

如何在生产环境中运行 Metabase
如果您正在自托管 Metabase,以下是一些基准测试和最佳实践。
本文介绍了生产就绪的 Metabase 设置,包括服务器规模、最佳实践和需要避免的陷阱。本文面向希望自托管 Metabase 的用户。如果您希望我们为您运行 Metabase,请注册免费试用。
Metabase JAR 文件包含什么
作为背景,Metabase 是一个 Web 应用程序。其后端是用 Clojure 编写的,前端使用 React 框架,用 JavaScript、TypeScript 和 ClojureScript 编写。
默认情况下,整个应用程序是自包含的:后端和提供前端的 Web 服务器打包在同一个捆绑包中。这个捆绑包是一个 JAR 文件,可以在安装了 Java 运行时环境的任何地方运行。
Metabase 还提供了一个容器镜像,其中打包了 JRE 和 Metabase JAR(您也可以使用 Podman 运行它)。
一个 JAR 文件和一个数据库是您需要的所有东西
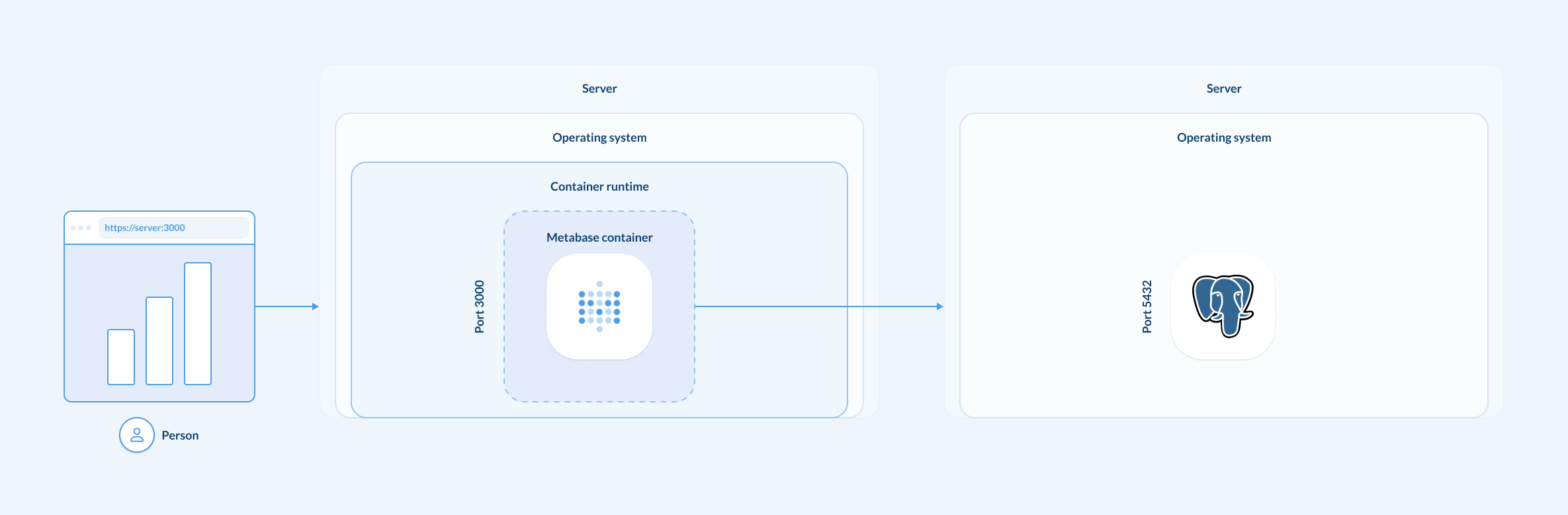
要在生产环境中运行 Metabase,您需要两样东西:
- Metabase JAR 文件或容器镜像。
- 一个专用的 PostgreSQL 数据库,用于存储 Metabase 的应用程序数据库。
您也可以使用 MySQL/MariaDB 来存储 Metabase 的应用程序数据库,但我们强烈推荐使用 Postgres。
为什么您需要使用单独的应用程序数据库
Metabase 将其所有实体(仪表板、问题、账户、配置)保存在其应用程序数据库中。
如果您坚持使用默认的文件型应用程序数据库,您的数据库最终将无法恢复地损坏,您将不得不从头开始(在丢失所有工作之后:您所有的问题、仪表板等)**。
因此,您最应该避免做的事情是使用 Metabase JAR 附带的默认应用程序数据库。那个嵌入式数据库仅用于本地使用。我们包含这个嵌入式数据库是为了方便那些只想在自己的机器上试用 Metabase 的人。那个嵌入式 H2 数据库还包含一些样本数据供人们玩耍。它不适合生产环境。
同样,如果您在容器中运行 Metabase,当您的容器被新版本替换时,您将丢失所有工作。容器旨在短暂使用,所以不要在其中保留您的数据。
您可以通过使用专用的 PostgreSQL 应用程序数据库来避免所有这些问题。
如果您已经开始使用默认的 H2 数据库
没关系。但您应该尽快迁移到生产数据库。
Metabase 应用程序和数据库服务器及其规模
我们建议您至少运行两个实例(最好在同一网络上)
- 一个或多个 Metabase 应用程序实例.
