


减少临时分析
在我们公司,我们奉行数据民主策略。这意味着我们积极避免数据孤岛,并在全公司范围内分享关于我们数据方面的知识。这对每个人都是完全透明的。有了 Metabase 作为我们的 BI 工具,这变得非常容易,我帮助人们快速上手。但有时,在数据仓库的报表区域中,会出现需要全新的表格模型的问题。在大多数情况下,构建新模型的工作量太大,所以我会在 Metabase 的 SQL 编辑器中编写临时查询。
这可能会导致很多调整,因为人们对不止一个细节感兴趣。但大多数问题都发生在我完成最后一个查询之后,这会消耗大量资源,我的同事需要等到我每次完成更改 WHERE 子句中的表达式后才能继续。
这些重复出现的问题有其存在的意义,并表明人们实际上对这些数据感兴趣。那么,如果我可以让我的同事自己更改过滤器,使整个过程更精简、可定制且用户友好,那会怎么样呢?
好吧,这就是我使用变量所做的事情。
在 Metabase 中开始使用变量
Metabase 中的变量是将用户输入插入到现有 SQL 代码中的绝佳方法。它们以 {{}} 初始化,并创建一个过滤器小部件。此小部件接受用户输入并直接将其放置在变量的位置。这是一个简单的例子:
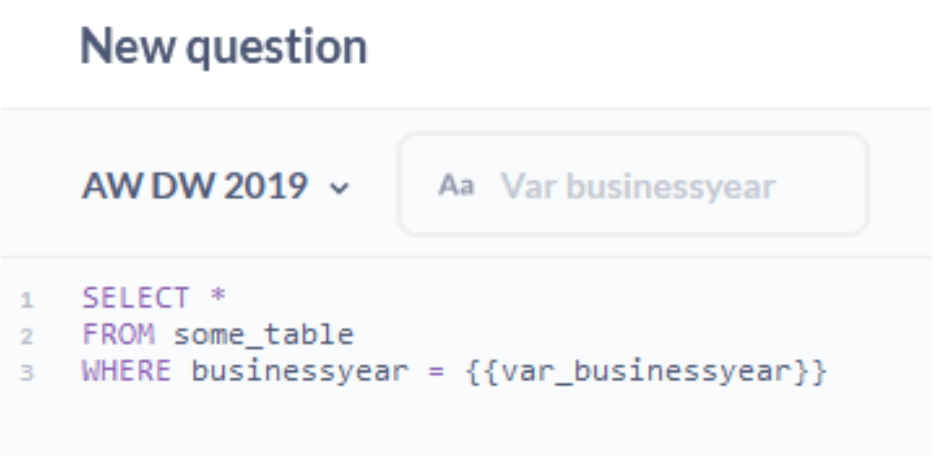
使用 [[]],您可以使表达式成为可选的。只要没有在相应的过滤器小部件中输入任何内容,它对源代码就是不可见的。当使用多个过滤器时,效果最佳。
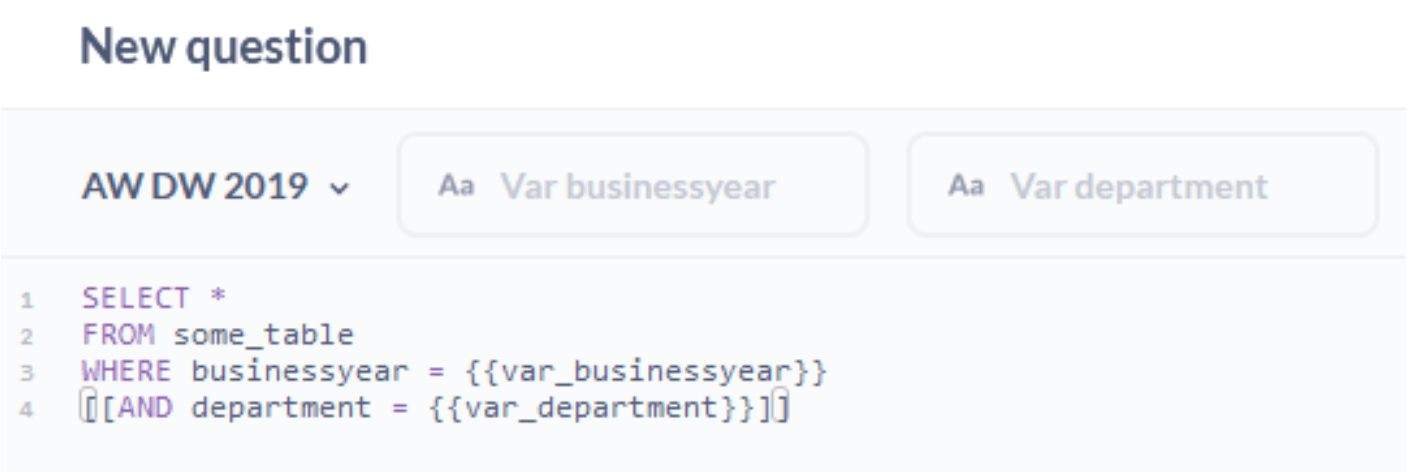
如您所见,您不受过滤器小部件数量的限制。如果您有一个包含大量过滤选项的较大查询,只需将可选子句链接在一起即可。如果您这样做,最佳实践是以 1 = 1 开头您的 WHERE 块,因为它是一个有效的且可以独立存在的过滤器子句。因此,如果没有向任何小部件提供输入,您的代码仍然可以工作。
