

数据立方体
以超过二维的方式思考您的数据。
数据立方体是一种为分析查询而优化的模式。它们由指标(如订单数量的计算)组成,这些指标具有一个或多个常用维度。这些指标是预先计算好的,这意味着数据库中的某个作业会处理原始数据,执行这些计算,并创建一个新表来存储结果,以便人们可以查询结果,而不是每次都从头开始查询和计算。
当您根据某些度量聚合数据时,您可以想象您正在将几个表堆叠在一起,结果看起来有点像一个立方体。这个立方体比喻很贴切,但它只能帮助我们理解一部分——实际上,大多数多维数据远不止三个维度。有时您会听到这个概念被称为超立方体或OLAP 立方体,因为它在分析查询中的应用。
数据立方体将相关信息组织在一起,例如在某个时间段内存储不同门店特定产品的销售情况。这使得分析更加灵活,例如识别特定产品的趋势或评估门店绩效。当您的数据以立方体形式组织时,复杂 OLAP 查询的大部分繁重工作都已预先计算好,这意味着这些查询的执行速度比将这些表单独存储要快得多。
数据立方体是否过时了?
数据立方体在 20 世纪 90 年代开始流行,当时计算能力和内存都非常昂贵。那时,执行复杂的分析查询会对系统造成巨大压力,聚合和缓存这些频繁访问的指标非常有意义。
