

ETL、ELT 和反向 ETL
如何将数据从多个来源引入数据仓库,然后通过将您的洞察推送到可以使用的地方来操作这些数据。
我们将广泛地讨论如何将您收集的所有数据放到可以利用它的位置。这里的想法是为您提供一些词汇和对这个 ELT 字母汤的基本认识。
具体来说,我们将讨论数据的提取、转换和加载。随着组织的增长,您将添加更多数据源,虽然您可以孤立地分析这些数据孤岛(例如报告收入),但最终您将希望整合这些数据并将其放在一个可以基于它做出决策的地方。
我们将从一个问题开始,如何将您的数据整合到易于提问的结构中(ETL),然后讨论如何利用您得到的答案(反向 ETL),并在过程中深入探讨所涉及的工具。
提取、转换、加载
首先,我们先绕道定义术语并区分 ELT 和 ETL。总体而言,这些术语指的是为数据仓库或数据超市中的分析准备数据,但具体来说,这些字母代表:
- 提取:从您的应用程序和其他服务中获取数据。
- 转换:清理、过滤、格式化、聚合、组合、丰富,并总体上组织数据,以便更容易地在数据库中创建模型(例如对客户进行建模)。
- 加载:将数据存储在数据仓库中(或在反向 ETL 的情况下,将其推送到第三方服务)。
ETL 与 ELT
为了复杂化,当人们说 ETL 时,他们通常指的是 ETL 或 ELT,或两者兼而有之。这些首字母缩略词(您逐个字母发音;它是 E.T.L.,而不是“ettle”)指的是将数据从源头获取、对其进行处理,然后存储在某处以便人们查询的通用过程。ETL 和 ELT 的关键区别在于,ETL 中的数据转换步骤发生在数据仓库的*外部*。
历史上,您会使用一个工具,例如 Informatica,来提取、转换和加载数据到您的数据仓库,但随着世界向 ELT 范式发展,您将看到更多专门用于该过程各个部分的工具。
典型的 ETL 管道
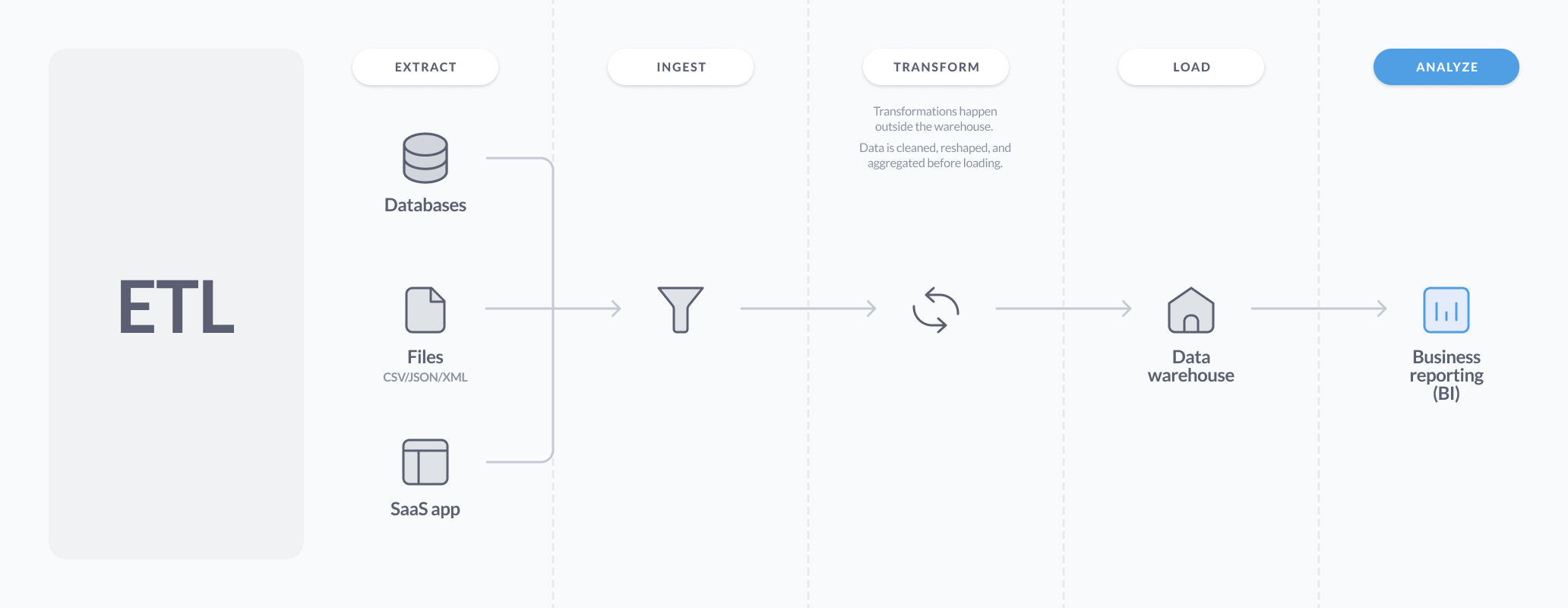
数据源 -> 分布式处理软件,如 Hadoop、Spark 或 Informatica -> 数据仓库,如 Redshift、BigQuery 或 Snowflake。
在服务器集群上运行的 Hadoop、Spark 或 Informatica 作业在将数据加载到数据仓库之前,会对数据进行清理、丰富、聚合和其他组织。
