

‧
4 分钟阅读
我们 AI 数据集生成器背后的故事
Matthew Hefferon
‧ 4 分钟阅读
分享本文
在 Metabase,我经常需要虚假数据来演示新功能。我曾在 Kaggle 上寻找,但总感觉缺乏灵感,浪费了大量时间搜索。因此,我构建了一个小工具来帮助我生成数据集,并决定将其开源。
它最终登上了 Hacker News 的首页,在 GitHub 上获得了 600 多个星标,收到了一个 YC 孵化初创公司的贡献,并被 TLDR 时事通讯收录。
为什么不用 Kaggle 或 ChatGPT
如上所述,我一直对 Kaggle 的数据集感到不满意,并不断转向 ChatGPT 来生成虚假数据。我会请求一些东西,得到结果,可视化它,然后发现问题。条形图高度都一样,增长趋势方向错误,变化不够等等。我发现自己陷入了这种循环,于是想……也许有更好的方法。
我实际做了什么
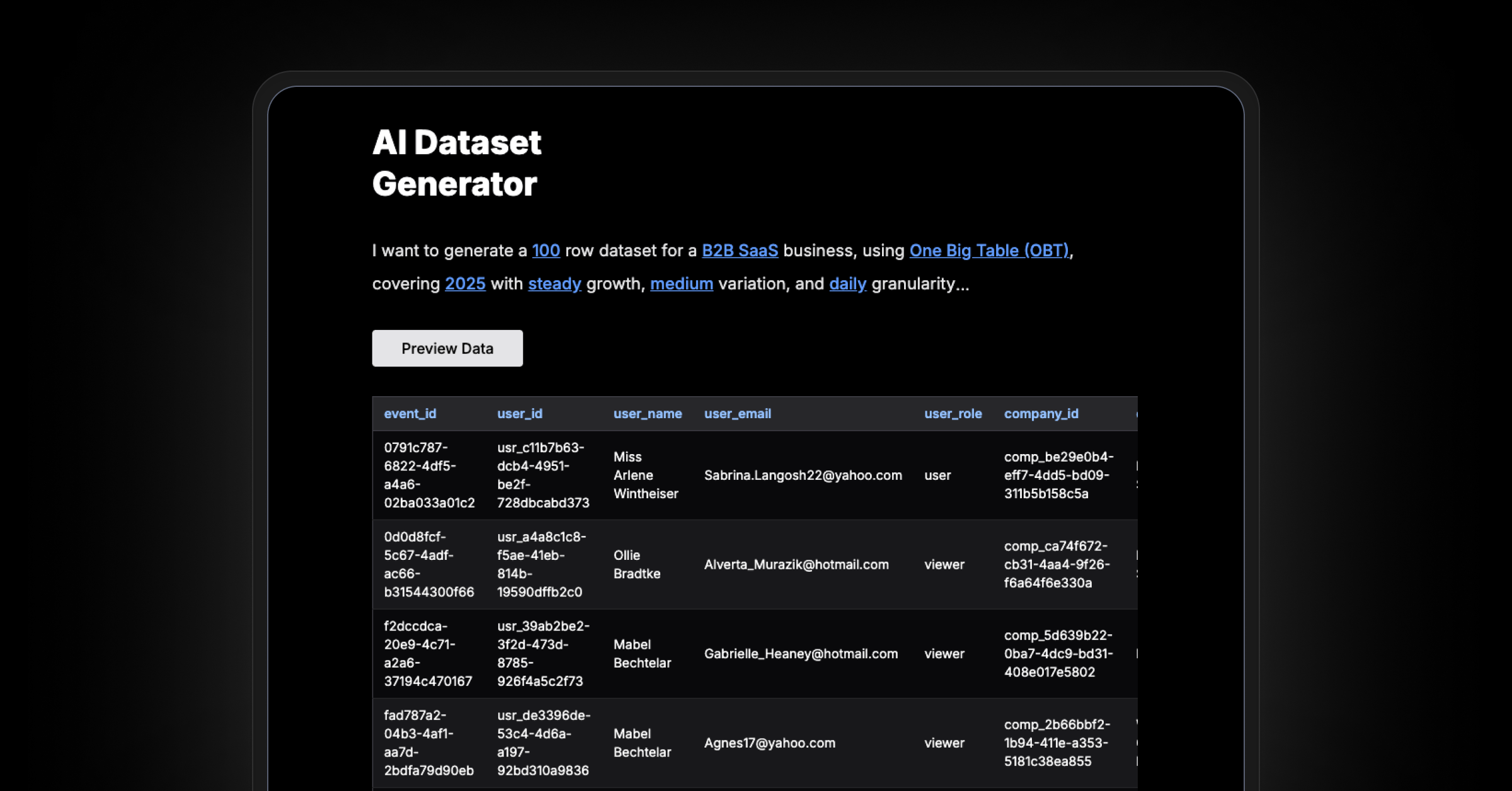
既然我已经写了一些提示词并有了一些经验,我想,为什么不把这个过程变成一个简单的工具呢?所以我把我的提示词输入转换成了几个下拉菜单。
- 业务类型
- 行数
- 单表或多表模式
- 日期范围
- 增长模式
- 变化和粒度
点击“预览数据”,您将获得一个样本模式和 10 行数据。如果看起来不错,您可以将完整数据集导出为 CSV、SQL,或启动 Metabase 进行探索。
工作原理
步骤 1:模式生成是如何工作的
点击“预览数据”时,应用程序通过 LiteLLM 将提示发送到您选择的 LLM 提供商(OpenAI、Anthropic 或 Google)。该提示根据业务类型进行了定制,并返回一个 JSON 规范,定义了表、字段、关系和逻辑。可以将其视为一个可信数据集的蓝图。
最初,我只是用 ChatGPT 生成模式。但在 Hacker News 上有几个人提到切换模型会很酷,我们收到了一个很棒的PR,添加了 LiteLLM 支持,所以现在您可以轻松地在提供商之间切换。感谢@manueltarouca的贡献!
