

合并来自不同数据库的数据
如何在 Metabase 中连接不同数据库的表。
让我们谈谈为什么我们在 Metabase 中不允许用户从多个数据库中连接数据(如果您绝对必须这样做,我们也会提供一些想法和解决方法)。
Metabase 为什么不支持跨数据库连接?
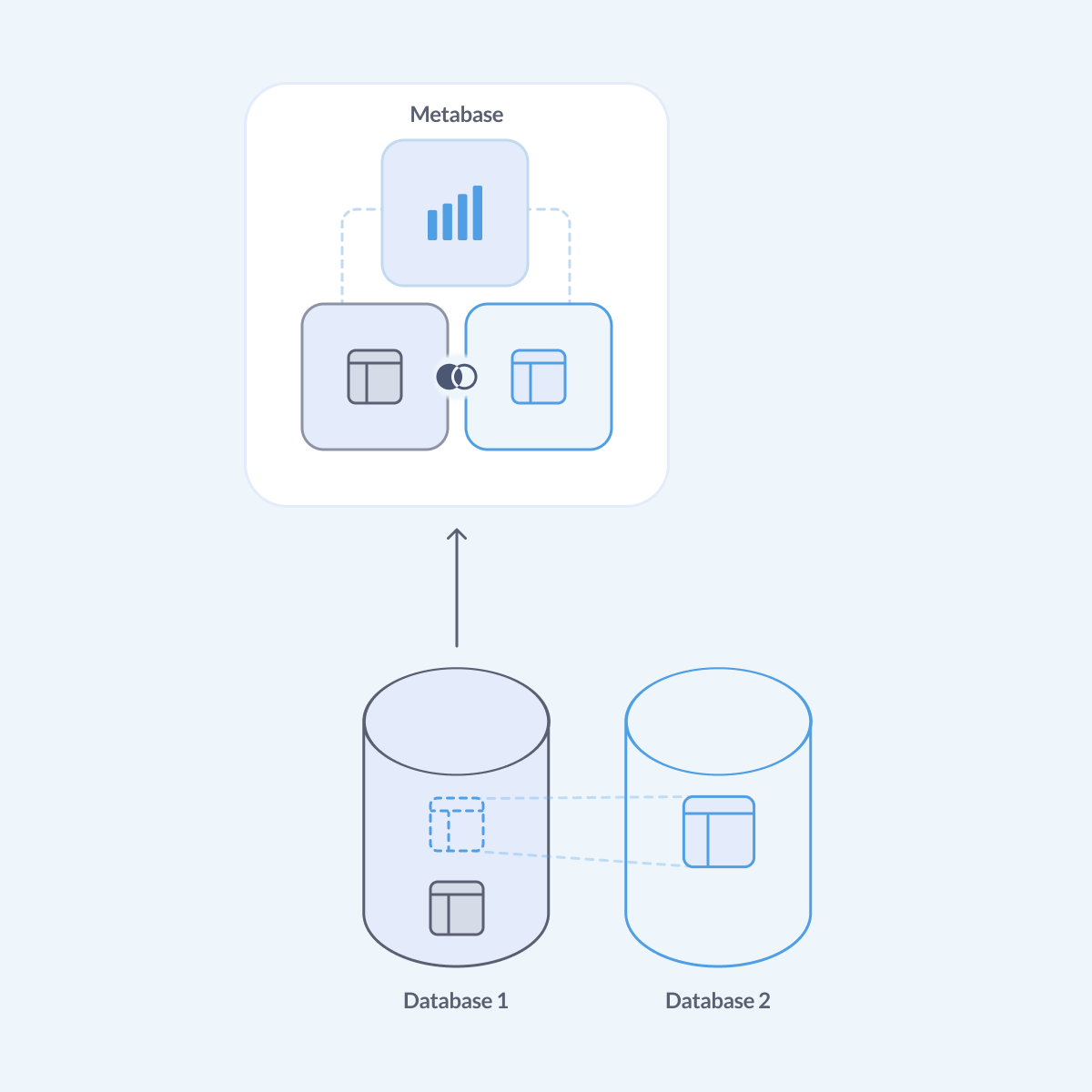
Metabase 不是存储引擎或查询引擎。Metabase 连接到您的数据库,将查询发送到数据库;然后数据库本身执行查询,Metabase 提取结果并可视化它们。您的数据保留在您的数据库中,所有处理都在您的数据库内部进行。
大多数数据库都经过优化,可以高效地处理自身数据上的查询,但它们没有原生方法可以与其他数据库通信。要连接来自两个不同数据库的数据,Metabase 需要将数据从多个数据库拉取到其自身内存中或写入磁盘,然后对该数据运行查询。这可以适用于小型表,但无法很好地扩展(更不用说 Metabase 需要将您的数据存储在您的数据库外部的缺点了)。
想象一下,数百人运行需要连接多个数据库的数据的查询,每个数据库都有大量行,将所有这些数据放入 Metabase 的内存中,然后针对已连接的数据运行未经优化的查询。这会变得非常慢(也非常昂贵)。
其他一些 BI 工具通过在您的数据库和 BI 之间创建一个中间层来存储数据来解决这个问题,这通常意味着需要大型、复杂且昂贵的部署。
为了使 Metabase 保持轻量和简单,我们尚未在产品中直接构建此功能(至少目前还没有!永不言败——时不时查看一下 Metabase 产品路线图)。但这里有一些方法可以设置您的数据以允许涉及多个数据库的查询,同时保持对性能的关注并控制您的数据。
最佳解决方案:使用数据仓库
(或者数据湖。或者数据湖仓库。世界是你的牡蛎。)
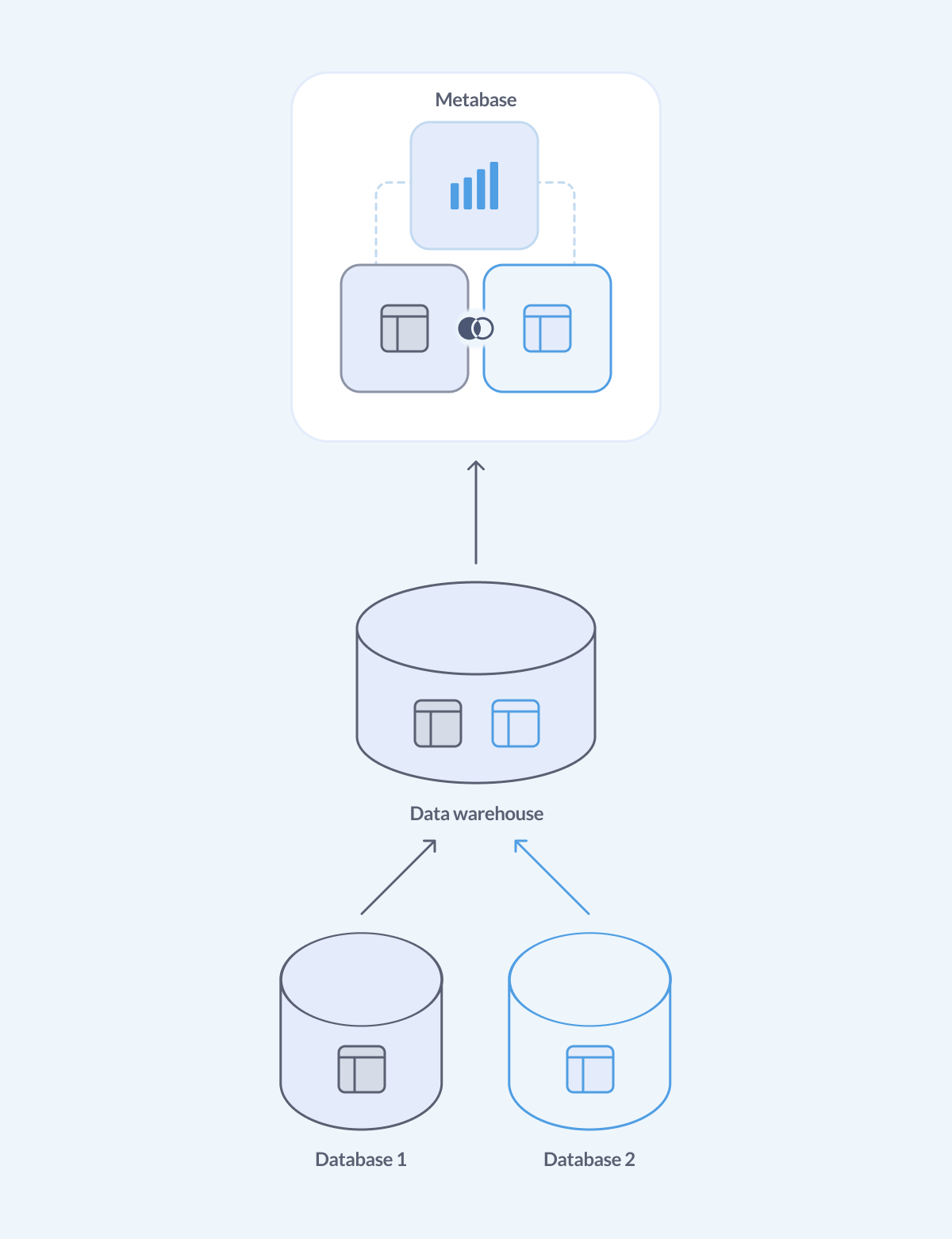