典型的 ELT 管道
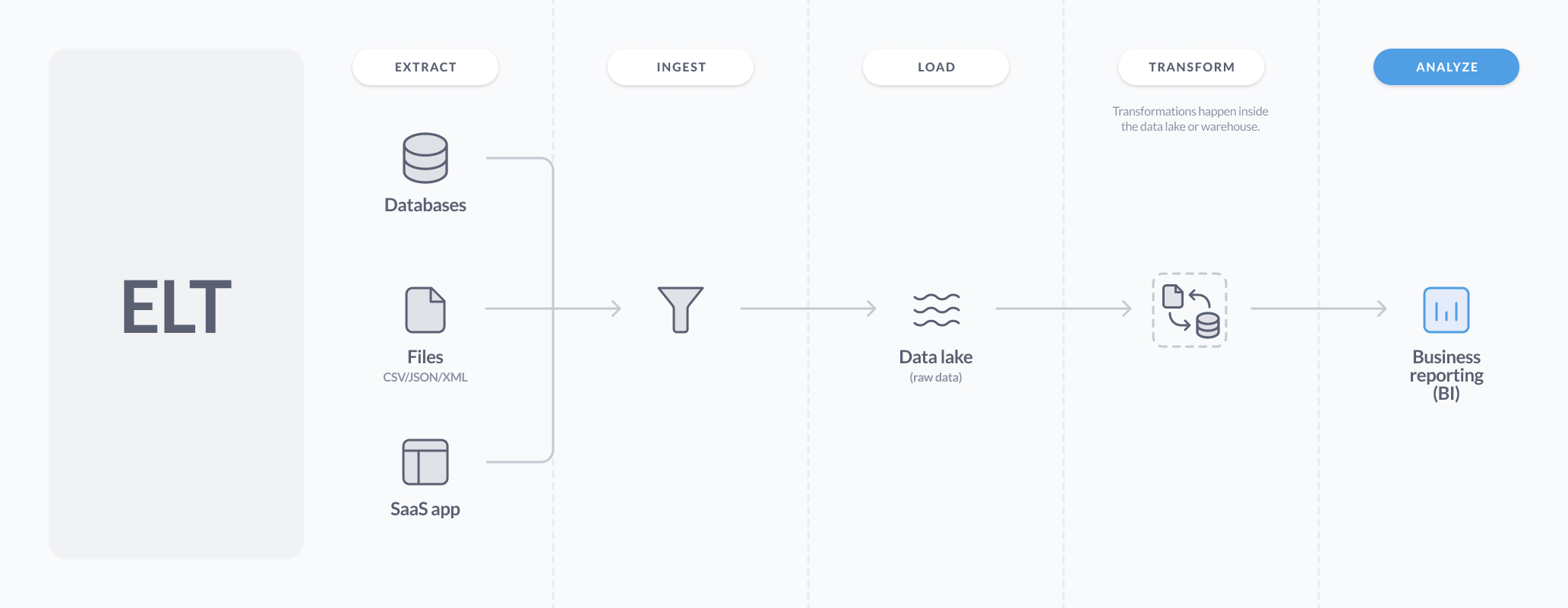
数据源 -> 提取工具,如 Fivetran -> 数据仓库(Redshift、BigQuery、Snowflake)-> 在数据仓库中使用 DBT 等软件定义的转换作业并安排其运行。
随着数据仓库技术的改进,越来越多的人只是提取数据并将那些原始的、未经转换的数据加载到数据仓库中。一旦进入数据仓库,他们就会对其进行转换,将原始数据组织成更易于分析的表:例如,收集记录的事实表,以及收集聚合的汇总表。
总的来说,世界正朝着 ELT 方法发展,主要有三个原因:
- 数据仓库技术已经改进;它们现在可以处理传统上由 Hadoop 集群等完成的计算工作。
- 您还可以将原始数据保存在数据仓库中,这使得您将来可以进行不同的转换来回答有关数据的新问题。
- 数据仓库的成本也大大降低了(这很好)。
何时倾向于 ETL
尽管如此,ETL 仍然有很好的用例(Metabase 公司同时使用这两种方法)。当您*
- 您有特别复杂的数据转换(有时称为转换),
- 或者您想在将数据加载到数据仓库之前对其运行机器学习,
- 或者您需要更改数据的格式以满足数据库的规范。
从 ETL 到反向 ETL 的数据流示例
为了简单起见,我们假设您只从三个来源收集数据:
现在,假设您想知道*客户支持如何影响留存*。要分析这种影响,您需要查看 Stripe 的订阅数据,并将其与 Zendesk 的支持数据进行比较。
提取数据
虽然您可以自己构建用于提取数据的工具,但通常您会想要使用一项服务来处理这些复杂性(例如,维护每个 API、调度作业、处理错误等)。
在评估提取工具时,您需要寻找那些*
- 拥有您所需的所有连接器。并且一旦您选择了某个工具,在评估其他相关工具时,请务必考虑其连接器库。例如,如果您选择 Fivetran,并且稍后发现自己正在寻找一个电子邮件营销平台,请考虑选择 Fivetran 支持的平台。
- 可以增量提取数据(而不是简单的批量处理)。您可能不需要实时数据,但您可能希望在几分钟内而不是每天一次获得更新。
- 不更改数据,或至少不大幅更改。您应该负责转换数据,而不是提取服务。
这个领域有很多选择:Airbyte、Peliqan、Fivetran、Segment、Singer 和 Stitch。
