

教程:多层聚合
如何使用查询构建器提出包含多个部分的问题。
许多分析问题可以通过四个步骤来回答
- 连接两个表,将所有需要的信息放在一个地方。
- 筛选数据,使其只包含相关值。
- 分组和聚合这些值,以创建您需要的洞察。
- 可视化结果,以便您能够理解数据在告诉您什么。
但是,查询不必止步于此:Metabase 允许您通过添加更多筛选器并逐步计算更多摘要。要了解这如何工作,让我们来追踪分析师在探索每周售出每个类别的商品数量时可能经历的步骤。
我们首先计算在 示例数据库 中,每个产品类别每周售出的商品数量。销售信息在 Orders 表中,产品类别在 Products 表中,因此我们通过匹配产品 ID 来连接它们。目前我们想了解所有产品类别,因此我们无需过滤此数据,但我们需要对其进行分组和汇总,以按类别计算每周总数。
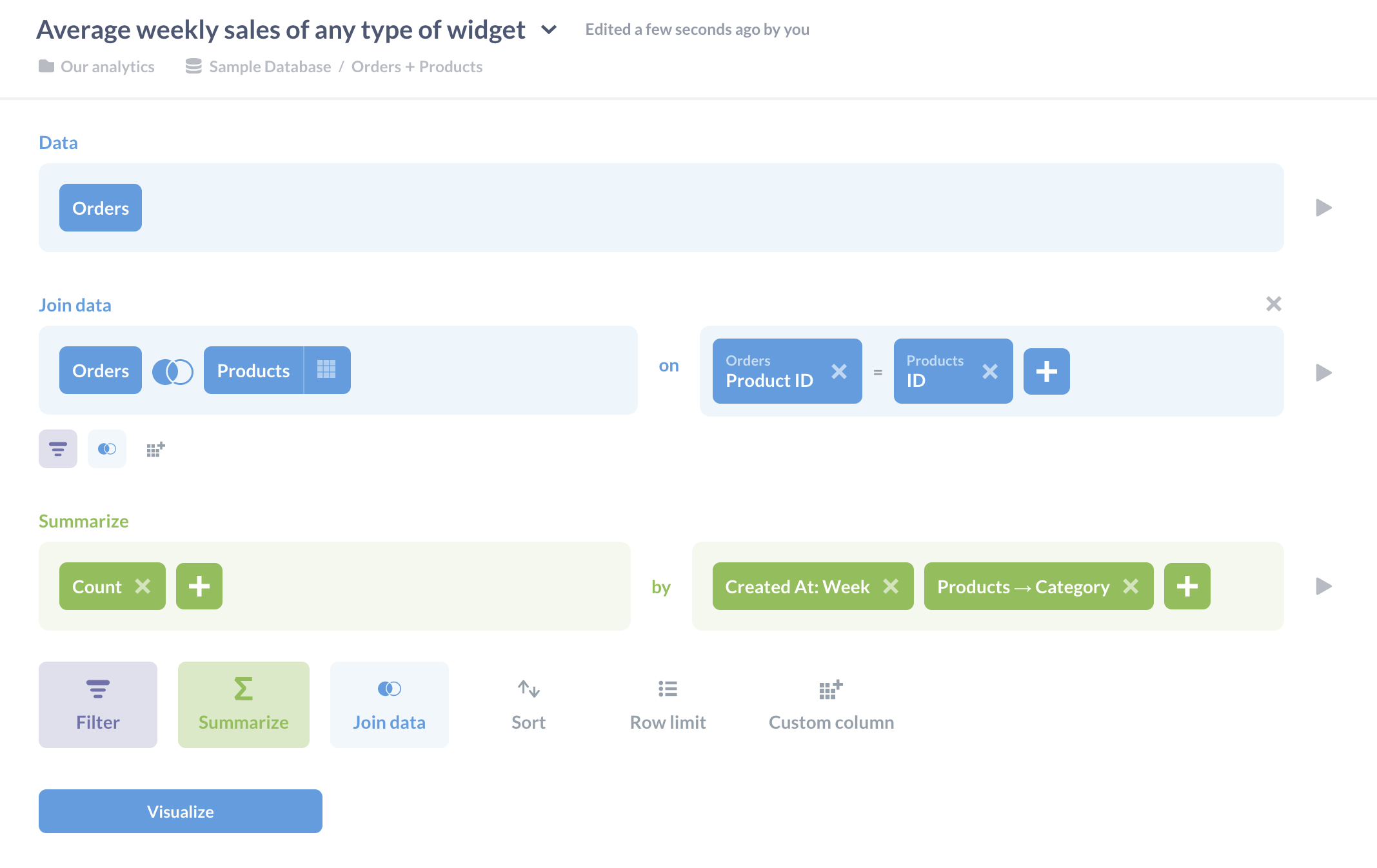