要点是:您设置一个 ETL(或 ELT,或 ELTL,您懂的)过程,定期将来自您使用的所有不同数据库和第三方系统的数据导入,将该数据存储在一个地方——数据仓库——并使用该数据仓库来支持您所有的分析需求。
优点是
- 所有数据都已在一个地方,您无需在网络上将数据发送到另一个数据库。
- 现代数据仓库的架构针对分析查询进行了优化。
- 您完全控制您的数据。
Metabase 可以连接到所有最受欢迎的数据仓库,如 Snowflake、Redshift、BigQuery、Databricks 等。查看 我应该使用哪个数据仓库?。
要构建数据仓库,您至少需要设置基础架构,构建一个复制数据的管道,并将数据建模成适合分析的形状——这是一笔重要的前期投资。但它创建了一个一致、高性能和可扩展的环境来支持您的分析,因此它将来会带来回报。
如果您暂时无法投入构建数据仓库,还有一些替代方案
在仪表板卡片上合并系列
如果您只需要在单个图表中合并两个系列,并且每个系列都基于单个数据库的数据构建,您可以将这两个系列添加到仪表板卡片中。
例如,假设您想在同一个图表上显示来自“用户”数据库的用户数(按月),以及来自“财务”数据库的平均支付金额(按月)。您所要做的就是将这些系列添加到单个仪表板卡片中——无需跨数据库连接。
查看我们的文档 合并已保存的问题。
PostgreSQL:使用外部数据包装器
如果您想组合两个 Postgres 数据库(或一个 Postgres 数据库和其他一些数据库)的数据,并且不想构建数据仓库,您可以使用 外部数据包装器 (FDW)。外部数据包装器允许您的 Postgres 数据库读取远程数据存储(包括其他数据库)中的数据。
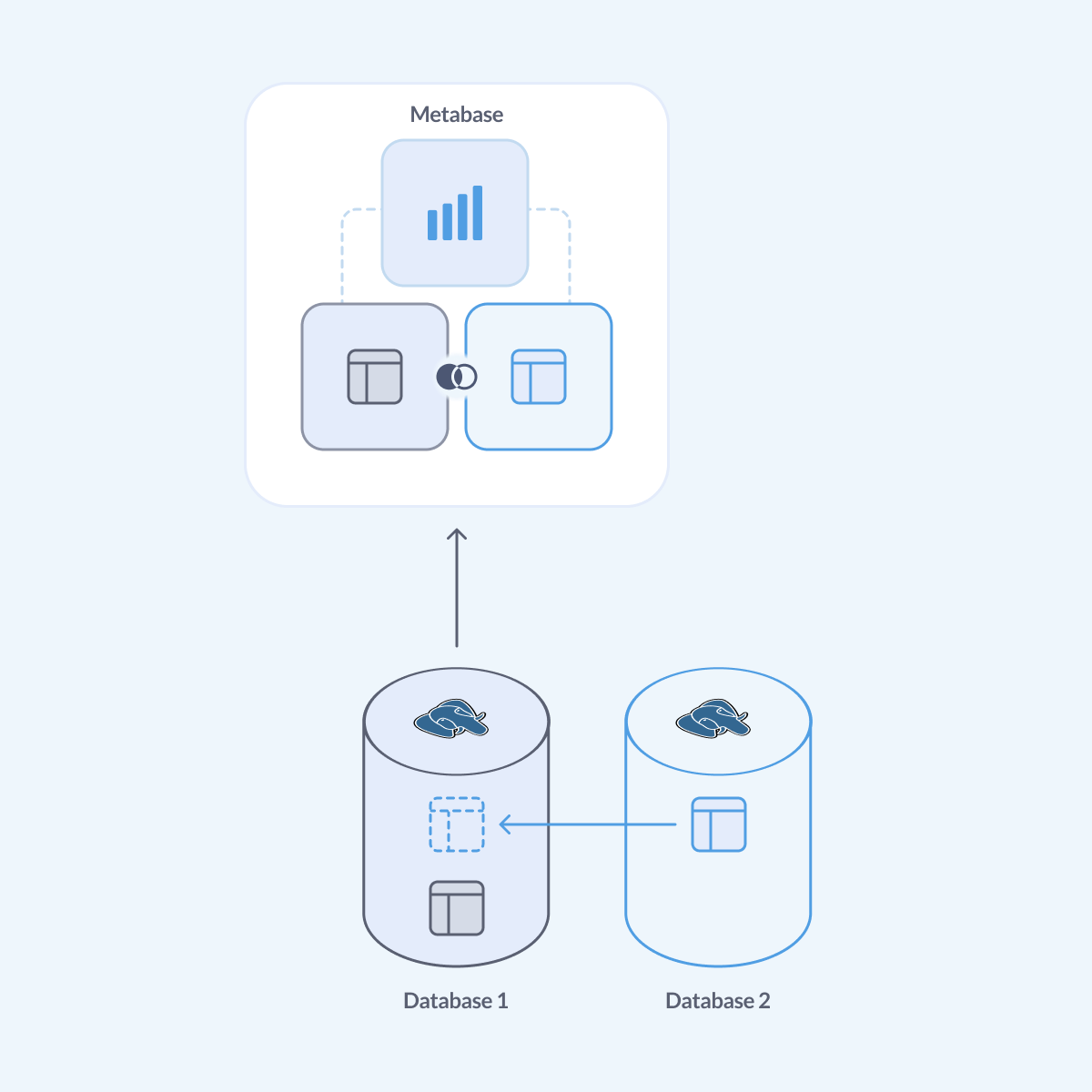
要从一个 Postgres 数据库查询另一个数据库,您可以使用 postgres_fdw 扩展,它是官方 PostgreSQL 分发版的一部分。
假设我们有
- 一个数据库
db1,其中有一个public模式下的表table1, - 一个数据库
db2,其中有一个public模式下的表table2