步骤 2:行由 DataFactory 在本地生成
起初,我让 LLM 生成所有行,但即使是 100 行数据,也慢得令人痛苦。我尝试将任务分成批次,但这引入了新问题。例如,用户 ID 在第一个批次中可能是 `001`、`002`、`003`,而在第二个批次中可能是 `u099`、`u100`。
于是我退了一步,与 Cursor 进行了深入讨论。我需要一些快速、更真实、更便宜的运行方式。经过一番来回沟通,我决定构建 DataFactory。它使用Faker.js在本地生成数据,并应用 LLM 返回的模式 + 模拟规则。它还强制执行诸如以下规则:
- 真实的 SaaS 客户流失和定价方案
- 电子商务的子总计、税费和运费能够正确计算
- 医疗索赔中,赔付款永远不会超过诊疗费用
步骤 3:性能和成本
通过将此过程分为两个阶段,该工具保持了快速且出奇的便宜。模式生成是唯一会调用 LLM 的部分,我想确保它不会让我破产。所以我添加了 token 跟踪,并使用一个超级高级的公式计算了数字:
总 token 数 × 每 token 成本 = ???
结果证明……还不错。使用 GPT-4o 时,大多数预览的价格在 $0.03–$0.05 之间。之后,就都是免费的了。没有额外的 API 调用,只有纯粹的、100% 的一级数据。
自己尝试 + 贡献
它仍然处于早期阶段,所以还没有做到万无一失。但如果您需要快速、真实的数据集,不妨试试。所有东西都通过 Docker 在本地运行,您只需要您最喜欢的 LLM 提供商的 API 密钥即可开始。
如果您想贡献,还有很多地方可以参与
- 添加新的业务类型或调整现有类型
- 改进模式逻辑或模拟规则
- 添加您的精彩功能
基础工作已经就绪。如果您有想法,我很乐意您能帮助我将其推向更远。给它点星,fork 它,或者在 GitHub 上提交 PR。