将数据加载到数据仓库
在此上下文中,“加载”仅仅意味着您正在将数据放入存储(有时称为“sink”)。这个数据存储可以是一个标准的事务数据库,如 PostgreSQL 或 MySQL,一个简单的文件系统,如 S3 配合查询引擎,如 Presto,或者一个针对分析查询优化的数据仓库,如 BigQuery、Redshift 或 Snowflake。
数据仓库的概述超出了本文的范围,因此我们只引用 您应该使用哪个数据仓库?。对于本文,您可以更广泛地(理想情况下)将数据仓库视为您的真相来源。
转换数据
有许多不同的方法可以清理、过滤、格式化、丰富或以其他方式转换您的数据,包括将其与其他数据合并。您还可以汇总数据,例如确定过程的开始和停止时间以计算其持续时间。
在 ELT 世界中,您将需要一个与您的数据仓库配合使用的工具,该工具可以接收原始数据、对其进行转换,然后将转换后的数据插入到数据仓库中的其他表中。这样,您就可以在同一个数据仓库中保留从各种来源提取的原始数据以及这些经过清理、可用于建模和分析的数据。
在评估转换数据的工具时,您将需要*
- 将 SQL 作为其主要语言。坚持一种语言更简单,并且大多数数据库都理解 SQL。
- 允许您对 SQL 进行版本控制。如果您更改了查询并且数据看起来不正确,您将需要回滚到该查询的先前版本以找出哪里出了问题。
- 可以测试您的代码,例如,以确认输出中的所有 ID 都是唯一的。
- 允许您记录这些作业,最好捕获字段数据和血缘(这样您就知道数据来自哪里)。
现在您对数据有了深入的了解,如何利用它呢?
回到我们关于客户支持是否能改善留存的例子。假设您了解到,在客户年度订阅的最后九十天内关闭支持工单可以将留存率提高显著的百分比。那么您需要做的是在 Zendesk 中标记出那些即将续订的客户提交的帮助工单,并且可能在他们的续订日期临近时主动联系他们,看看是否可以帮助他们最大化利用您的服务。
有几种方法可以将此洞察集成到您的帮助支持系统中:
- 您可以手动运行报告,查看哪些公司即将续订,然后在 Zendesk 中添加一个显示客户是否为
UP_FOR_RENEWAL的列,并优先处理这些工单。 - 构建一个自定义工具,每晚运行一次,然后使用 Zendesk 的 API 更新 Zendesk 中的列。