我们想一起查询 table1 和 table2 中的数据。
我们将从 db2 中的表镜像到 db1 的一个模式中,这样就可以连接到 db1(例如,使用 Metabase)并运行查询来访问来自 db2 的数据。
-
在您的数据库管理工具中(不在 Metabase 中),在
db1上运行此脚本。确保替换您自己的名称和密码。------ Run on DB1: ------ -- Add the postgres_fdw extension CREATE EXTENSION postgres_fdw; -- Create a server object to represent the foreign database -- Specify the connection information for DB2 in OPTIONS -- In this script we're connecting to a database inside the same server and that's why we use 'localhost' CREATE SERVER db2_server FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host 'localhost', dbname 'db2'); -- Create a user mapping for the foreign server -- It maps the user accessing DB1 (for example, metabase_user) to a user accessing DB2 (your_db2_user) -- The user in DB1 will use that role to access the remote DB2 server CREATE USER MAPPING FOR metabase_user SERVER db2_server OPTIONS (user 'your_db2_user', password 'your_db2_password'); -- Import public.table2 from DB2 into public schema of DB1. -- You can use other schemas or create a new schema specifically for the foreign tables IMPORT FOREIGN SCHEMA public LIMIT TO (table2) FROM SERVER db2_server INTO public; -- You should be able to query table2 from DB1 now SELECT * FROM table2;如果您遇到任何问题,请查看 postgres_fdw 的文档
-
将 Metabase 连接到您的 PostgreSQL 数据库
db1(您镜像了外部表的那个)。连接建立后,您应该会在
db1中看到外部表table2(以及table1)出现在 Metabase 导航侧边栏的“浏览数据”中。 -
既然您可以通过连接
db1查询table1和table2,您应该能够使用查询生成器或 SQL 创建连接table1和table2数据的查询。
还有其他外部数据包装器——例如,一个用于从 Postgres 查询 Oracle 或 MySQL 数据库的 FDW——作为第三方工具可用,但如果您决定使用第三方 FDW,请检查它们是否仍在积极维护。查看 PostgreSQL Wiki 上的外部数据包装器列表。
MySQL:创建视图
MySQL 提供了一种原生方法来查询同一服务器上不同数据库的数据,语法类似 database.schema.table.field。但在 Metabase 中,当您连接到一个数据库(我们称之为 db1)时,Metabase 不会知道同一服务器上存在另一个数据库 db2,因此您将无法在 db1 上运行引用 db2 的查询。
