

数据概况指南
通过数据技术栈之旅,为数据初学者提供数据世界指南。

本文为数据领域的新手提供了一个概览,帮助他们了解构成数据全景的所有工具。这里的想法是为您提供一个大致的概况,以便在人们谈论这些内容时,您能有一些基本的背景知识。但首先
数据世界简史(滑稽版)
早些时候,数据存储和操作是一个复杂且昂贵的过程。存储数据需要本地服务器(就像洗手间旁边空调房间里一排排闪烁的计算机和一团乱麻的电缆)。数据检索速度可能非常慢:查询和操作数据需要数小时,有时甚至数天。
但工具已经大大改进,尤其是在过去十年中,特别是随着云基础设施的兴起(这只是在空调环境中,有理智的电缆管理的大型计算机机架,您可以按需租用)。如今,数据处理比以往任何时候都更快、更便宜。现在有大量的工具可用于处理数据,这可能会使数据全景看起来比实际更复杂。
有很多关于商业智能、大数据和 AI 驱动洞察的讨论,但这些都只是营销术语。大多数企业没有 PB 级甚至 TB 级的信息,他们也不需要那么多数据。大多数企业只需要能够查询他们确实收集到的数据,发现并应对趋势,并思考他们希望收集哪些其他数据来回答他们无法回答的问题。许多企业还需要能够向客户提供数据,例如通过将图表嵌入到他们的应用程序中。
如今,大多数公司只需要一个简单的数据技术栈,并且在您的业务真正起飞时,它们很容易扩展。它们也是理解整个数据环境的好方法,因此我们将带您简要了解一个基本的数据技术栈,首先从为什么您一开始就需要一个数据技术栈开始。
数据技术栈集中您的数据,并保护您的应用程序免受可能导致应用程序变慢的分析查询的影响
“数据技术栈”只是一个术语,指管理数据从源到仪表板整个过程的软件集合。构建独立于应用程序数据的数据技术栈会产生成本,但数据技术栈的优势本质上是双重的
- 数据技术栈不会因好奇分析师的查询而减慢您的应用程序数据库的速度。这些查询可能涉及大量数据,这会占用您数据库的资源,并使您的应用程序对使用它的普通用户变慢。
- 数据技术栈集中您的数据,包括来自应用程序以外来源的数据,并以易于查询的方式组织数据。
数据技术栈层级概览
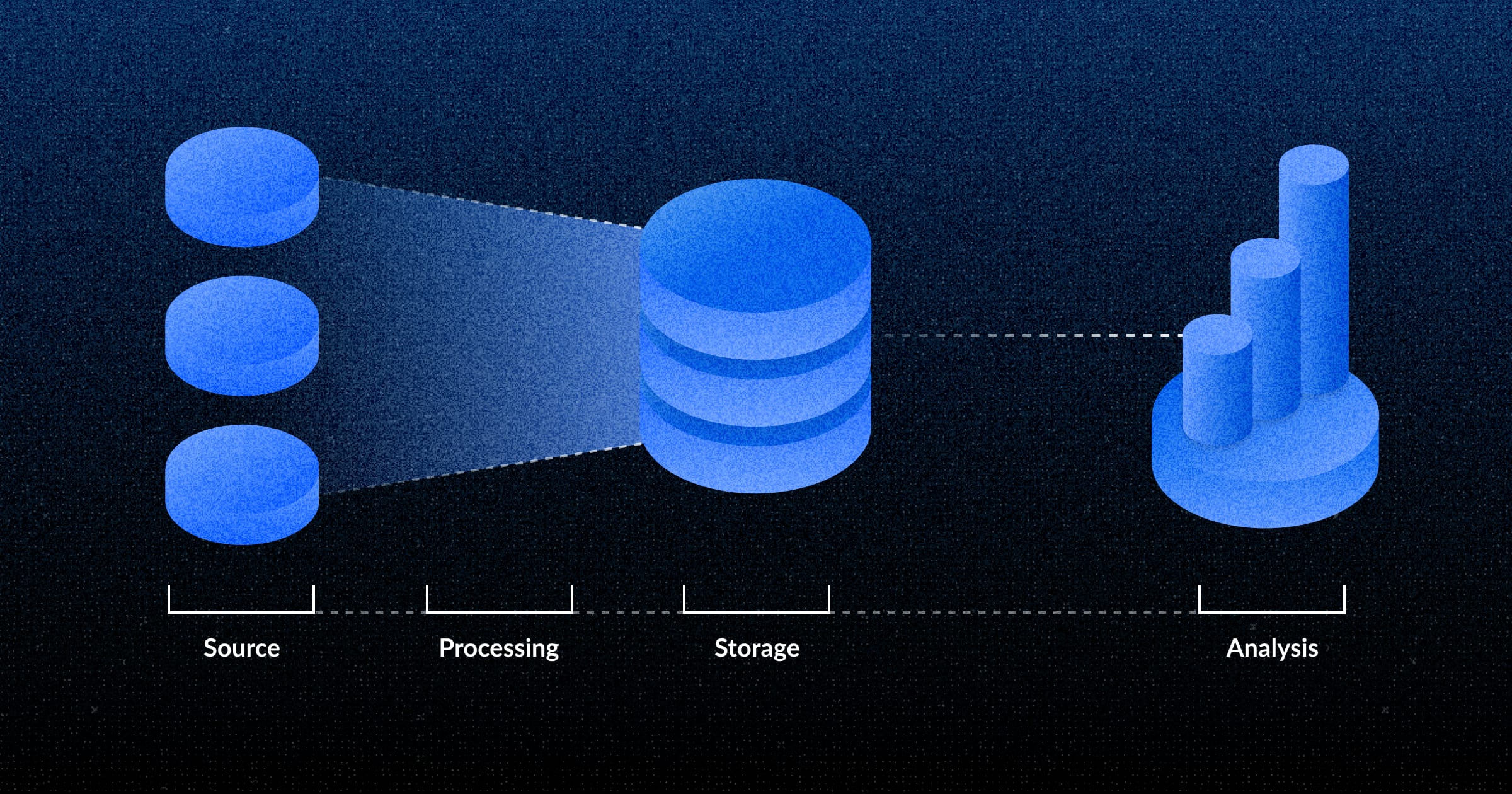
从高层次来看,一个数据技术栈由四层组成
这些层级有些随意,并且它们之间存在重叠(特别是转换和建模层)。您也可以认为还有其他层级(例如数据治理或数据监控),但这四层是主要的。
数据源层
企业从其应用程序中收集数据,但它们也从第三方应用程序和服务中积累了大量数据。数据可能来自
- 生产数据库。有时称为事务数据库、操作数据库或应用程序数据库(或简称“生产库”)。即,您的软件在执行其功能时用于存储所有数据的数据库。
- 运营应用程序。来自社交媒体、客户关系管理和支付提供商应用程序及 API 的数据。
- 外部数据。来自第三方的数据,如网络分析(例如 Google Analytics)、人口统计数据、市场数据、地理空间数据等。
数据摄取和数据集成
