

SQL 联接类型
学习使用不同 SQL JOIN 类型所需的一切。
本文讨论了不同类型的 SQL JOIN。如果您是该主题的新手,您可能还想查看 SQL JOIN 文章。请注意,JOIN 仅适用于关系数据库。
SQL JOIN 类型快速回顾
SQL JOIN 告诉数据库合并来自不同表的列。我们通常通过将一个表中的 外键 与另一个表中的 主键 进行匹配来 JOIN 表。例如,products 表中的每个记录在 products.id 字段中都有一个唯一的 ID:这就是主键。为了匹配密钥,orders 表中的每个记录在 orders.product_id 字段中都有一个产品 ID:这就是外键。如果我们想将订单信息与所订购产品的相关信息合并,我们可以执行内部 JOIN。
SELECT
orders.total as total,
products.title as title
FROM
orders INNER JOIN products
ON
orders.product_id = products.id
非常重要的是,我们在 JOIN 中使用 Orders.product_id 而不是 Orders.id:这两个字段都只是数字,所以一些订单 ID 会匹配一些产品 ID,但这些匹配将是无意义的。
SQL JOIN 问题的解释
即使我们使用了正确的字段,这里仍然存在一个潜在的陷阱。很容易检查 Orders 中的每个记录都包含一个产品 ID — Orders.product_id 中 NULL 值的计数返回 0。
SELECT
count(*)
FROM
orders
WHERE
orders.product_id IS NULL
| count(*) |
| -------- |
| 0 |
但是,如果情况*并不*总是匹配呢?例如,假设我们正在尝试找出哪些产品没有评论。如果我们查看 reviews 表,它有 1,112 条条目。
SELECT
count(*)
FROM
reviews
| count(*) |
| -------- |
| 1112 |
每条评论都引用了一个产品。
SELECT
count(*)
FROM
reviews
WHERE
reviews.product_id IS NULL
| count(*) |
| -------- |
| 0 |
但是每个产品都有评论吗?要找出答案,让我们计算一下产品的数量。
SELECT
count(*)
FROM
products
| count(*) |
| -------- |
| 200 |
然后,我们可以将 products 和 reviews 表合并,并计算结果中不同产品的数量。(在实际生活中,我们可能会使用 SELECT COUNT(DISTINCT product_id) FROM reviews 来获得这个数字,但使用 INNER JOIN 有助于我们说明这个想法。)
SELECT
count(distinct products.id)
FROM
products INNER JOIN reviews
ON
products.id = reviews.product_id
| count(*) |
| -------- |
| 176 |
200 个产品中只有 176 个有评论。因此,如果我们计算每个产品的评论数量,我们只会得到有评论的数量 — 我们的查询不会告诉我们任何关于缺少评论的产品的信息,因为内部 JOIN 在合并表时找不到任何匹配项。此查询演示了该问题。
SELECT
products.title as title, count(*) as number_of_reviews
FROM
products INNER JOIN reviews
ON
products.id = reviews.product_id
GROUP BY
products.id
ORDER BY
number_of_reviews ASC
| products.title | number_of_reviews |
| ------------------------- | ----------------- |
| Rustic Copper Hat | 1 |
| Incredible Concrete Watch | 1 |
| Practical Aluminum Coat | 1 |
| Awesome Aluminum Table | 1 |
| ... | ... |
我们将结果按计数升序排序;正如所示,最低计数是 1,但它应该是 0。
外部 SQL JOIN 类型来救援
好的:我们知道有多少产品没有评论,但具体是哪些产品呢?回答这个问题的一种方法是使用 SQL JOIN 的类型,称为左外连接(left outer join),也称为“左连接”(left join)。这种 JOIN 类型总是从我们提到的第一个表(即左边的表)返回至少一条记录。要了解它的工作原理,请想象我们有两个小的表,称为 paint 和 fabric。paint 表包含三行。
| brand | color |
| --------- | ----- |
| Premiere | red |
| Premiere | blue |
| Special | blue |
而 fabric 表只包含两行。
| kind | shade |
| ------ | ----- |
| nylon | green |
| cotton | blue |
如果我们对这两个表执行内部 JOIN,匹配 paint.color 到 fabric.shade,只有 blue 记录匹配。