- 一个用于存储 Metabase 应用程序数据的 Postgres 或 MySQL 数据库实例。我们建议该数据库实例不用于任何其他目的,仅用于 Metabase 应用程序数据库。
之所以希望在同一网络上运行这些实例,是为了减少 Metabase(应用程序)从存储其应用程序数据的数据库接收响应所需的时间。绝大多数 Metabase 操作都需要调用 Metabase 的 API,该 API 使用应用程序数据库来检索有关问题、仪表板、表元数据等信息。
Metabase 应用程序服务器规模
Metabase 的最低要求是 1 个核心和 1GB 内存。在此基础上,每 20 个并发用户,Metabase 将需要 1 个 CPU 和 2GB 内存。这些系统建议适用于您将 Metabase 作为 JAR 或容器镜像运行。例如,如果您有 40 个并发用户,您将总共需要 3 个 CPU 核心和 5GB 内存。
注意:在 v52 版本之前,我们每 20 个并发用户仅建议 1GB 内存,但在更新版本中,我们将此要求提高,以确保安全。
Metabase 应用程序数据库服务器规模
应用程序数据库可能是整个架构中最关键的组件:它是单点故障,应用程序数据库返回查询到 Metabase 应用程序服务器的速度越快越好。作为起点,为运行应用程序数据库的服务器分配 1 个 CPU 核心和 2GB 内存。通常来说,每 40 个并发用户,PostgreSQL 应用程序数据库将需要 1 个 CPU 核心和 1 GB 内存。
每个 Metabase 环境都必须拥有自己的专用应用程序数据库
这里的环境指的是一个或多个 Metabase JAR(或容器镜像),以及一个应用程序数据库。如果您运行多个环境,您可以在同一应用程序数据库服务器上为每个环境运行多个应用程序数据库,但每个环境必须有自己的专用应用程序数据库。
维护
保持顺畅运行。
Metabase 服务器维护
您无需执行任何操作。它应该可以正常工作。
Metabase 应用程序数据库维护
所有数据库都需要维护以获得最佳性能,PostgreSQL 和 MySQL 也不例外。请遵循 PostgreSQL 的维护最佳实践(https://postgresql.ac.cn/docs/current/maintenance.html)(特别是备份)。
此应用程序数据库应
- 每天备份。
- 每周进行一次 VACUUM 和 ANALYZE。
此外,不再需要的卡片和仪表板应定期存档和删除。
数据仓库服务器维护
您的数据仓库的维护取决于您使用的数据仓库。请参阅数据库文档以获取指导。
负载测试示例
在此简单的负载测试中,Metabase API 在 K6 上记录了以下指标。
- 红色:性能较差
- 绿色:性能良好
| 指标 / 系统 | 2 核 / 2GB 内存 | 3 核 / 3GB 内存 | 4 核 / 4GB 内存 | 8 核 / 8GB 内存 | 16 核 / 16GB 内存 |
|---|---|---|---|---|---|
| 总请求处理量 处理成功的 Web 请求总数 |
278,303 | 303,420 | 311,740 | 311,350 | 313,625 |
| 每秒请求数 系统每秒可处理的请求数(越高越好) |
121.3 req/s | 132.0 req/s | 136.2 req/s | 135.8 req/s | 136.1 req/s |
| 平均响应时间 获得响应的平均时间(越低越好) |
78.59ms | 38.89ms | 26.82ms | 27.45ms | 24.46ms |