然而,近年来,数据仓库、列式存储以及更便宜、更强大的计算机的兴起导致了分析领域的一次范式转变:对优化分析速度的关注已让位于优先考虑数据集的可用性,并确保数据以易于查询和探索的方式格式化。
所以,是的,数据立方体已经失宠,但如果您从事数据库工作,您仍然可能会在某个时候遇到数据立方体的概念和操作。
Metabase 中的数据立方体操作
为了让您了解典型的数据立方体操作,我们将使用 Metabase 的示例数据库对数据立方体的近似值进行切片、切块、透视、下钻和上卷。我们将从查询我们的 Orders 表开始,以查看按产品类别和订单创建年份分组的订单计数。
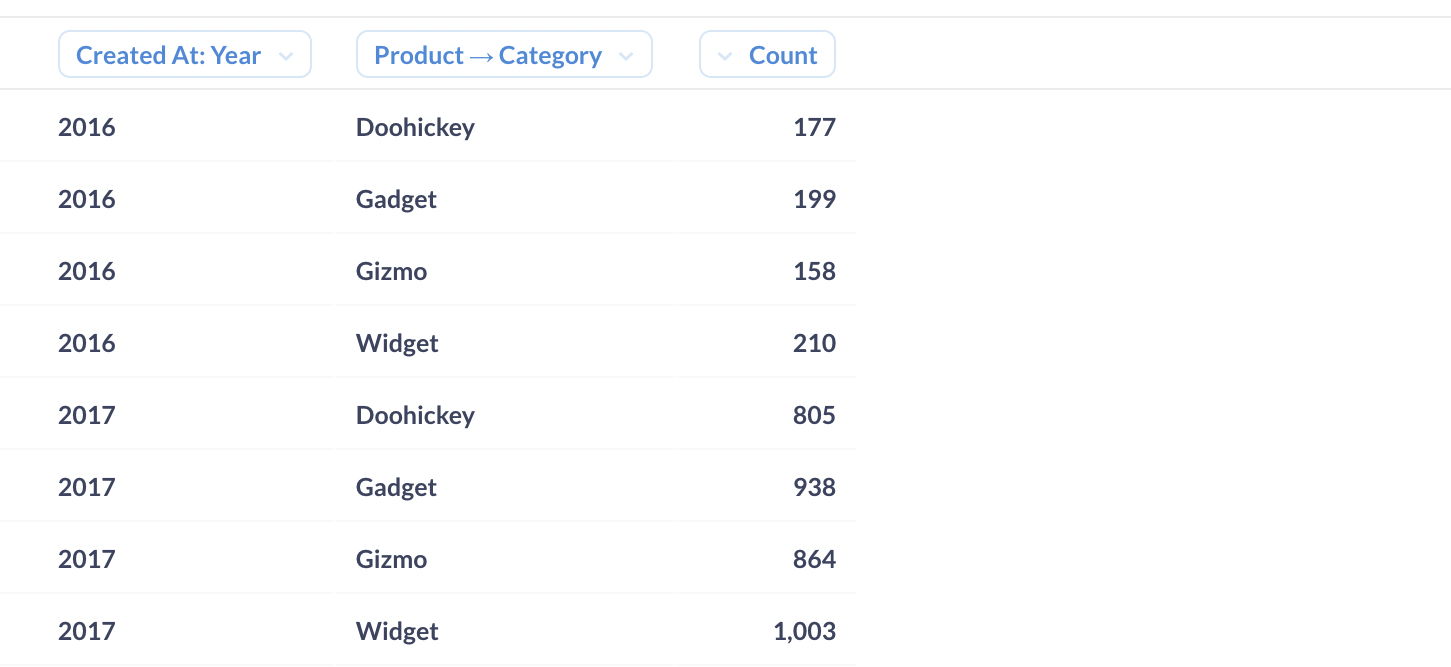
重要的是要了解 Metabase 不会将您链接的表“转换”为数据立方体,但如果您的数据已经采用立方体结构,Metabase 可以毫无问题地理解这些立方体。
无论哪种方式,Metabase 都可以执行与数据库软件中对立方体执行的类似操作,如下所示。但是,如果您的数据在添加数据源时未配置为立方体,那么在 Metabase 中执行这些类似操作并不会使这些过程运行得更快。从这个意义上说,Metabase 有助于组织并使这些操作易于执行,但它们的性能仍然取决于您的底层数据库。
切片和切块
对数据立方体进行“切片”是指分离出一个表,根据单个维度分析数据。这基本上是创建此立方体的逆过程,但您可以从立方体的任何角度进行切片。