SELECT
*
FROM
paint INNER JOIN fabric
ON
paint.color = fabric.shade
| paint.brand | paint.color | fabric.kind | fabric.shade |
| ----------- | ----------- | ----------- | ------------ |
| Premiere | blue | cotton | blue |
| Special | blue | cotton | blue |
在 fabric 表中没有红色,所以 paint 的第一条记录不包含在结果中。同样,paint 中没有绿色,所以 fabric 的尼龙材料也被丢弃了。
但是,如果我们执行左外连接,数据库将保留左边表中所有没有匹配的记录。由于右边表中没有匹配的值,SQL 会用 NULL 填充这些列。
SELECT
*
FROM
paint LEFT JOIN fabric
ON
paint.color = fabric.shade
| paint.brand | paint.color | fabric.kind | fabric.shade |
| ----------- | ----------- | ----------- | ------------ |
| Premiere | red | NULL | NULL |
| Premiere | blue | cotton | blue |
| Special | blue | cotton | blue |
保留左边表中的所有记录在很多不同的情况下都很有用。例如,如果我们想查看哪些油漆没有匹配的织物,我们可以执行左外 SQL JOIN。
SELECT
*
FROM
paint LEFT OUTER JOIN fabric
ON
paint.color = fabric.shade
| paint.brand | paint.color | fabric.kind | fabric.shade |
| ------------ | ----------- | ------------ | ------------ |
| Premiere | red | NULL | NULL |
| Premiere | blue | cotton | blue |
| Special | blue | cotton | blue |
如果我们只选择右表中的值已填为 NULL 的行,这样更容易阅读。
SELECT
*
FROM
paint LEFT OUTER JOIN fabric
ON
paint.color = fabric.shade
WHERE
fabric.shade IS NULL
| paint.brand | paint.color | fabric.kind | fabric.shade |
| ------------ | ----------- | ------------ | ------------ |
| Premiere | red | NULL | NULL |
我们可以使用这种技术通过执行左外连接并仅保留 reviews.product_id 被填为 NULL 的行来获得没有评论的产品列表。
SELECT
products.title
FROM
products LEFT OUTER JOIN reviews
ON
products.id = reviews.product_id
WHERE
reviews.product_id IS NULL
| products.title |
| ----------------------- |
| Small Marble Shoes |
| Ergonomic Silk Coat |
| Synergistic Steel Chair |
| ... |
右外 SQL JOIN 和全外连接呢?
SQL 标准为外连接定义了另外两种 SQL JOIN 类型,但它们的使用频率要少得多 — 甚至有些数据库根本不实现它们。右外连接(right outer join)的工作方式与左外连接完全相同,只是它始终保留右表中的行,并在左表没有匹配项时用 NULL 填充左表中的列。很容易看出,通过交换表,您总是可以使用左外连接代替右外连接;没有特别的原因偏爱其中一个,但几乎所有人都使用左边形式,所以我们建议您也这样做。
全外连接(full outer join)保留两个表中的所有信息。如果左表中的记录在右表中没有匹配项,数据库将用 NULL 填充缺失的右值;如果右表中的记录在左表中没有匹配项,它将填充缺失的左值。例如,如果我们对 paints 和 fabrics 执行全外连接,我们得到。
| paint.brand | paint.color | fabric.kind | fabric.shade |
| ------------ | ----------- | ------------ | ------------ |
| Premiere | red | NULL | NULL |
| Premiere | blue | cotton | blue |
| NULL | NULL | nylon | green |
| Special | blue | cotton | blue |
全外连接有时对于查找两个表之间的重叠很有用,但在我二十年的 SQL 编写经验中,我只在这样的课程中使用过它们。
选择哪个 SQL JOIN 类型?