我们可以将迄今为止的结果可视化为时间序列折线图,以获得我们以前没有的洞察。
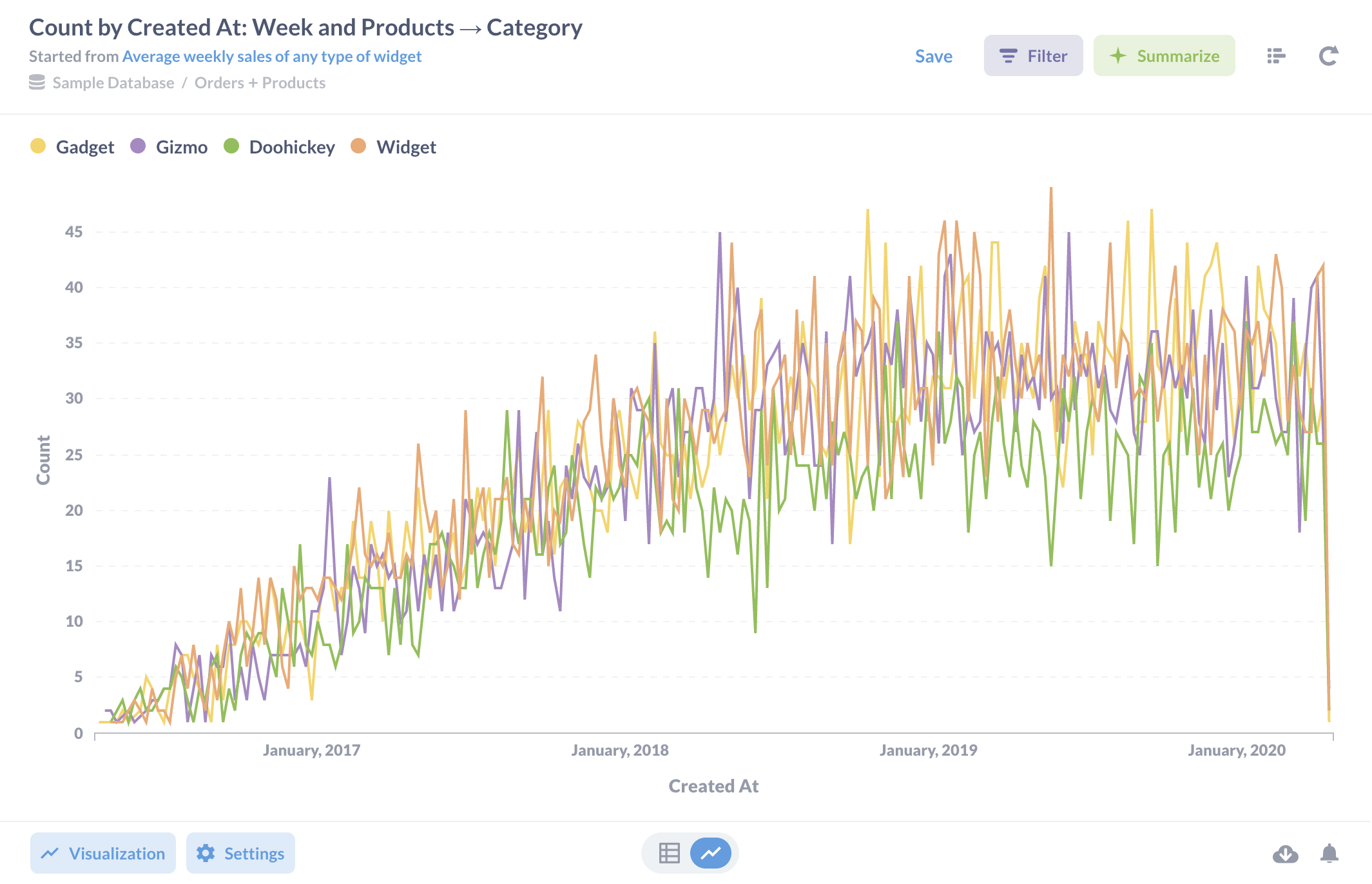
但是,让我们更进一步,在摘要步骤之后添加另一个筛选器,以从我们的数据中排除小工具。当我们回到查询构建器并单击编辑器底部的添加筛选器按钮时,它会显示摘要数据中的三个列:Created At、Category 和 Count。点击几下即可创建一个筛选器,该筛选器会删除类别为“widget”的行。