解决方法是在 db1 中创建一个视图,该视图镜像来自 db2 的数据。
那么,假设您有
- 一个数据库
db1及其表table1, - 一个数据库
db2及其表table2,
并且您想连接 table1 和 table2 的数据。
-
在您的数据库管理工具中(不在 Metabase 中),在
db1中创建一个视图,该视图从db2中选择table2------ Run on DB1: ------ -- Create a view for db2.table2 inside db1. CREATE VIEW table2 AS SELECT * FROM db2.table2; -
将 Metabase 连接到您的 MySQL 数据库
db1(您创建了视图的那个)。连接建立后,您应该会在
db1中看到视图table2(以及table1)出现在 Metabase 导航侧边栏的“浏览数据”中。 -
既然您可以通过连接
db1访问table1和table2,您应该能够使用查询生成器或 SQL 创建连接table1和table2数据的查询。
Snowflake:创建视图
与 MySQL 类似,Snowflake 提供了一种原生方法来查询不同数据库的数据,语法类似 database.schema.table。但在 Metabase 中,当您连接到一个数据库(我们称之为 db1)时,Metabase 不会知道另一个数据库 db2 存在,因此您将无法在 db1 上运行引用 db2 的查询。
解决方法是在 db1 中创建一个视图,该视图镜像来自 db2 的数据。那么,假设您有
- 一个数据库
db1,其中有一个public模式下的表table1, - 一个数据库
db2,在public模式下有一个表table2,
并且您想连接 table1 和 table2 的数据。
-
在您的数据库管理工具中(不在 Metabase 中),在