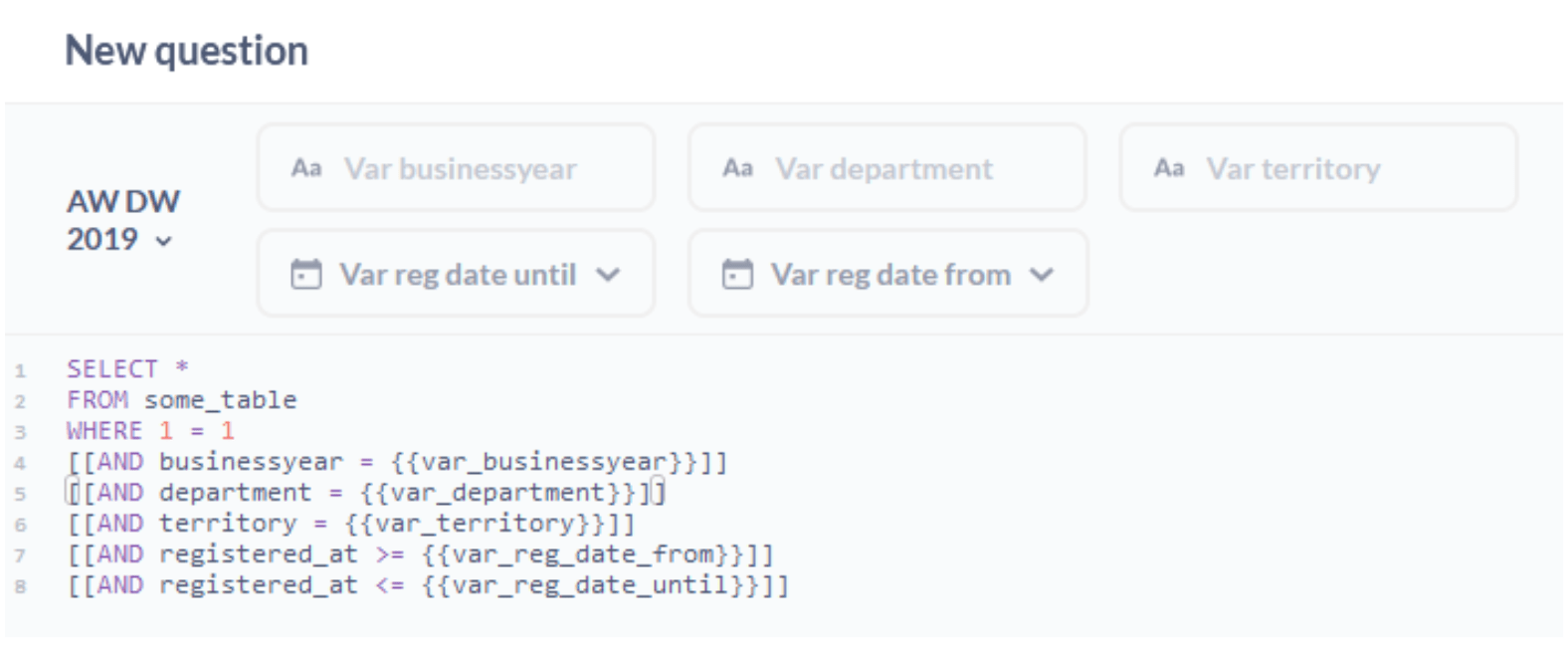
简短的旁注:日期的部件看起来有点不同。这是由于数据类型的原因。您可以选择 Metabase 本机能够解释的 3 种数据类型。对于这两个部件,我选择了“日期”,它创建了一个可点击的日期选择器部件。
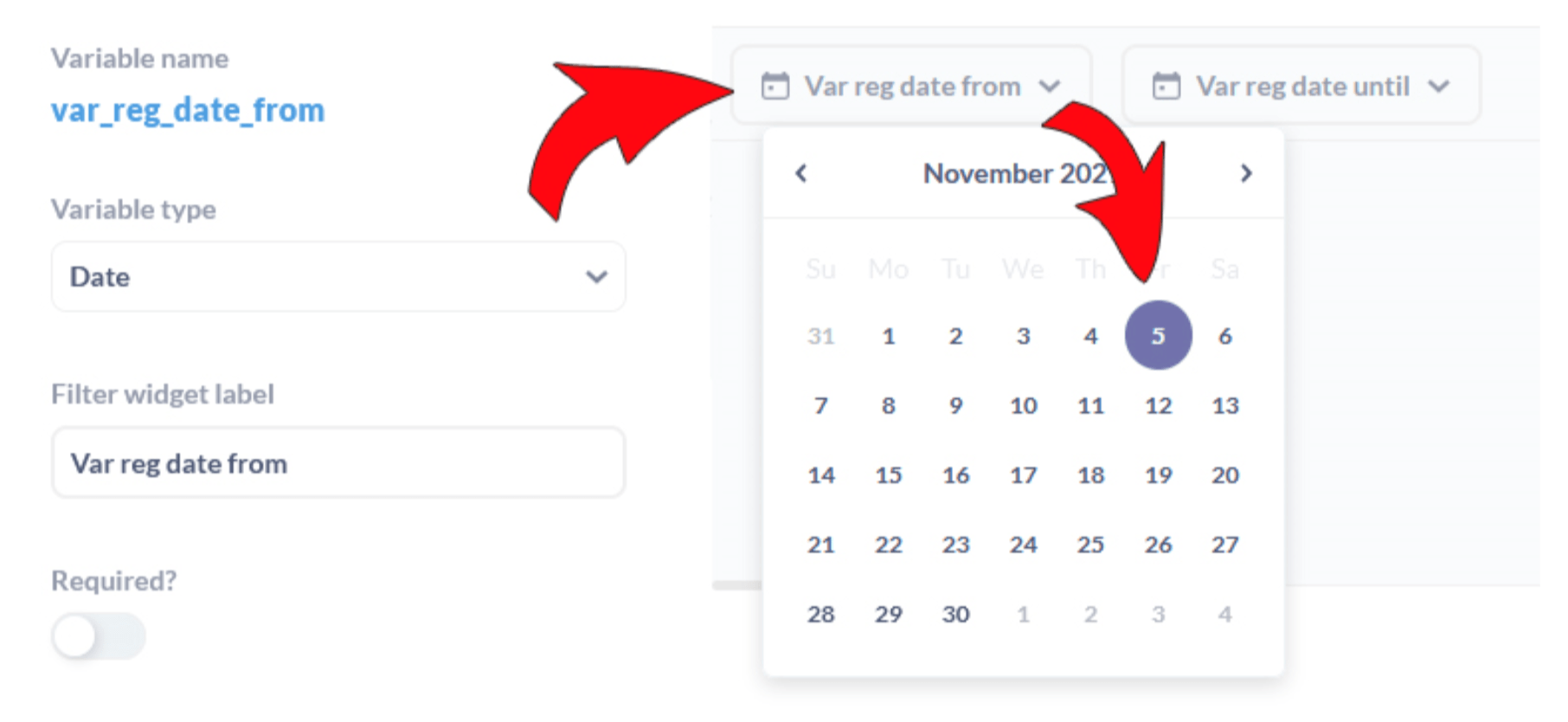
这些是我必须学习的基础知识,我希望我为您提供了这些知识的良好而快速的概述。
在某个时候,我就想“嘿,这只是文本。就像 Python 中的 f 字符串一样。” 因此,我开始尝试使用一些 SQL 函数来操作此输入。结果表明,任何方法都行得通,因此我决定构建一些很酷的东西,例如接受多个关键字作为输入的过滤器。如果您对它是如何工作的感兴趣,请查看我在 Medium 上关于变量的详细帖子。