回顾一下,有四种基本类型的 JOIN。内部 JOIN 只保留匹配的记录,而其他三种类型用 NULL 填充缺失的值。有些人将左表视为主要表或初始表;您使用的 JOIN 类型将决定您从该初始表返回多少条记录,以及根据您想要的另一个表中的列返回的任何附加记录。我们在这里已经看到了例外(例如,每个产品有多个评论),但这是一个很好的迹象,表明您有一个好的主表可以开始。
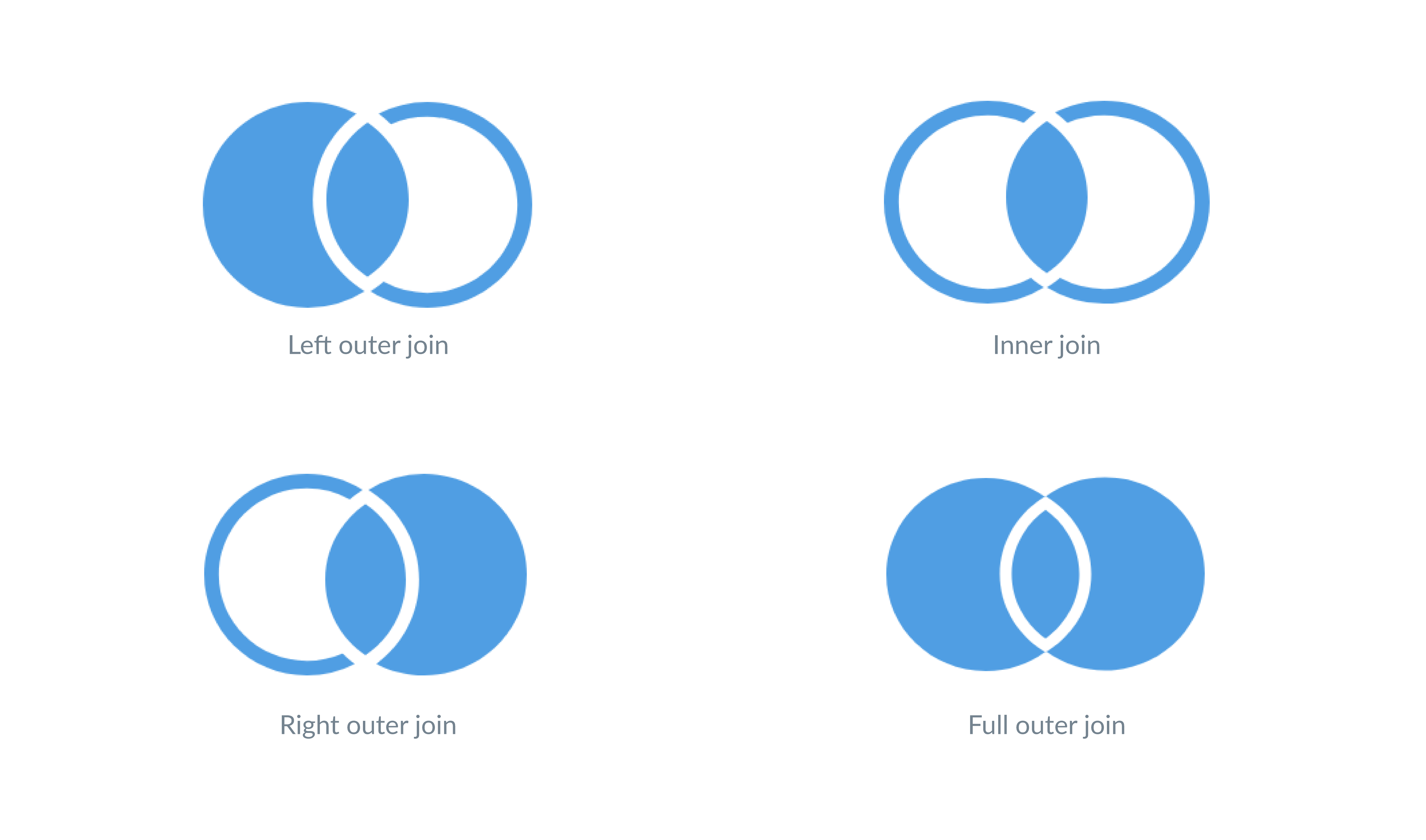
总的来说,您实际上只需要使用内部 JOIN 和左外 JOIN。您使用哪种 JOIN 类型取决于您是否要在结果中包含未匹配的行。
- 如果您需要在主表中包含未匹配的行,请使用左外连接。
- 如果您不需要未匹配的行,请使用内部连接。
有关抽象掉 SQL 的 JOIN 的另一种方法,请查看我们关于使用 Metabase 查询生成器进行 JOIN 的文章。
SQL 连接的常见问题
使用内部 SQL JOIN 而不是外部 JOIN
这可能是最常见的错误。真实数据通常有空白,而内部 JOIN 会在键不匹配时丢弃记录,而不会警告您。计算一个表中*没有*与另一个表匹配的行的数量是一个很好的安全检查;如果存在,您应该考虑使用外部 JOIN 而不是内部 JOIN。
对“无意义的匹配”使用 SQL JOIN
一个人的体重(公斤)和他们上次购买的价值(美元)都是数字,所以可以通过匹配它们来进行 JOIN,但结果(可能)是无意义的。一个不太琐碎的例子是,当一个表包含指向不同表的多个外键时,这可能导致将患者数据与车辆注册信息而不是就诊日期进行 JOIN。在表中声明外键有助于防止这种情况。
混淆数据中的 NULL 值和不匹配产生的 NULL 值
如果外部 JOIN 中的一个表包含 NULL,我们可能会得到一个列,其值由于原始数据中不存在以及由于不匹配而丢失。根据我们试图解决的问题,这些不同“风味”的 NULL 可能很重要。