = 'description'
AND option_value <> '""'
AND table_schema LIKE 'dbt%'
)
SELECT
SUM(COALESCE(has_description, 0)) / COUNT(*) AS ratio
FROM `<YOUR_DATA_REGION>.INFORMATION_SCHEMA.TABLES`
LEFT JOIN descriptions USING(table_name)
WHERE
table_catalog = '<YOUR_GOOGLE_PROJECT_NAME>'
AND table_schema = 'dbt_marts'
带有描述的数仓列的百分比
显示带有描述的数仓表列的进度。
我们为此使用了这个 SQL 查询
SELECT
SUM(IF(description IS NOT NULL AND description != '', 1, 0)) /
COUNT(*) AS ratio,
FROM `<YOUR_DATA_REGION>.INFORMATION_SCHEMA.COLUMN_FIELD_PATHS`
WHERE
table_catalog = '<YOUR_DATA_REGION>'
AND table_schema = 'dbt_marts'
每月和数据源新创建的 Metabase 问题
显示每月和数据源新创建问题的份额。排除使用 Metabase 数据库的问题。
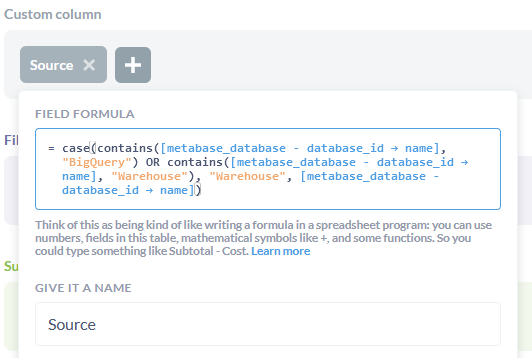
我们为此使用了查询构建器
结果
尽管还有很长的路要走,但我们已经看到了对我们工作的巨大影响。您可以在仪表盘中看到的一个例子是,新创建的问题几乎完全使用新的数仓而不是旧数据库。特别是通过 OKR 框架实现的团队协作帮助我们改进了数据堆栈,并在公司中实现自助分析方面迈出了巨大的一步。