db1中创建一个视图,该视图从db2中选择table2------ Run on DB1: ------ -- Create a view for db2.public.table2 inside db1. CREATE VIEW table2 AS SELECT * FROM db2.public.table2; -
将 Metabase 连接到您的 Snowflake 数据库
db1(您创建了视图的那个)。连接建立后,您应该会在
db1中看到视图table2(以及table1)出现在 Metabase 导航侧边栏的“浏览数据”中。 -
既然您可以通过连接
db1访问table1和table2,您应该能够使用查询生成器或 SQL 创建连接table1和table2数据的查询。
使用联合查询引擎
联合查询引擎的工作是为您提供一个单一的界面来查询和分析来自不同数据源的数据。您可以将您的联合查询引擎连接到多个数据库,然后将您的 Metabase 连接到联合引擎,并通过它查询所有数据,就像它们在一个数据库中一样。
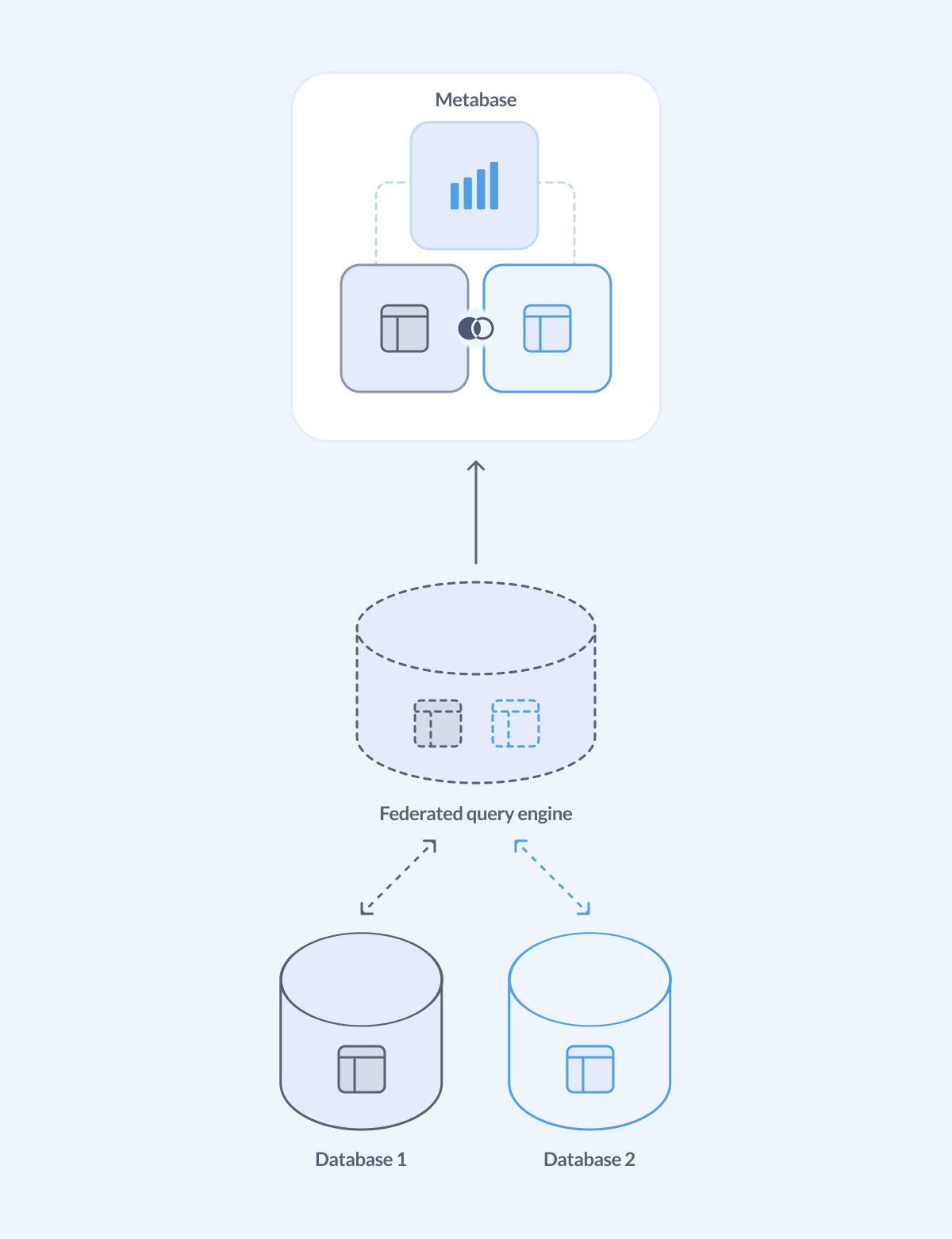
它不会像专用数据仓库那样快,因为数据仓库可以更有效地存储数据并优化查询,但它可以是一个不错的中间解决方案。
Metabase 可以连接到几个流行的联合查询引擎:Presto、Trino 和 Starburst,以及 Athena。
检查您的数据库功能
如果您使用的是 PostgreSQL 或 MySQL 以外的数据库,并且无法使用联合查询引擎或构建数据仓库,请与您的特定数据库联系——它可能已经具备您解决特定用例所需的功能。
理念是:如果您的数据库有读取其他数据库数据的方法,那么您就可以使用该功能将数据从 db2 获取到 db1,然后将 Metabase 连接到 db1,并让来自 db2 的数据出现在 db1 中,以便进行查询(和连接)。
例如,BigQuery 外部表,或 Redshift 联合查询可能适用于某些用例。Databricks 和 ClickHouse 也提供类似的功能。