

加快仪表盘的速度
如何让仪表板加载更快。
在仪表板性能方面,实际上只有四种方法可以使仪表板加载更快
- 要求的数据更少.
- 缓存问题的答案.
- 组织数据以预见常见问题.
- 提出高效的问题。
以下是有关如何使仪表板加载更快的通用指南。大部分指导将侧重于第三点,即如何组织数据以预见数据将用于回答的最常见问题。
过早优化是万恶之源的通常警告仍然适用。我们的建议假定您已经探索数据一段时间,并从数据产生的洞察中获得了实质性收益。只有到那时,您才应该问:“我如何才能让这个仪表板加载得更快?”
要求的数据更少
这一点几乎太明显了,以至于经常被忽视,但它应该是您首先要考虑的地方。您真的需要查询的数据吗?即使您确实需要所有这些数据,您需要它的频率有多高?
您可以通过限制查询的数据来节省大量时间,例如在仪表板上添加 默认筛选器。特别要注意跨越时间和空间的数据:您真的需要每天查看上个季度的数据吗?或者您真的需要每个国家的每一笔交易吗?
即使您确实需要这些信息,您每天都需要它们吗?您可以将该问题移至通常只每周或每月查看一次的另一个仪表板吗?
在探索数据集时,我们应该对所有数据持开放态度,但一旦我们确定了组织需要做出的决策类型——以及为这些决策提供信息所需的数据——我们就应该坚决排除那些不能显著改进我们分析的数据。
缓存问题的答案
如果数据已经加载,您就不需要等待。管理员可以设置 Metabase 来 缓存查询结果,这将存储问题的答案。如果您有一组仪表板,每个人在早上打开电脑时都会运行,请提前运行该仪表板,这样仪表板中的问题将在后续运行中使用保存的结果,从而在几秒钟内加载。人们可以选择刷新数据,但这通常是不必要的,因为大多数时候人们只需要查看前一天及之前的数据。
管理员可以在“**管理面板**”的“**性能**”选项卡中配置缓存规则。您可以选择缓存数小时,使用设定的时间表使缓存失效,或者使用查询的平均执行时间来确定缓存其结果的时长。
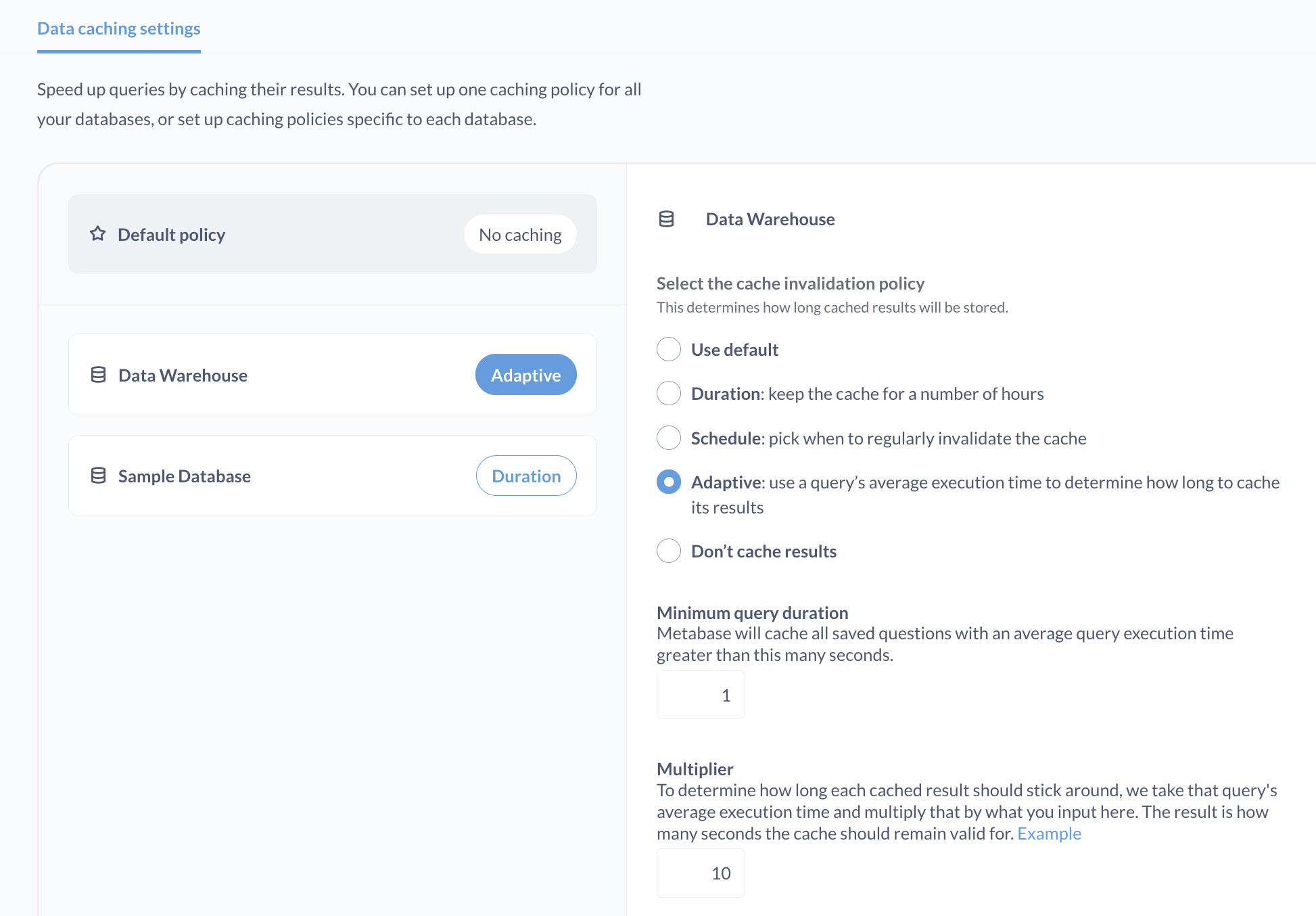
在 Pro 和 Enterprise 套餐 中,您还可以设置特定于单个仪表板和问题的缓存策略。
您可以使用 Metabase 的 使用情况分析 来确定人们通常在何时运行各种问题,然后使用 Metabase 的 API 创建一个脚本,以编程方式提前运行这些问题(从而缓存其结果)。这样,当人们登录并导航到他们的仪表板时,结果将在几秒钟内加载。即使不采取额外的“预热”步骤,当您的第一个人加载那个慢速查询时,它也会为您的其他人缓存。
组织数据以预见常见问题
您可以做的下一个最好的事情是组织您的数据,以预见将要提出的问题,这将使您的数据库更容易检索该数据。
- 索引经常查询的列.
- 复制您的数据库.
- 反规范化数据.
- 物化视图:创建新表来存储查询结果.
- 通过汇总表提前汇总数据.
- 将数据从 JSON 中提取出来,并将其键映射到列中.
- 考虑使用专门用于分析的数据库.
除下文最后一节外,其余内容都假定您正在使用 PostgreSQL 或 MySQL 等传统关系型数据库。最后一节是关于迁移到一种完全不同类型的数据库,该数据库专门用于处理分析,应该是您的最后选择,尤其是对于初创公司。
索引经常查询的列
向数据库添加索引可以显著提高查询性能。但就像给一本书的每一页都添加索引没有意义一样,索引会产生一些开销,因此应该策略性地使用它们。