如果保存筛选器并可视化数据,我们将得到一个结果表。如果您从可视化设置中选择折线图,图表现在将仅显示我们感兴趣的三个产品类别的线。
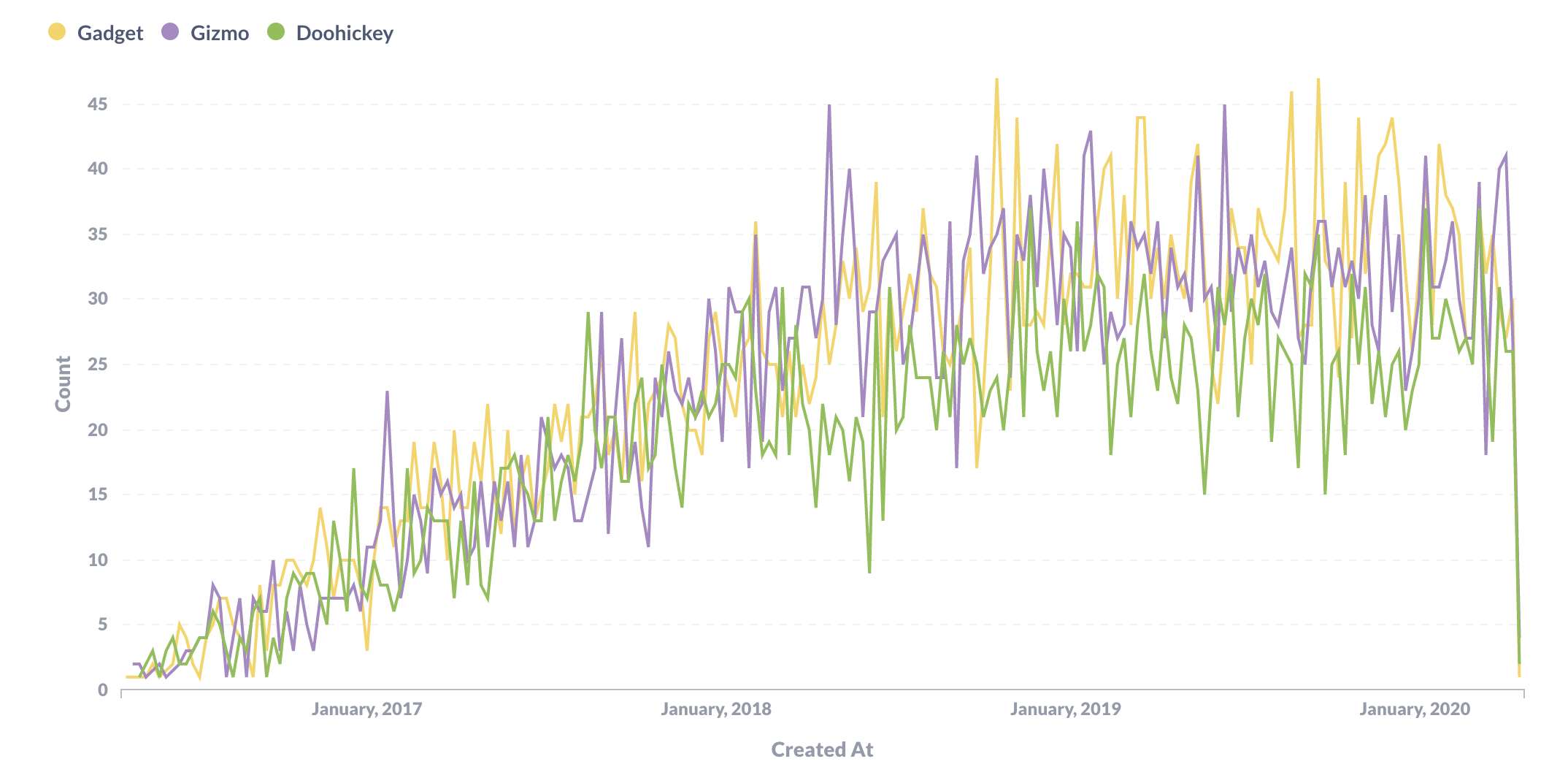
现在假设我们想知道每周售出这三个类别中每个类别的平均产品数量。我们已经计算了按类别划分的每周销售额,所以我们只需返回查询构建器,单击汇总按钮,选择平均值,然后告诉 Metabase 我们想要计算按类别分组的数量的平均值。
