


在之前的文章中,我们分解了如何使用 Materialize 和 Metabase 构建流式分析管道。简而言之,您可以针对流式数据源编写一些 SQL,让 Materialize 有效地保持您的结果随着新数据的到来而更新,并保持仪表板的轻量化和新鲜度。这一次,我们将探讨如何使用 dbt 来端到端地管理和记录此工作流程。
使用 dbt 转换流数据
尽管您希望不停地运行分析,但您可能不想放弃使您在批处理中高效的工具。如果您可以使用完全相同的工具来管理您的流式分析管道,那会怎么样?尽管 dbt 的构建考虑了批处理,但作为一个框架,它足够灵活,可以用作批处理和流式后端的统一转换层;只要后端是基于 SQL 的,底层运行的内容就变成了实现细节。
我们构建了 dbt-materialize 适配器,将流式转换(及其他功能)引入 dbt。如果这看起来很熟悉……
{{ config(
materialized ='materializedview'
) }}
SELECT fi.icao24,
manufacturername,
model,
operator,
origin_country,
time_position,
longitude,
latitude
FROM {{ ref('stg_flight_information') }} fi
JOIN {{ ref('stg_icao_mapping') }} icao ON fi.icao24 = icao.icao24
……就是这样:您使用 SQL 和一些 Jinja 将业务逻辑定义为 dbt 模型,部署管道(一次),Materialize 会为您保持运行。对于原本需要您每天多次重新部署模型 ($$)、维护复杂的增量逻辑并进行一些严重的权衡以优化速度(例如,正确性)的用例,使用像 Materialize 这样的专用流式数据库 可以让您更快、更进一步。
