


指标层是必需的迹象
“仪表盘 A、B 和 C 上的用户数量不同。你能解释一下是怎么回事吗?”
“此报告中此计数的定义已过时。我们可以尽快修复吗?”
这些是我作为商业智能分析师每周(如果不是每天)被问到的常见问题的示例。这表明指标已经失控,并为必须根据数据做出决策的最终用户造成了混乱。即使是我们创建了数据,这也为数据团队带来了更多工作。随着业务的增长和变化,其跟踪的指标也会随之变化。并且随着其收集的数据变得更加丰富,其复杂性也随之增加。
考虑计算用户的基本场景。听起来很容易做到,对吧?但以下是我在工作中不得不面对的一些常见问题
- 我在什么时间范围内计算用户?每天?每周?每月?
- 我是否按地理区域划分?如何定义(州、县、MSA)?
- 当我计算用户时,如何知道是否有重复项?我在什么粒度级别上去重?
- 我只想要活跃用户。我如何确定用户是否活跃?是否有标志列,或者如果一段时间后没有交易,我是否将用户视为不活跃?这段时间是多久?
- 在计数时,我需要注意数据中是否有其他标志或过滤器?我是否打开或关闭它们?无数更多注意事项取决于您的领域。
在分析中,计数实际上非常困难。当多个消费渠道上应该相同的指标的数字不一致时,用户开始失去对数据的信任,并且数据团队需要跟踪究竟发生了什么,这会成为令人头疼的问题。
什么是指标层?
但是,该领域正在涌现一种解决方案:指标层的概念(此概念的其他术语是无头 BI 或指标存储)。
您知道 Github 如何成为项目代码库的中央存储库吗?或者数据仓库如何成为数据的单一事实来源?指标层可以成为组织中如何定义指标的中央、单一事实来源。
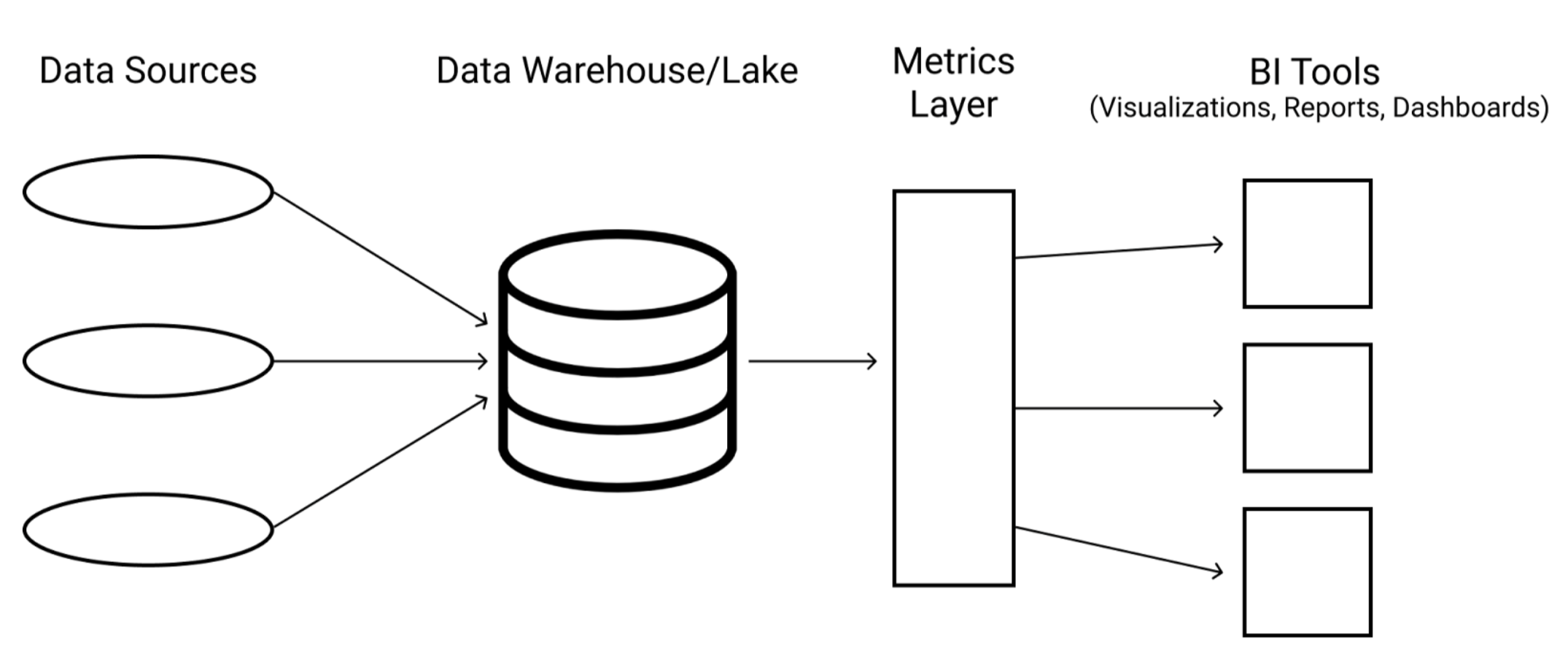 指标层应位于数据存储位置和数据使用方式之间,以实现统一的定义
指标层应位于数据存储位置和数据使用方式之间,以实现统一的定义
您的组织有多个仪表盘。它也可能拥有多个商业智能 (BI) 工具。您真的想在每个渠道中每次都定义指标的业务逻辑吗?如果业务增长导致逻辑发生变化怎么办?这会增加在某人查看并做出决策时,某个实例略有偏差或过时的可能性。但是,在多个地方使用的单个、商定的定义解决了这个难题,并且是 DRY 原则(不要重复自己)的一个很好的例子。
如何开始定义指标层?
一开始不必是一个完全工程化的功能。首先只需定义指标应如何计算。写出一个 SQL 查询或用于创建指标的一系列步骤,并将其保存在多个用户可以参考和提供输入的位置(但要注意不要将代码复制并粘贴到各种工具中)。然后将其移动到多个工具可以访问定义的位置。您可以基于 SQL 查询创建表或视图,并将其存储在数据仓库中。
当您准备就绪时,定义一个指标层,您可以在其中从中心位置共享指标(在撰写本文时,Metabase 在即将推出的功能中提供了此功能)。一些工具允许各种 BI 解决方案连接到 API 以访问指标,并让您在保持指标定义不变的情况下交换它们(因此,称为“无头 BI”)。
如何定义指标层?
多种工具可以帮助您尝试填补现代数据堆栈中缺失的这一部分。一般轮廓是
1) 确定您要跟踪哪些指标。听起来很简单,但正如我在开头的示例中概述的那样,它可能会很快失控。您要衡量什么,您想要如何聚合,以及您想要按哪些维度对数据进行切片?您是否想在指标中包含任何过滤器/约束?
2) 根据您选择的用于实现指标层的工具,您需要定义这些配置。在某些工具中,您将在 YAML 文件中设置这些定义。
3) 既然您已经定义了指标,就该测试它们了。指标层的灵活性意味着,您不必预先聚合度量和维度的每种可能的组合,而是只需定义可能性,并让工具处理它,以便无论谁在使用哪种 BI 工具中提取指标,您最终都会得到相同的数字。上述工具提供的 API 可用于提取指标。
指标层是 BI 领域令人兴奋的发展,可以解决分析师的许多难题和重复性问题。与其锁定定义并在所有数据消费工具中重复复杂的业务逻辑,不如尝试在您的组织中定义指标的“单一事实来源”!