如何策略性地使用索引?找到您查询最多的表,以及这些表中查询最多的列。您可以查阅您的个人数据库来获取此元数据。例如,PostgreSQL 通过其 pg_stat_statements 模块提供关于查询数量和性能的元数据。
记住做一些简单的工作,询问您的 Metabase 用户哪些问题和仪表板对他们很重要,以及他们是否也遇到了任何“慢速”问题。最常需要索引的字段是基于时间的或基于 ID 的——例如事件数据上的时间戳,或分类数据上的 ID。
或者,在 Pro 和 Enterprise 套餐 中,您可以使用 Metabase 的 使用情况分析,它使您可以轻松地看到谁在运行哪些查询、多久运行一次以及这些查询花费了多长时间返回记录。
一旦确定了您要索引的表和列,请查阅数据库的文档以了解如何设置索引(例如,这里是 PostgreSQL 中的 索引)。
索引很容易设置(和删除)。这是 `CREATE INDEX` 语句的基本格式。
CREATE INDEX index_name ON table_name (column_name)
例如
CREATE INDEX orders_id_index ON orders (id)
尝试通过索引来查看如何提高查询性能。如果您的用户经常在单个表上使用多个过滤器,请研究使用复合索引。
复制您的数据库
如果您正在使用一个数据库来处理操作(例如,应用程序事务,如下单、更新个人资料信息等)以及分析(例如,用于驱动 Metabase 仪表板的查询),请考虑创建一个生产数据库的副本,用作仅用于分析的数据库。将 Metabase 连接到该副本,每晚更新该副本,然后让您的分析师进行查询。分析师的长期运行查询不会干扰您生产数据库的日常运营,反之亦然。
除了让您的仪表板运行得更快之外,为数据分析保留一个副本数据库也是避免潜在的长期运行分析查询影响您的生产环境的一个好习惯。
反规范化数据
在某些情况下,将一些表 反规范化(即,将多个表合并成一个具有更多列的大表)可能是有意义的。您最终会存储一些冗余数据(例如,每次用户下订单时都包含用户信息),但分析师不必连接多个表来获取他们回答问题所需的数据。
物化视图:创建新表来存储查询结果
通过 物化视图,您可以将您的原始、反规范化数据保留在它们的表中,并创建新表(通常在非工作时间)来存储查询结果,这些结果以一种预见分析师将提出的问题的方式组合了来自多个表的数据。
例如,您可能将订单和产品信息存储在不同的表中。您可以在每晚一次创建(或更新)一个物化视图,该视图组合了这两个表中查询最多的列,并将该物化视图连接到 Metabase 中的问题。如果您同时将数据库用于生产和分析,除了消除组合这些数据所需的连接过程之外,您的查询也不必与这些表上的生产读写竞争。
物化视图和 通用表表达式(CTE,有时称为视图)的区别在于,物化视图将其结果存储在数据库中(因此可以进行索引)。CTE 本质上是子查询,并且每次都会被计算。它们可能会被缓存,但它们不会存储在数据库中。
但是,物化视图会消耗您数据库中的资源,并且您必须手动更新视图(`refresh materialized view [name]`)。
通过汇总表提前汇总数据
这里的想法是使用物化视图——甚至是一组单独的表——来创建 汇总表,以最小化计算。假设您有包含一百万行的表,并且您想聚合多个列中的数据。您可以创建一个基于一个或多个表聚合的物化视图,该视图将执行初始(耗时的)计算。与其让仪表板在一天的不同时间查询和计算原始数据,不如创建查询该汇总表的问答,以获取在前一天计算出的数据。