| 最慢 10% (p90) 最慢 10% 的请求耗时至少这么长 |
204.97ms | 88.58ms | 66.00ms | 66.73ms | 65.78ms |
| 最慢 5% (p95) 最慢 5% 的请求耗时比这更长 |
389.85ms | 118.88ms | 81.79ms | 83.01ms | 76.72ms |
| 接收数据时间 发送请求后接收数据的时间 |
6.16ms | 2.54ms | 1.56ms | 1.52ms | 1.62ms |
| 发送数据时间 发送请求到服务器的时间(通常非常快) |
16.74µs | 17.46µs | 15.07µs | 16.04µs | 17.79µs |
| 等待响应时间 发送请求和获得响应之间的延迟 |
72.41ms | 36.32ms | 25.24ms | 25.90ms | 22.82ms |
| 每次迭代测试时长 一次测试迭代完成的总时间 |
30.92s | 28.36s | 27.57s | 27.62s | 27.42s |
| 总迭代次数 测试完全完成的次数 |
4,273 | 4,666 | 4,796 | 4,790 | 4,825 |
| 总接收数据量 测试期间下载的数据量 |
16GB | 17GB | 17GB | 17GB | 17GB |
| 总发送数据量 测试期间上传的数据量 |
103MB | 112MB | 115MB | 115MB | 116MB |
负载测试背景信息
- 此负载测试运行的是 Metabase v53.5 版本,在一台笔记本电脑(Ryzen 7840HS)上进行,改变分配给 Metabase 容器的 CPU 核心和 RAM,并设置了最高的电源配置文件。
- 为了给非堆内存留出空间,我们使用环境变量
JAVA_TOOL_OPTIONS: -Xmx<80% of total RAM>m配置 Metabase。 - 应用程序数据库是 PostgreSQL 版本 17,拥有 2 个核心和 8GB 内存。
- 无 HTTPS。
- 我们进行的这个特定负载测试使用的资源比我们建议的要少(对于 100 个并发用户,我们会推荐 6 个核心和 11GB 内存)。我们特意使用较少资源是为了展示,当有足够的 CPU 核心和内存可用时,应用程序可以承受流量高峰而不会显著降低性能。
- 尽管此负载测试检查了多个 API 端点,但它 *没有* 测试 CPU/内存密集型操作,例如 X-Rays,或异步操作,例如订阅、警报、数据库同步或数据库扫描/指纹识别。
然而,负载测试无法模拟真实使用情况。用户在 Metabase 中的活动将产生各种不同的 API 调用模式。您还将有后台运行的异步进程。如果 Metabase 缺乏足够的 CPU 资源,它将排队等待操作并开始消耗更多内存。如果队列溢出,Metabase 可能会在试图处理所有请求时崩溃。在这种情况下,您需要分配更多的核心和更多的内存。
异步进程
Metabase 将定期运行异步进程,这些进程将根据表的数量和表的列数使用 CPU 和 RAM。
这些进程包括
- 同步 (sync)
- 扫描 (scan)
- 指纹识别 (fingerprinting)
- 字段值 (field values)
- 模型缓存 (model caching)
- 问题元数据 (question metadata)
如果您发现 Metabase 在某个时间段内使用了大量 CPU,请检查日志以了解 Metabase 是否正在运行这些进程。如果是,您可以安排这些任务在 Metabase 用户不使用时运行。