您的公司将不得不从所有这些不同的来源获取数据。自行处理所有这些数据可能非常耗时,因为您必须从每个应用程序的 API 获取数据。因此,一个选择是使用提供这些应用程序连接器的服务。这些有时被称为集成和摄取工具,其中包括以下工具:
- Fivetran
- Stitch
- Zapier
数据转换和建模层
通常,尝试分析来自多个来源的未经修改的数据是一场噩梦:数据分散在各地,回答简单问题可能需要查询多个不同的表才能获取所需数据。
数据技术栈的转换和建模层旨在将数据整理成易于查询和探索的“形状”。其理念是构建名为 ETL 的计划流程,抓取大量数据,然后将这些数据转储到您的数据仓库中。在某些情况下,ETL 会批量抓取数据(例如每晚一次);它也可以是流式的,这意味着数据一旦被应用程序记录就会立即发送到数据仓库。
转换的非详尽列表
- 从 .csv 或 JSON 格式中提取数据,并将该数据插入关系数据库。
- 将来自多个来源的数据聚合到单个数据集中。
- 更改数据格式,例如从 JSON 到 CSV。
- 过滤数据或填充数据中的空白。
ETL:提取、转换、加载
ETL 是脚本,有时称为作业,它们从各种来源(包括已存储在数据仓库中的原始数据)提取数据,转换数据,并将转换后的数据加载到数据仓库中
ETL 代表 Extract(提取)、Transform(转换)和 Load(加载)
- 提取: 一组用于抓取原始数据的查询或 API 请求。
- 转换: 用于分析数据(即,使数据易于查询)的查询或脚本。
- 加载: 一组将转换后的数据加载到数据仓库中的查询。
这听起来很复杂,但它实际上只是一系列脚本的运行。一个超级基本的 ETL 作业可能如下所示:
- 从三个包含客户数据的表中查询数据。
- 将“地址”列中的所有值转换为大写。
- 如果“省份”列中没有值,则从邮政编码中查找省份并将其插入到“省份”列中。
- 将结果插入数据仓库中的
CUSTOMER表。
在过去几年中,ELT(而非 ETL)变得更受欢迎(尽管所有人仍然只说 ETL)。ELT 的理念是使用数据摄取工具将来自源的原始数据以任何格式加载到数据仓库中,然后运行 SQL 查询,将这些数据转换为易于查询的表或列,并将该数据保存到数据仓库中。
ELT 路径的理由是,通常更容易先将原始数据加载到数据仓库中,然后对其进行更复杂的转换(而不是在将数据放入数据仓库之前进行转换)。此外,如果您需要,您还可以保留原始数据(存储成本已经非常低廉)。
延伸阅读
数据建模
数据建模是一个抽象术语,在不同语境下有略微不同的定义,因此即使您以前遇到过这个术语,您可能仍然不完全确定人们到底在谈论什么。
数据建模是指决定要收集哪些关于现实世界的数据,以及如何将收集到的数据组织成数据库中的表,使其变得有用。基本上就是这样。如果您有一个名为“客户”的电子表格,那么您的客户“模型”就是该电子表格中的一组标题:姓名、地址、电子邮件等,它们从您的业务角度描述了您的客户。您如何“建模”您的客户取决于您的业务运作方式。您的客户模型是否需要包含“食物过敏”?“平均打字速度”?“潜水认证状态”?
