

编写 SQL 查询的最佳实践
SQL 最佳实践:简要指南,助您写出更优的 SQL 查询。
本文将涵盖数据分析师和数据科学家编写 SQL 查询的一些最佳实践。大部分讨论将针对通用 SQL,但我们也会包含一些关于 Metabase 特定功能的说明,这些功能能让编写 SQL 变得轻而易举。
正确性、可读性,然后是优化:按此顺序
这里适用“过早优化是万恶之源”的标准警告。在确定查询返回了您所需的数据之前,请避免调整 SQL 查询。即使如此,只有当查询经常运行时(例如,为流行的仪表板提供数据),或者查询遍历大量行时,才应优先优化查询。总的来说,在担心性能之前,应优先考虑准确性(查询是否产生了预期的结果)和可读性(其他人是否能轻松理解和修改代码)。
在搜索“针”之前,尽可能缩小“草垛”的范围
可以说,我们已经开始讨论优化了,但目标应该是指示数据库只扫描检索结果所需的最低数量的值。
SQL 的美妙之处在于其声明性。您无需告诉数据库如何检索记录,只需告诉数据库您需要哪些记录,数据库就应该能找出最有效的方法来获取该信息。因此,关于提高查询效率的建议,很多都只是关于教人们如何使用 SQL 中的工具来更精确地表达他们的需求。
我们将回顾查询执行的一般顺序,并在过程中提供一些减少搜索空间的技巧。然后,我们将讨论三个必备工具:索引 (INDEX)、解释 (EXPLAIN) 和 WITH。
首先,熟悉您的数据
在编写任何代码之前,请通过研究元数据来熟悉您的数据,以确保列确实包含您期望的数据。Metabase 中的 SQL 编辑器具有一个方便的数据参考选项卡(可通过**书本图标**访问),您可以在其中浏览数据库中的表,并查看它们的列和连接。
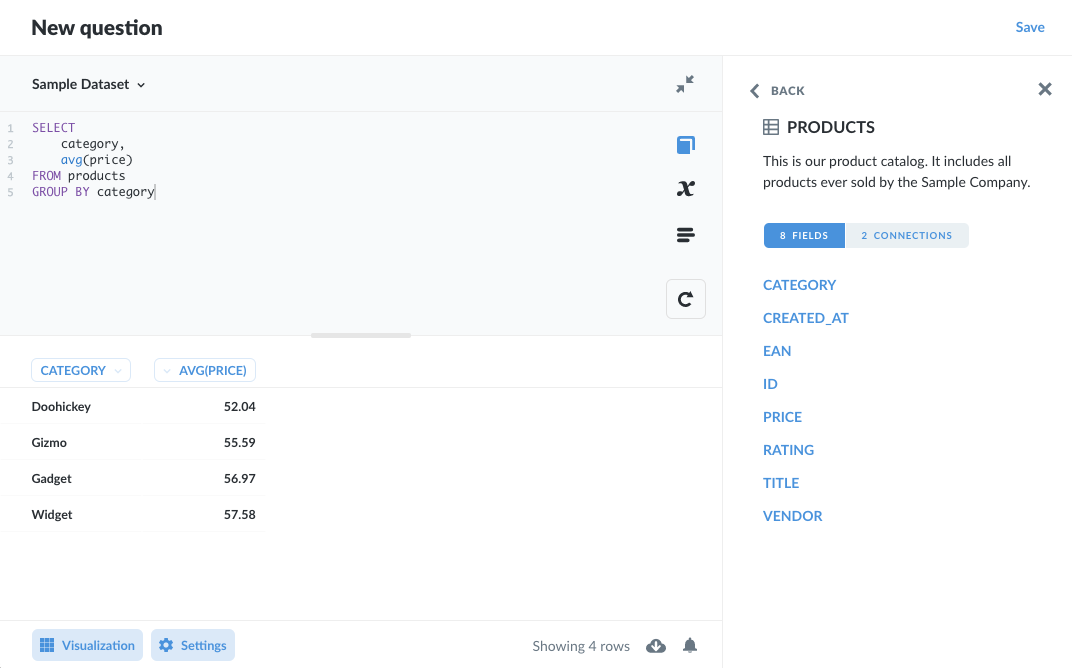
您还可以查看特定列的样本值
Metabase 提供了多种探索数据的方式:您可以对表进行 X-ray、使用查询生成器组合问题,将已保存的问题转换为 SQL 代码,或者基于现有 SQL 查询进行构建。我们在其他文章中对此进行了介绍;目前,让我们来看一下查询的一般工作流程。
开发您的查询
每个人的方法都会有所不同,但以下是一个开发查询时可以遵循的工作流程示例。
- 如上所述,研究列和表的元数据。如果您使用的是 Metabase 的原生(SQL)编辑器,您还可以搜索包含您正在处理的表和列的 SQL 代码的代码片段 (Snippets)。代码片段允许您查看其他分析师是如何查询数据的。或者,您可以从现有 SQL 问题开始查询。
- 要了解表的数值,请对您正在处理的表执行 SELECT * 并限制结果。在细化列(或通过连接添加更多列)时,请保持 LIMIT 的设置。
- 将列缩小到回答问题所需的最小集合。
- 对这些列应用任何过滤器。
- 如果您需要聚合数据,请聚合少量行并确认聚合结果符合您的预期。
- 一旦您的查询返回了所需的结果,请查找查询的各个部分,并将其保存为公共表表达式 (CTE),以封装该逻辑。
- 使用 Metabase,您还可以将代码保存为代码片段 (Snippet),以便在其他查询中共享和重用。
查询执行的一般顺序
在我们深入探讨编写 SQL 代码的个别技巧之前,了解数据库如何执行您的查询非常重要。这与您编写查询时使用的阅读顺序(从左到右,从上到下)不同。查询优化器可以更改以下列表的顺序,但在编写 SQL 时,牢记 SQL 查询的一般生命周期是一个好主意。我们将使用执行顺序来分组后续编写优秀 SQL 的技巧。