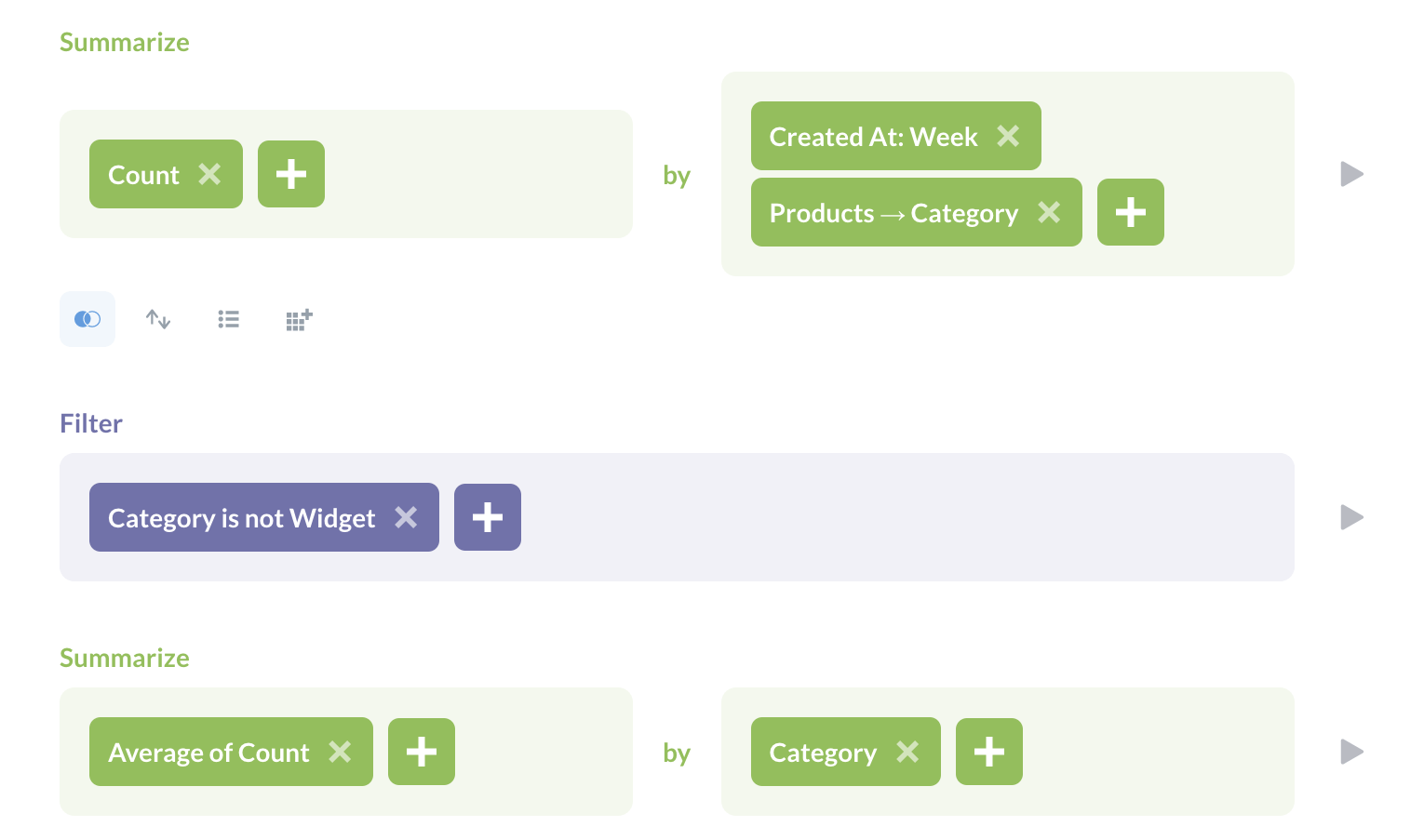
我们的可视化现在正是我们想要的:每周平均售出的 doohickeys、gadgets 和 gizmos 的数量。
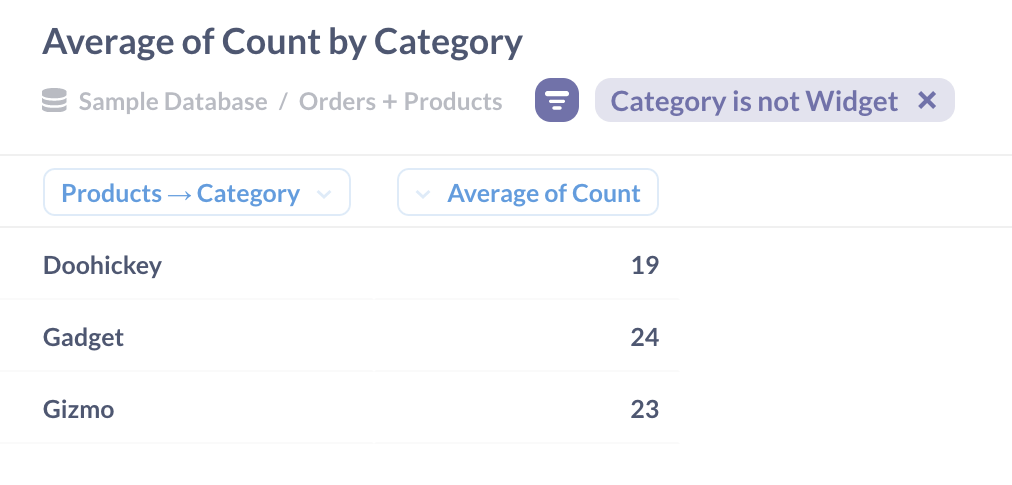
生成此表的完整问题
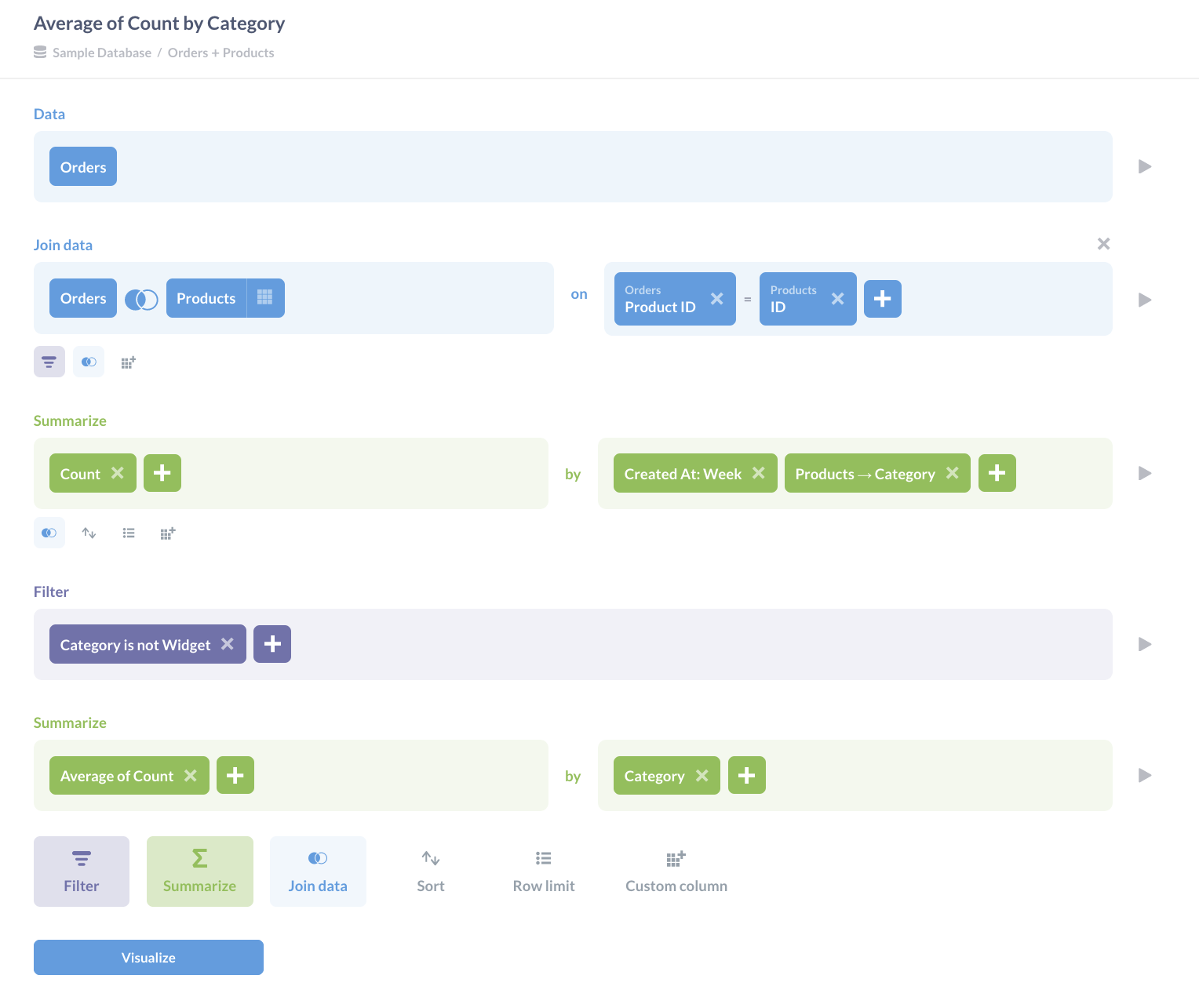
还有其他方法可以计算此结果:例如,我们可以在计算第一个摘要之前筛选掉小工具(大多数分析师认为这是一种最佳实践,因为早期减少数据集的大小可以提高性能)。重要的教训是,我们可以逐步构建洞察,因为每个答案都会引出新问题,并且 Metabase 允许我们按我们想到的顺序逐一添加操作。我们不必提前计划好一切:如果我们发现自己总是从相同的操作开始,我们可以将它们单独保存,如文章 片段、已保存问题和视图中所述。