Metabase 将每个任务分配给一个核心。如果您的服务器有四个核心,Metabase 将运行的最大异步进程数为三个,因为一个核心应该用于服务用户请求(一个核心应该能够服务约 10 位并发 Metabase 用户)。
可观测性和一些需要监控的指标
Metabase 公开了一个可供 Prometheus 抓取的指标端点。理想情况下,您应该设置一些警报,以便在任何这些数字超过阈值时采取行动。
Metabase 应用程序
- API 响应时间
- CPU:80%-90% 最大值
- RAM:80% 最大值
Metabase 应用程序数据库
- CPU:90% 最大值
- RAM:80% 最大值
- 磁盘使用率:80% 最大值。
- 磁盘 IOPS:检查您的磁盘 IOPS 支持。如果您使用的磁盘运行您的应用程序数据库超过了磁盘声称支持的 IOPS,那么您的磁盘将排队等待操作,这将影响性能。
何时增加连接池大小
默认情况下,Metabase 的连接池大小限制为 15 个连接。Metabase 将为每个连接的数据库管理一个池,包括一个应用程序数据库的池,每个池限制为 15 个连接。
为了处理更多并发使用 Metabase 的用户,您可以使用环境变量 MB_APPLICATION_DB_MAX_CONNECTION_POOL_SIZE 来覆盖到应用程序数据库的连接限制。如果您增加了此限制,您可能需要为您的应用程序数据库分配更多 RAM,因此您应该监控您的应用程序数据库的 RAM 使用情况。如果数据库缺乏可用 RAM,数据库将排队等待连接,这意味着一些用户会在 Metabase 等待 RAM 释放时发现 Metabase 无响应。
Metabase 只使用它在任何给定时间需要的连接。但某些请求可能会占用许多这些连接。例如,如果有人加载一个包含 20 个卡片的仪表板,Metabase 将使用其 15 个可用连接来检索结果,并在连接可用时加载剩余的五个卡片。
自动健康检查
大多数部署和编排平台,如 Docker、Kubernetes、Google Cloud Run、Amazon ECS 等,都可以自动检查 Metabase 实例的健康状况。这样,有故障的实例可以自动重启,或者繁忙的实例可以暂时从负载均衡器中移除,让它们完成工作而不会过载。
健康检查,也称为探针,对于任何分布式应用程序的可用性都至关重要,Metabase 也不例外。
Metabase 通过 HTTP 公开健康检查端点。当检查成功时,这些端点都响应 200 状态码和以下 JSON 有效负载。
{"status": "ok"}
单一健康检查
某些平台(如 Docker Compose、Docker Swarm 和 Amazon ECS)仅支持一种健康检查。在这种情况下,请使用 GET /api/health 端点,它会检查 Metabase 及其与应用程序数据库的连接健康状况。
请注意,根据您的平台,将 GET /api/health 用作唯一的健康检查可能会导致 Metabase 无限重启,如果其应用程序数据库变得不可用。为避免这种情况,请考虑使用下面的活跃度检查,即 GET /livez。
单独的活跃度检查和就绪度检查
平台(如 Kubernetes、Google Cloud Run 和 HashiCorp Nomad)支持至少两种健康检查。如果您的平台支持它们,您应该配置两者:
- 活跃度探针 (Liveness probe):确定 Metabase 是否能够响应请求。如果检查失败,应用程序将重启。在 Metabase 中,可通过