这里的经验法则是:您越早在此列表中消除数据,就越好。
- FROM(和 JOIN)获取查询中引用的表。这些表代表了查询指定的最大搜索空间。如果可能,请在继续之前限制此搜索空间。
- WHERE 过滤数据。
- GROUP BY 聚合数据。
- HAVING 过滤不符合条件的聚合数据。
- SELECT 获取列(然后如果调用了 DISTINCT,则进行去重)。
- UNION 将选定的数据合并到结果集中。
- ORDER BY 对结果进行排序。
当然,您特定数据库的查询优化器总是会制定不同的查询计划,所以不要过分纠结于这个顺序。
一些查询指南(非规则)
以下提示是指南,而非规则,旨在帮助您避免麻烦。每个数据库处理 SQL 的方式不同,拥有一套略有不同的函数,并且在优化查询方面采取不同的方法。这还没算上比较传统事务数据库和使用列式存储格式的分析数据库,后者的性能特征差异巨大。
注释您的代码,尤其是“为什么”
通过添加注释来解释代码的各个部分,帮助他人(包括三个月后的自己)。这里最重要的事情是捕捉“为什么”。例如,下面这行代码过滤掉了 ID 大于 10 的订单,这是显而易见的,但它这样做的原因是前 10 个订单用于测试。
SELECT
id,
product
FROM
orders
-- filter out test orders
WHERE
order.id > 10
这里的问题在于,您引入了一点维护开销:如果您更改了代码,您需要确保注释仍然相关且是最新的。但这对于可读的代码来说是微不足道的代价。
SQL FROM 最佳实践
使用 ON 关键字连接表
虽然可以使用 WHERE 子句“连接”两个表(即执行隐式连接,如 SELECT * FROM a,b WHERE a.foo = b.bar),但您应该优先选择显式 JOIN。
SELECT
o.id,
o.total,
p.vendor
FROM
orders AS o
JOIN products AS p ON o.product_id = p.id
主要是为了可读性,因为 JOIN + ON 语法将连接与用于过滤结果的 WHERE 子句区分开来。
为多个表设置别名
查询多个表时,请使用别名,并在您的 select 语句中使用这些别名,这样数据库(和您的读者)就不需要解析哪个列属于哪个表。请注意,如果您的多个表中有同名字段,您将需要使用表名或别名来明确引用它们。
避免
SELECT
title,
last_name,
first_name
FROM fiction_books
LEFT JOIN fiction_authors
ON fiction_books.author_id = fiction_authors.id
优先
SELECT
books.title,
authors.last_name,
authors.first_name
FROM fiction_books AS books
LEFT JOIN fiction_authors AS authors
ON books.author_id = authors.id