记录流式分析管道
dbt 不仅标准化了我们推理和管理分析工作流程的方式,还使文档重新变得酷炫(嗯,在 dbt 之前真的酷炫过吗?)。借助一些 YAML 文件,您可以将数据治理引入您的流式管道,加速数据发现和沿袭等救生流程,甚至 确保您的指标保持不变。如果趋势是将您的 dbt 项目视为业务逻辑和文档的真实来源,那么您的 BI 工具难道不应该……同步吗?
如何同步 dbt 和 Metabase
如果您希望更紧密地将 dbt 和 Metabase 结合在一起,dbt-metabase 插件是一个很好的起点。例如,您可以使用它来
将 Metabase 项记录为 dbt 暴露
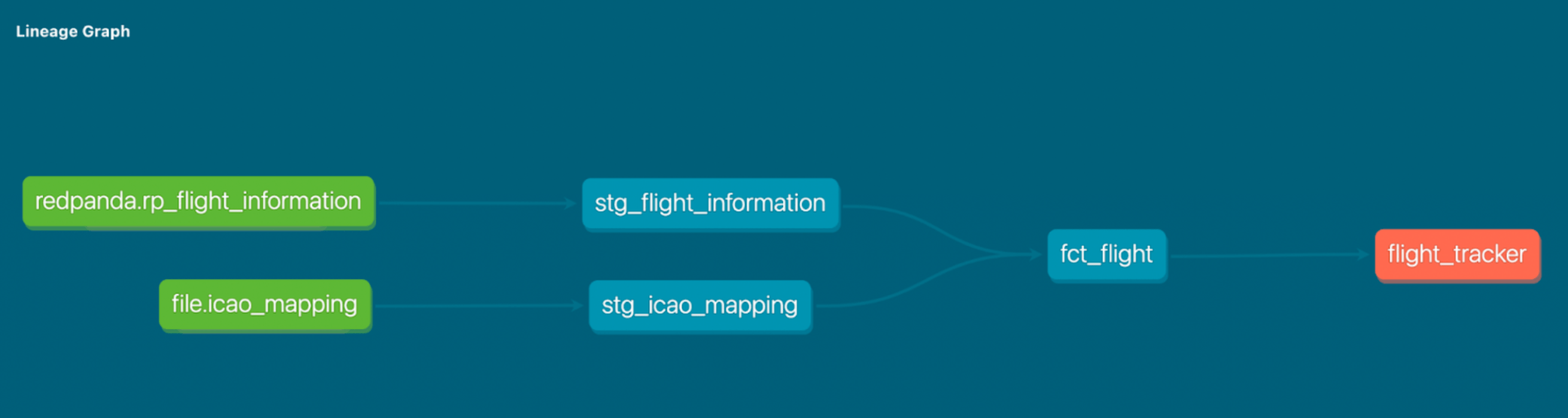
要充分了解 dbt 项目的端到端依赖关系,还需要能够跟踪外部依赖关系,例如 Metabase 问题和仪表板。在 DAG 中跟踪这些依赖关系的一种方法是将任何模型下游用法声明为 暴露(注意橙色节点!),您可以使用插件自动生成这些暴露
将 dbt 元数据传播到 Metabase 数据模型
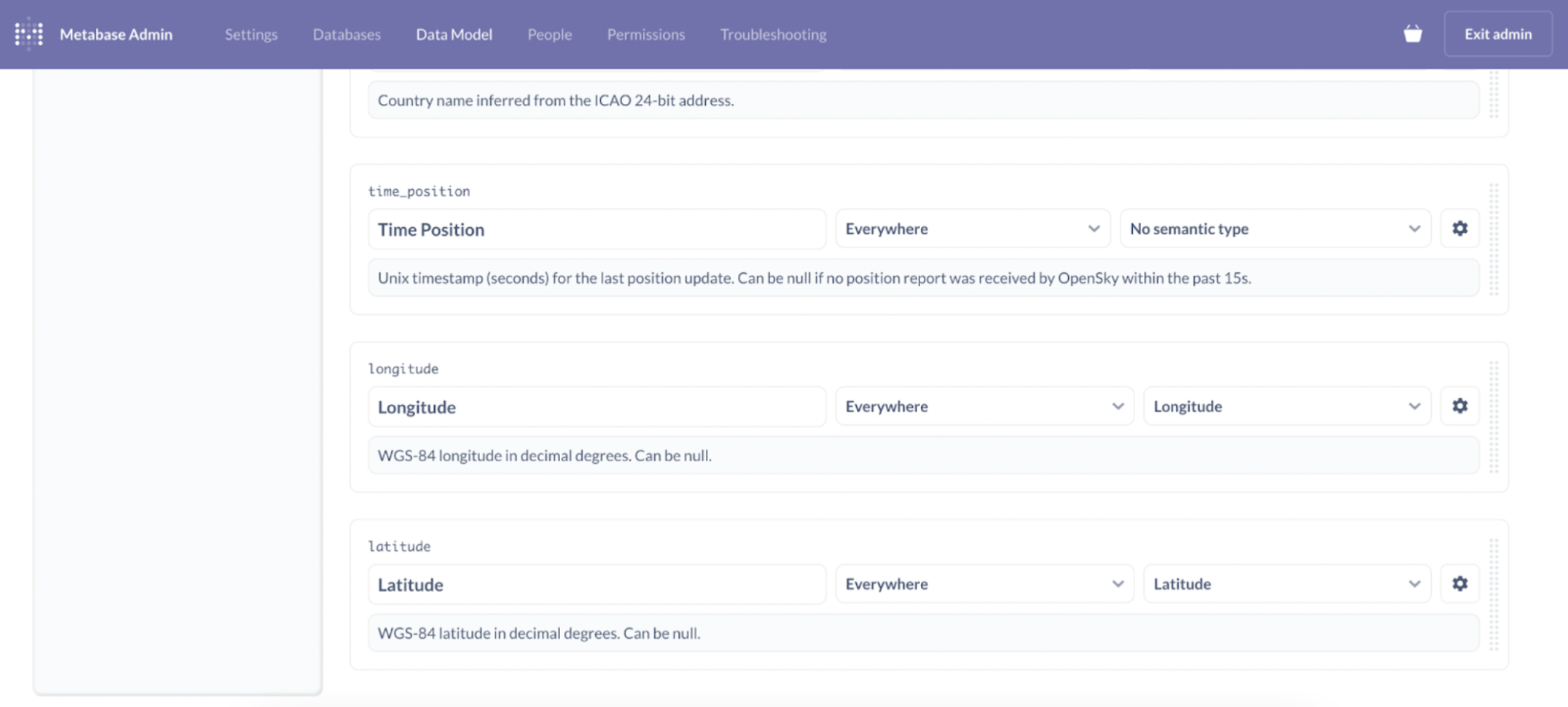
如果您已经在 dbt 中记录了数据模型,该插件还允许您从现有的模型属性和配置(如表和列描述、语义类型定义以及其他有助于在数据生产者和消费者之间创建共享上下文的有用元数据)派生 Metabase 数据模型
关于使用 dbt 管理流式分析管道,还有很多值得探索的地方,因此,如果您有兴趣亲自动手,请查看用于创建上述示例的 示例演示 和 Materialize 文档。