与切片类似,“切块”数据立方体使我们能够放大数据特定子集的值,就像切出一个更小的立方体以更仔细地查看多个维度。
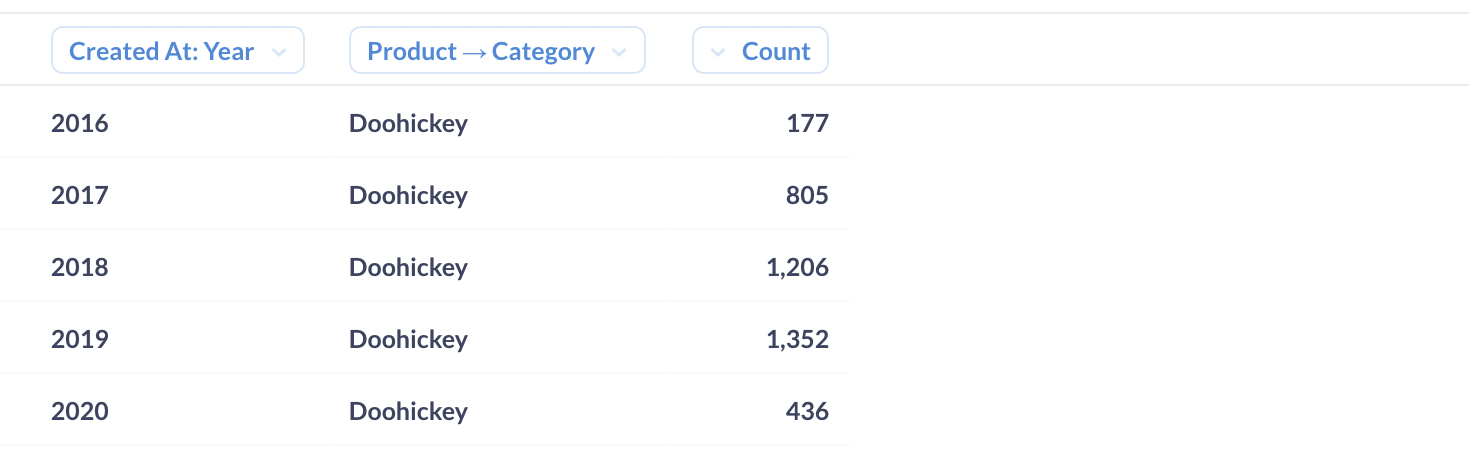
在 Metabase 中,切片和切块通过过滤器实现,过滤器根据特定维度缩小结果范围。下面,我们已经过滤了上面的相同表格,只包含产品类别为 Doohickey 的订单数量——这是一个切片的例子。
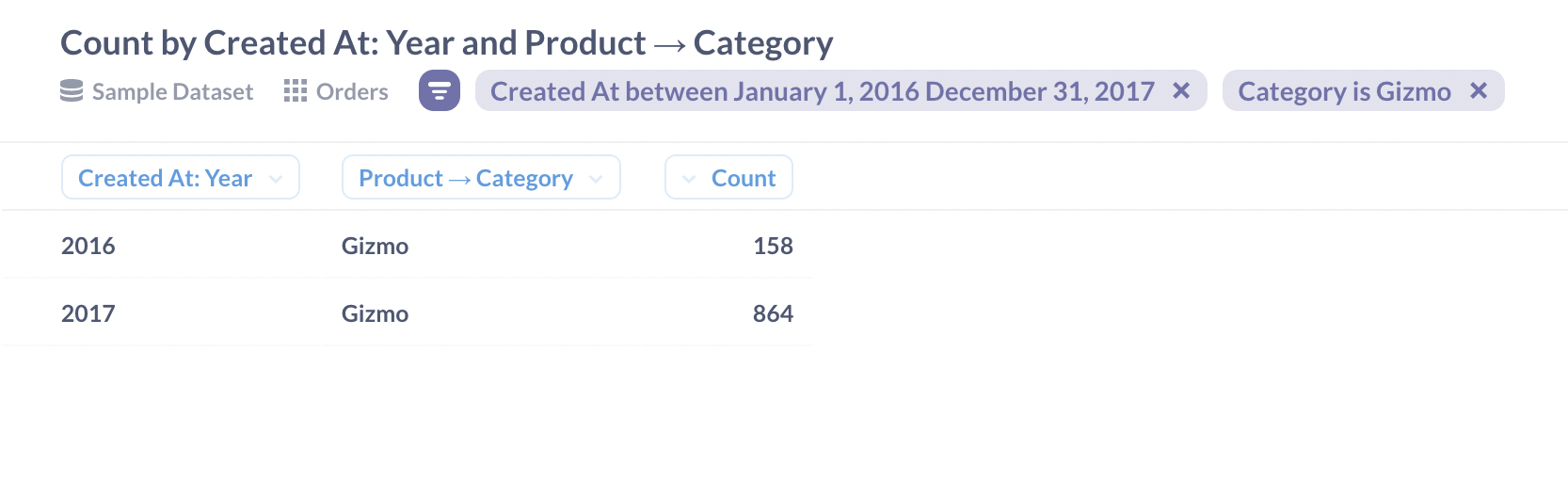
切块操作看起来类似,但会包含多个维度,比如我们想查看 2016 年和 2017 年包含 Gizmos 的订单
透视
“透视”我们的立方体允许我们从不同的角度查看它,并有机会交换构成行和列的字段。在这里,小计不是预先计算的;Metabase 会即时进行计算。
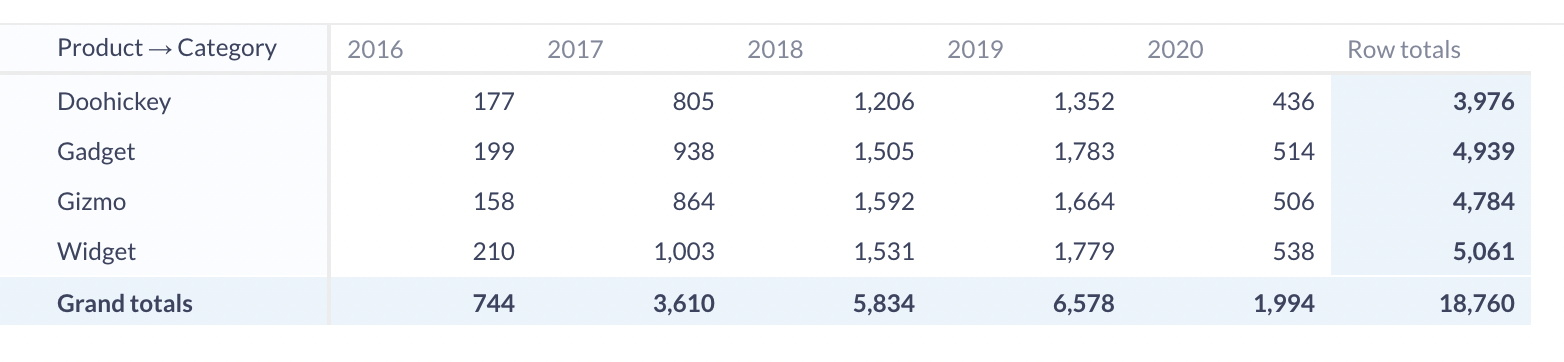
下钻
执行“下钻”操作可为我们提供任何给定维度的更精细视图。我们可以在 Metabase 中通过一个或多个维度对数据进行下钻(也称为钻取),例如,如果我们想按产品类别和产品供应商查看订单。
上卷
“上卷”操作提供数据立方体给定维度上的聚合数量。在 Metabase 中,这是通过汇总完成的。