GET /livez访问。 - 就绪度探针 (Readiness probe):通过检查与应用程序数据库的连接来确定 Metabase 是否已准备好处理工作。如果检查失败,Metabase 实例将继续运行,但会从负载均衡器中移除,直到检查成功。在 Metabase 中,可通过
GET /readyz访问。
某些平台(如 Kubernetes)支持启动探针,以防 Metabase 在能够通过就绪度检查之前需要更长的时间来启动。在这种情况下,请对启动探针使用相同的就绪度端点,即 GET /readyz。
GET /readyz 等同于 GET /api/health。
使用负载均衡器
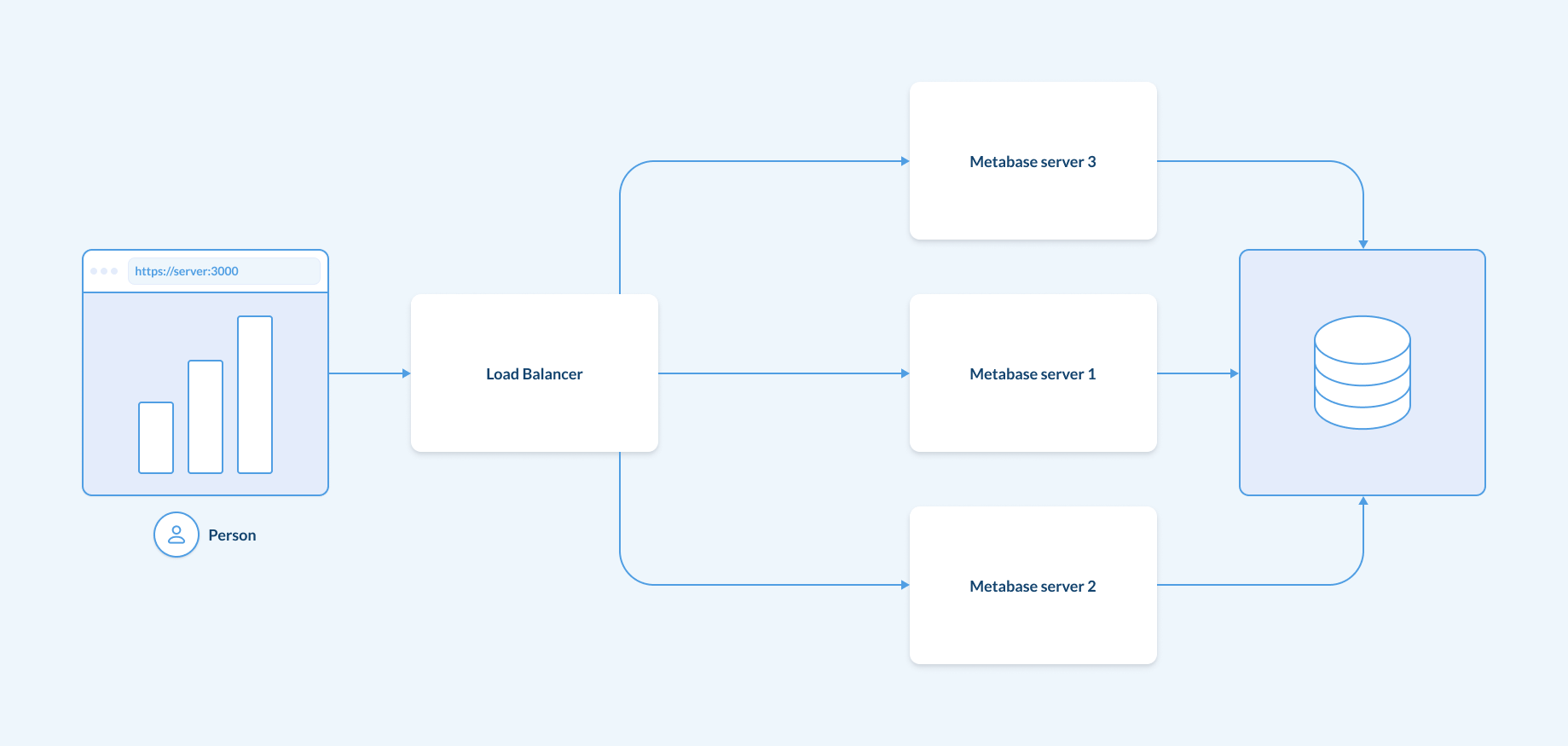
一个好的架构实践是使用负载均衡器来管理 Metabase,即使您只有一个服务器在运行,并且没有进行任何水平扩展。稍后部署负载均衡器可能会更复杂,负载均衡器还可以执行 TLS 终止(又称加密和解密 HTTP 流量)、WAF(Web 应用程序防火墙)、重定向和其他常见任务。
请参阅简单的负载均衡。
日志
Metabase 生成的应用程序日志应予以保留。这些日志对于调试和审计很有用。请查看我们关于日志配置的文档。
如果您还在 Metabase 上部署了负载均衡器或反向代理,我们建议您将这些日志保存到日志聚合器。这些日志将帮助您识别模式并在需要时进行调查。
Metabase over HTTPS
您可以在不使用负载均衡器或反向代理的情况下通过 HTTPS 提供 Metabase。
请注意,如果您使用同一台服务器同时运行 Metabase 和 TLS 终止(又称 HTTPS),Metabase 将损失宝贵的 CPU 资源,因为这些资源将用于加密/解密流量。因此,您可能需要使用负载均衡器。
需要避免的陷阱
吸取他人的经验教训。
我们建议您避免使用声称能自动扩展的服务。
根据我们的经验,许多声称能自动扩展的服务,嗯,并非神奇。我们建议您部署一些可观测性指标,对其进行监控,并根据这些观察结果进行必要的扩展更改,随着公司的增长,您的 Metabase 使用量也会增长。
避免使用在不使用时关闭服务器的服务。
如果您必须选择自动扩展服务,请避免任何会定期关闭不使用服务器的服务。
原因有二:
- 异步进程。Metabase 运行一些异步进程,例如获取表元数据、刷新模型或获取过滤器值。如果这些进程无法运行,用户将无法看到 Metabase 提供的许多功能。
- 启动时间。接下来登录您应用程序的第一批用户将遭受巨大的性能损失,因为服务器将不得不从完全冷启动状态启动。
在其他云提供商上运行的问题
请注意:许多云服务提供商会在共享基础设施上托管您。在这种情况下,租户共享 CPU 访问权限。多租户服务器租金可能更便宜,并且可以提供不错的性能,前提是您的 CPU 使用率保持在 100% 以下。如果您的 Metabase 服务器在一段时间内使用了 100% 的 CPU,提供商可能会限制您的分配 CPU 的性能,您的性能将显著下降。共享基础设施中的磁盘 IOPS 也会发生同样的限制。
升级到 Metabase 的新主要版本
通常,我们在次要版本之间(例如,从 1.51.1 到 1.51.2)不对应用程序数据库的架构进行任何更改,因此您可以在次要版本之间无缝地升级和降级。
升级到主要版本时(例如,从 1.50.9 到 1.51.3),您应该预期会有一些停机时间,因为 Metabase 可能需要处理应用程序数据库的架构更改。架构更改所需的时间取决于您应用程序数据库的大小。