这是一个微不足道的例子,但当查询中的表和列数量增加时,您的读者就不必去追踪哪个列在哪个表中了。而且,如果您连接了一个具有歧义列名的表(例如,两个表都包含名为 Created_At 的字段),您的查询可能会失败。
请注意,字段过滤器与表别名不兼容,因此在将过滤器小部件连接到字段过滤器时,您需要删除别名。
SQL WHERE 最佳实践
先用 WHERE 再用 HAVING 过滤
使用 WHERE 子句过滤掉多余的行,这样您就不必首先计算这些值。只有在删除了不相关的行,并对这些行进行聚合和分组之后,才应包含 HAVING 子句来过滤掉聚合结果。
避免在 WHERE 子句中使用列上的函数
在 WHERE 子句中使用列上的函数会严重减慢查询速度,因为函数会使查询不可搜索 (non-sargable)(即,它会阻止数据库使用索引来加速查询)。与使用索引跳到相关行不同,列上的函数会强制数据库对表中的每一行运行该函数。
并且请记住,字符串连接运算符 || 也算是一个函数,所以不要试图通过连接字符串来过滤多个列。请优先使用多个条件。
避免
SELECT hero, sidekick
FROM superheros
WHERE hero || sidekick = 'BatmanRobin'
优先
SELECT hero, sidekick
FROM superheros
WHERE
hero = 'Batman'
AND
sidekick = 'Robin'
优先使用 = 而非 LIKE
情况并非总是如此。了解 LIKE 比较字符,并且可以与通配符(如 %)配对使用,而 = 运算符则比较字符串和数字进行精确匹配。= 可以利用索引列。并非所有数据库都是如此,因为 LIKE 可以使用索引(如果字段存在索引),只要您避免在搜索词前加上通配符 %。这就引出了我们的下一个要点。
避免在 WHERE 语句中使用两端都有通配符的字符串
使用通配符进行搜索可能会很昂贵。优先在字符串末尾添加通配符。在字符串开头添加通配符可能会导致全表扫描。
避免
SELECT column FROM table WHERE col LIKE "%wizar%"
优先
SELECT column FROM table WHERE col LIKE "wizar%"
优先使用 EXISTS 而非 IN
如果您只需要验证一个值是否存在于表中,请优先使用 EXISTS 而非 IN,因为 EXISTS 在找到搜索值后会立即退出,而 IN 会扫描整个表。IN 应用于查找列表中的值。
同样,优先使用 NOT EXISTS 而非 NOT IN。
SQL GROUP BY 最佳实践
按基数降序排列多个分组
如果可能,按基数降序排列 GROUP BY 列。也就是说,先按具有更多唯一值的列(如 ID 或电话号码)分组,然后再按具有较少不同值的列(如州或性别)分组。
SQL HAVING 最佳实践
仅对聚合进行 HAVING 过滤
在 HAVING 之前,先使用 WHERE 子句过滤掉值,然后再聚合和分组这些值。
SQL SELECT 最佳实践
SELECT 列,而不是全选
指定您希望包含在结果中的列(尽管在初次探索表时使用 * 也可以,只需记得限制您的结果)。
SQL UNION 最佳实践
优先使用 UNION ALL 而非 UNION
如果重复项不是问题,UNION ALL 不会丢弃它们,并且由于 UNION ALL 不需要去除重复项,因此查询将更有效率。