数据建模还可以指数据在数据库中的存储方式。因此,它不仅定义列(有时称为字段)及其数据类型,还包括这些列如何在表中分组,以及这些表如何相互关联以形成一个更宏大的视图。例如,您可能希望将客户模型链接到购买模型,以了解谁购买了什么。
所有这些转换的原因是,用于应用程序的数据模型通常不适合分析。为应用程序建模数据的方式通常优化于创建、读取、更新和删除记录。您有时会听到 CRUD(创建、读取、更新、删除)这个缩写。您的数据在应用程序中具有“形状”(例如行和列),您希望在数据仓库中重新塑造这些行和列,以便更容易地筛选和汇总表格。
数据转换和建模工具
- dbt - 是一种用于构建、测试和记录数据模型的开源工具。dbt 位于您的数据仓库之上,并使用 SQL 转换已存储在数据仓库中的数据。
- Apache Airflow - 一种开源数据工作流管理工具,可与 Fivetran 或 Stitch 结合使用。它可用于监督 Fivetran 或 Stitch 任务的执行。
- Metabase。一些分析工具(如 Metabase)也允许人们自行建模数据。通过这种方式,人们可以即时建模数据,根据业务变化完善其客户或产品模型。
延伸阅读
数据存储层
转换数据后,您需要将其存储在易于检索的地方。
有不同类型的数据库,但为了数据技术栈的目的,我们这里主要讨论两大类数据库:事务型和分析型。
事务型数据库
事务型数据库专为支持软件而构建。它们使用表(关系)来分组列(属性)。
- MySQL
- Oracle
- PostgreSQL
- SQLite
- SQL Server
分析型数据库
分析型数据库的结构旨在简化分析查询(例如,A、B、C 类所有产品的平均价格点是多少?)。它们通常使用列式存储,其中数据按列收集,而不是按表中的列收集。分析型数据库的示例包括
- BigQuery
- Hydra
- Redshift
- Snowflake
- Vertica
数据仓库是用于存储组织希望分析的所有数据的数据库。数据仓库有时指像 Snowflake 或 BigQuery 这样的分析型数据库,但像 PostgreSQL 和 MySQL 这样的事务型数据库已经变得非常出色,并且(通过适当建模)可以轻松处理大多数分析工作负载。因此,除非您正在处理非常庞大的数据集,否则像 PostgreSQL 这样的强大 RBDMS 可能就是您数据仓库所需的全部。无论哪种情况,数据仓库通常都在云端运行(在 Amazon Web Services、Google Cloud Platform、Microsoft Azure 等上),因此公司不必担心构建自己的服务器来运行数据库。
数据湖是存储非结构化数据的地方。您可以将它们视为充满文件夹和文件的大型分布式文件系统。您可以使用数据湖倾倒各种格式的数据(CSV、视频、JSON、音频文件等)。一旦数据进入数据湖,您可以使用 Presto 或 Athena 等查询引擎查询数据,对其进行格式化和建模,然后将建模后的数据加载到数据仓库中供分析师探索。
延伸阅读
数据分析层
数据分析是数据技术栈的可视化层。有时称为数据分析或商业智能。这一层是您制作数据表格和图表的地方,以向他人展示您知道自己在做什么,并且我们绝不是随心所欲地编造一切。
一旦数据经过转换并加载到您的数据仓库中,您就可以将 Metabase(抱歉,一个商业智能平台)等可视化工具连接到您的数据仓库,以“解锁洞察”。
一些 BI 工具还包括数据建模工具,在某些情况下还支持写回数据库(即允许您创建、更新或删除记录),这为构建后台应用程序以处理您的数据打开了各种可能性。
数据分析工具
像每一层一样,您有很多选择:
- Looker
- Metabase
- Mode
- Power BI
- Redash
- Superset
- Tableau
延伸阅读
- 实际上,大部分在“学习 Metabase”中。
下一篇:数据库类型
了解不同类型的数据库及其工作原理。