- 使用 Zapier 等工具协调 Stripe 和 Zendesk 之间的数据。
- 使用 Census 等工具将此数据点从数据仓库推送到相关应用程序(在本例中为 Zendesk)。
反向 ETL,或数据操作
典型的反向 ETL 管道
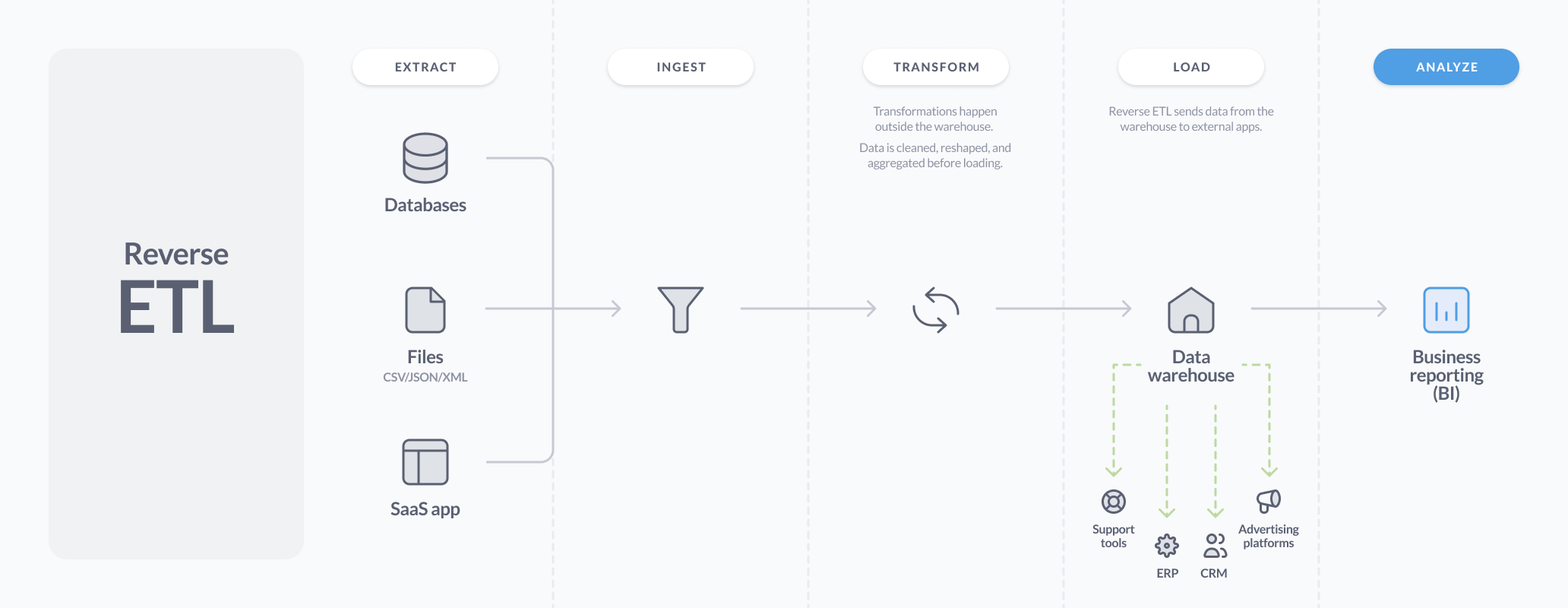
反向 ETL 是将已经清理并组织好的数据从数据仓库发送到您的团队使用的工具——如 Salesforce、Zendesk 或营销平台——以便他们在日常工作中可以使用这些数据的过程。
数据可以通过两种主要方式从数据仓库推送到其他工具:一种是通过监听应用程序中的事件并更新其他应用程序以保持同步,另一种是通过将数据直接从单个真相来源推送到相关应用程序。
我们强烈推荐单点真相来源的方法,因为它大大降低了使应用程序与所需数据保持同步的复杂性。而像 Zapier 这样的工具需要努力才能使您的各种应用程序保持同步,像 Census 这样的工具只是定期从您的数据仓库读取数据,并将更新推送到需要的地方。
这里的核心思想是,静态数据比需要协调的数据更容易维护。随着您的组织不断壮大,您将使用更多服务,这需要更多的协调。Census 所采取的单点真相来源方法可以规避这种协调挑战,当您试图处理复杂的逻辑时,它会远远领先。
假设您了解到,留存效果在公司处于九十天窗口期内,*并且*他们每年支付的费用高于 X 金额,*并且*他们位于三个地理区域之一,*并且*他们在过去一年中提交了 X 数量的工单,等等。使用 Zapier,您将不得不与其他应用程序进行协调,以同步过滤您希望您的客户成功团队优先处理的客户所需的数据。使用 Census(它可以运行 DBT 作业来计算数据点),您只需要查询数据仓库,并将查询结果推送到帮助支持软件。如果您想将大量数据插入到像 Tensor Flow 分类器这样的东西,并让它直接吐出分类器认为您应该优先处理哪些客户,情况也是如此。
从这个意义上说,“反向 ETL”这个术语有点误导,因为 Census 并没有转换数据;它只是从数据仓库读取数据,并告知其他应用程序它们需要知道什么;在这种情况下,是哪些客户您的成功团队应该优先处理。
延伸阅读
有关数据如何在组织中流动的概述,请查看我们关于现代数据堆栈的文章。