SQL ORDER BY 最佳实践
尽可能避免排序,尤其是在子查询中
排序代价高昂。如果您必须排序,请确保您的子查询不会不必要地排序数据。
SQL INDEX 最佳实践
本节内容面向数据库管理员(以及一个在本篇文章中无法完全涵盖的主题)。当遇到数据库查询性能问题时,人们最常遇到的问题之一是缺乏足够的索引。
您应该为哪些列添加索引通常取决于您过滤数据的列(即,哪些列通常会出现在您的 WHERE 子句中)。如果您发现您总是根据一组公共列进行过滤,那么您应该考虑为这些列添加索引。
添加索引
为外键列和经常查询的列添加索引可以显著减少查询时间。下面是一个创建索引的示例语句。
CREATE INDEX product_title_index ON products (title)
有不同类型的索引可用,最常见的索引类型使用 B 树来加速检索。查看我们关于让仪表板更快的文章,并查阅您的数据库文档,了解如何创建索引。
使用部分索引
对于特别大的数据集或不平衡的数据集,其中某些值范围出现得更频繁,请考虑创建一个带 WHERE 子句的索引来限制被索引的行数。部分索引也可能对日期范围有用,例如,如果您只想索引过去一周的数据。
使用复合索引
对于在查询中通常一起使用的列(例如 last_name, first_name),请考虑创建复合索引。语法与创建单个索引类似。例如:
CREATE INDEX full_name_index ON customers (last_name, first_name)
EXPLAIN
查找瓶颈
某些数据库,如 PostgreSQL,可以根据您的 SQL 代码提供对查询计划的见解。只需在您的代码前加上 EXPLAIN ANALYZE 关键字。您可以使用这些命令来检查您的查询计划并查找瓶颈,或者比较同一查询不同版本之间的计划,以查看哪个版本更有效。
下面是一个使用 PostgreSQL 可用的 dvdrental 示例数据库的查询示例。
EXPLAIN ANALYZE SELECT title, release_year
FROM film
WHERE release_year > 2000;
以及输出
Seq Scan on film (cost=0.00..66.50 rows=1000 width=19) (actual time=0.008..0.311 rows=1000 loops=1)
Filter: ((release_year)::integer > 2000)
Planning Time: 0.062 ms
Execution Time: 0.416 ms
您将看到计划时间、执行时间所需的毫秒数,以及成本、行数、宽度、时间、循环次数、内存使用量等。阅读这些分析在某种程度上是一门艺术,但您可以利用它们来识别查询中的问题区域(例如,嵌套循环,或可以受益于索引的列),并在您进行优化时。
这是 PostgreSQL 关于使用 EXPLAIN 的文档。
WITH
使用公共表表达式 (CTE) 来组织您的查询
使用 WITH 子句将逻辑封装到公共表表达式 (CTE) 中。下面是一个查询示例,该查询查找 2019 年平均每售出单位收入最高的产品,以及最大值和最小值。
WITH product_orders AS (