例如,您可以有一个包含所有订单的 orders 表,以及一个 nightly 更新并存储汇总和其它聚合数据的 order summary 表,例如每周、每月的订单总额等。如果一个人想查看用于计算该汇总的单个订单,您可以使用 自定义目标 来链接用户到一个 *确实* 查询原始数据的问答或仪表板。
将数据从 JSON 中提取出来,并将其键映射到列中
我们经常看到组织将 JSON 对象存储在像 MySQL 或 PostgreSQL 这样的关系型数据库的单个列中。通常,这些组织存储来自事件分析软件(如 Segment 或 Amplitude)的 JSON 有效负载。
尽管某些数据库可以索引 JSON(例如,PostgreSQL 可以索引 JSON 二进制文件),但即使您只对对象中的单个键值对感兴趣,您仍然需要每次都获取完整的 JSON 对象。相反,考虑将这些 JSON 对象中的每个字段提取出来,并将这些键映射到表中的列。
考虑使用为分析优化的数据库
如果您已经完成了以上所有操作,并且仪表板加载时间仍然干扰您及时做出决策的能力,您应该考虑使用一个专门为处理分析查询而设计的数据库。这些数据库被称为在线分析处理(OLAP)数据库(有时称为数据仓库)。
PostgreSQL 和 MySQL 等传统关系型数据库是为事务处理而设计的,它们被归类为在线事务处理(OLTP)数据库。这些数据库更适合用作操作型数据库,例如存储 Web 或移动应用程序的数据。它们非常擅长处理以下场景:有人向您的网站提交了一个深思熟虑、相关且一点也不煽动性的评论,您的应用程序会向您的后端发出一个 POST 请求,该请求会将评论和元数据路由到您的数据库进行存储。OLTP 数据库可以处理大量的并发事务,如评论发布、购物车结账、个人资料生物更新等。
OLAP 和 OLTP 系统之间的主要区别在于,OLAP 数据库针对大量数据的分析查询(如求和、聚合和其他分析操作)以及批量导入(通过 ETL)进行了优化,而 OLTP 数据库必须平衡数据库的大量读取与其他事务类型:小的插入、更新和删除。
OLAP 通常使用 列式存储。而传统的(OLTP)关系型数据库按行存储数据,使用列式存储的数据库(不出所料)按列存储数据。这种列式存储策略在读取数据方面为 OLAP 数据库提供了优势,因为查询不必筛选不相关的行。这些数据库中的数据通常组织在 事实 表和 维度 表中,其中(通常巨大的)事实表存储事件。每个事件包含一个属性列表和指向维度表的外部键引用,维度表包含有关这些事件的信息:谁参与了、发生了什么、产品信息等。
Metabase 支持几种流行的数据仓库:Google BigQuery、Amazon Redshift、Snowflake 和 Apache Druid(专门从事实时分析)。Metabase 还支持 Presto,它是一个查询引擎,可以与各种不同的数据存储配对,包括 Amazon S3。
当您开始使用 Metabase 时,不必过于担心底层数据存储。但随着您的数据量和 Metabase 的 采用量 的增长,请留意您可能需要考虑使用数据仓库的迹象。例如,Redshift 可以查询 PB 级数据,并可以扩展到查询 Amazon S3 中的历史数据。Snowflake 允许您随着组织的发展动态扩展计算资源。
延伸阅读
有关改进性能的更多技巧,请参阅我们关于 扩展 Metabase 和 SQL 查询最佳实践 的文章。
如果您改进了您组织的仪表板性能,您可以在 我们的论坛 上分享您的技巧。