SELECT o.created_at AS order_date,
p.title AS product_title,
(o.subtotal / o.quantity) AS revenue_per_unit
FROM orders AS o
LEFT JOIN products AS p ON o.product_id = p.id
-- Filter out orders placed by customer service for charging customers
WHERE o.quantity > 0
)
SELECT product_title AS product,
AVG(revenue_per_unit) AS avg_revenue_per_unit,
MAX(revenue_per_unit) AS max_revenue_per_unit,
MIN(revenue_per_unit) AS min_revenue_per_unit
FROM product_orders
WHERE order_date BETWEEN '2019-01-01' AND '2019-12-31'
GROUP BY product
ORDER BY avg_revenue_per_unit DESC
WITH 子句使代码具有可读性,因为主查询(您实际要查找的内容)不会被一个长子查询打断。
您还可以使用 CTE 来提高 SQL 的可读性,例如,如果您的数据库中的字段名称不方便,或者需要一些数据处理才能获得有用数据。例如,CTE 在处理 JSON 字段时很有用。下面是一个从用户事件的 JSON 块中提取和转换字段的示例。
WITH source_data AS (
SELECT events->'data'->>'name' AS event_name,
CAST(events->'data'->>'ts' AS timestamp) AS event_timestamp
CAST(events->'data'->>'cust_id' AS int) AS customer_id
FROM user_activity
)
SELECT event_name,
event_timestamp,
customer_id
FROM source_data
或者,您可以将子查询保存为代码片段 (Snippet)。
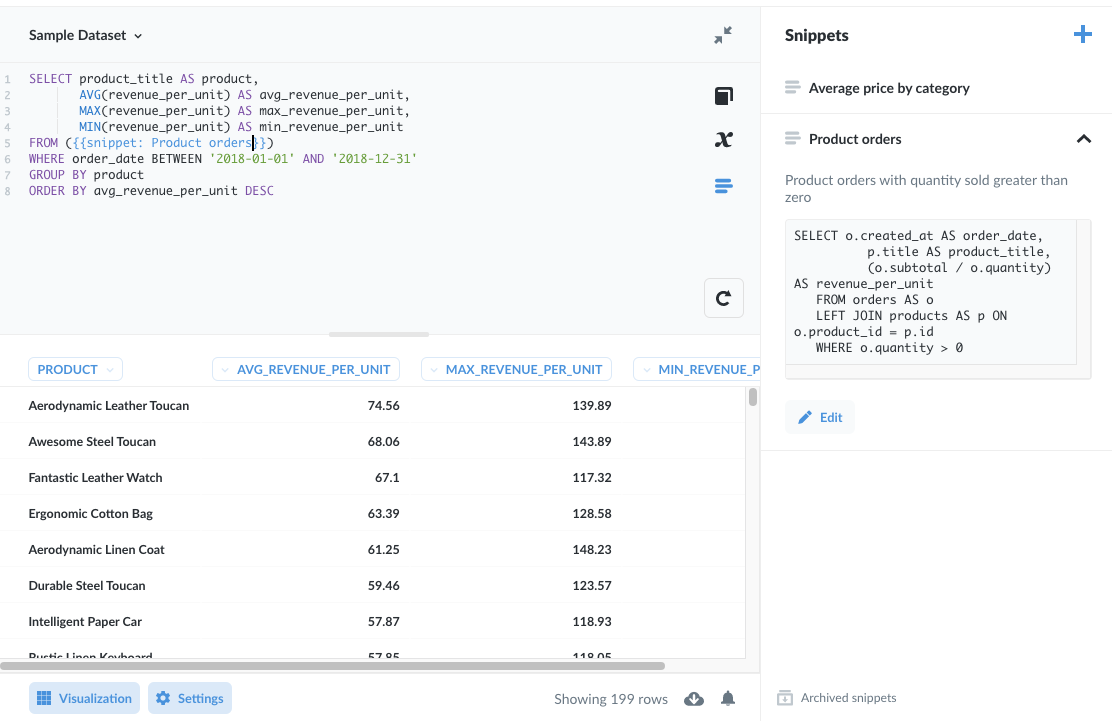
是的,正如您可能预期的那样,Aerodynamic Leather Toucan 获得了最高的平均每单位销售收入。
使用 Metabase,您甚至不必使用 SQL
SQL 非常强大。但 Metabase 的查询生成器 (Query Builder)也同样强大。您可以使用 Metabase 的图形界面来连接表、过滤和汇总数据、创建自定义列等。并且通过自定义表达式,您几乎可以处理所有分析用例,而无需用到 SQL。使用**查询生成器**组合的问题还可以受益于自动钻取 (drill-through),这使得图表的查看者可以通过点击来探索数据,这是用 SQL 编写的问题所不具备的功能。
明显的错误或遗漏?
SQL 有大量的书籍,所以我们这里只是浅尝辄止。您可以在我们的论坛上与其他 Metabase 用户分享您的 SQL 魔法秘诀。