

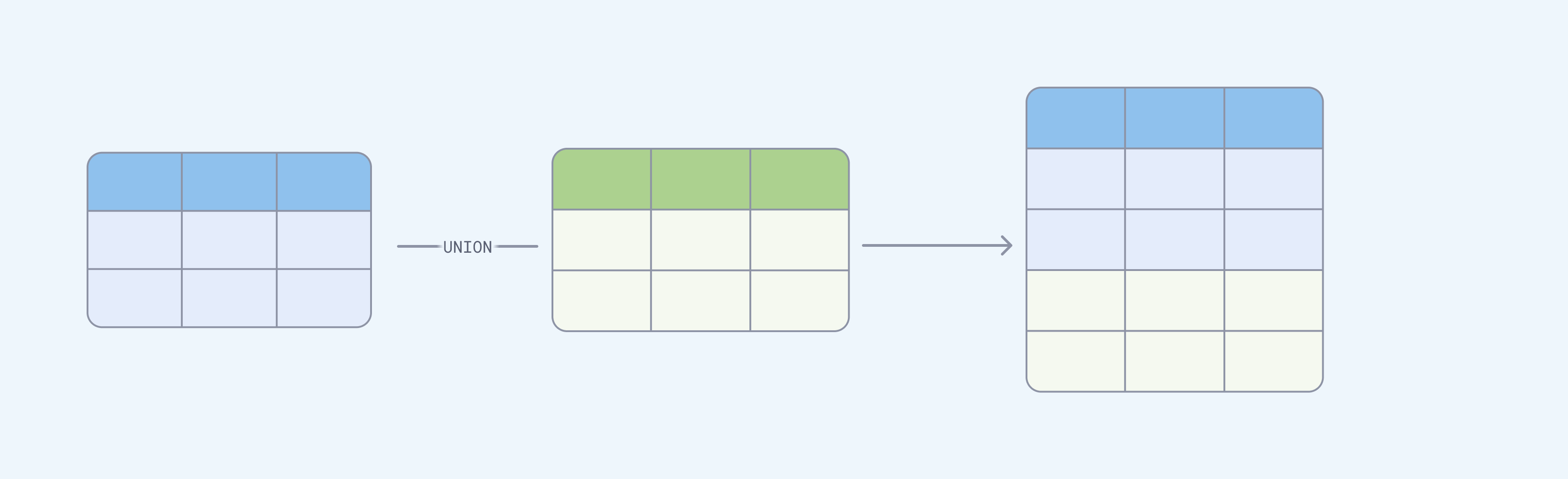
使用 SQL UNION 合并表
如何使用 SQL UNION 合并来自两个表的行。
什么是 SQL UNION
假设您想查看销售管道每个阶段的人数,但存在一个问题:潜在客户和候选人存在于一个表中(尽管有不同的过滤器),试用数据存在于另一个表中,而客户数据存在于第三个表中。您需要统计所有这些信息并将其合并到一个表中,但它们都有不同的逻辑并使用不同的来源。SQL 有一个特殊的运算符 UNION,它允许您合并来自不同表的查询结果。
SQL 中有两个 UNION 运算符 - UNION 和 UNION ALL。本文的大部分内容同时适用于 UNION 和 UNION ALL。
在深入学习高级 SQL 之前需要快速复习吗?请查看我们的SQL 速查表,了解核心命令和语法。它也非常适合与开始进行数据分析的同事分享。
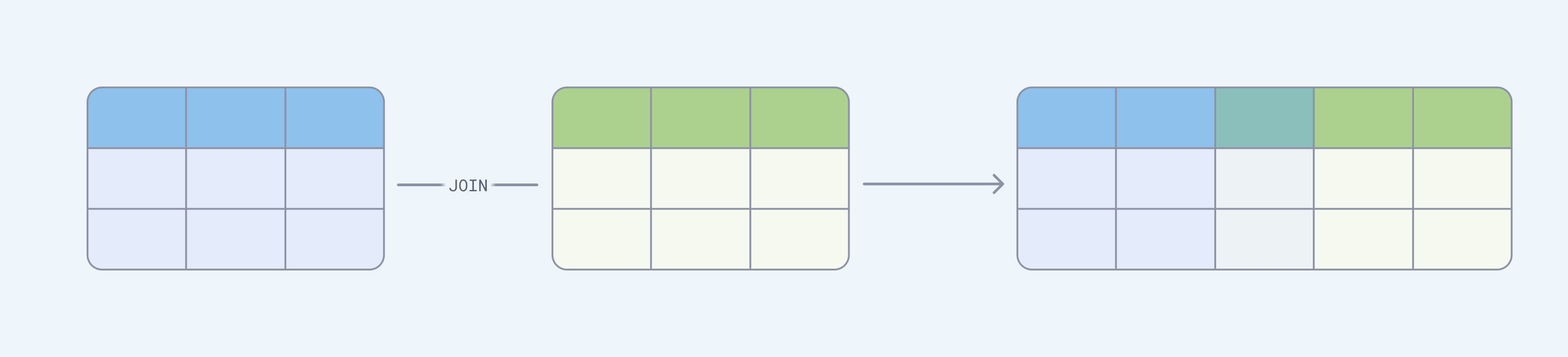
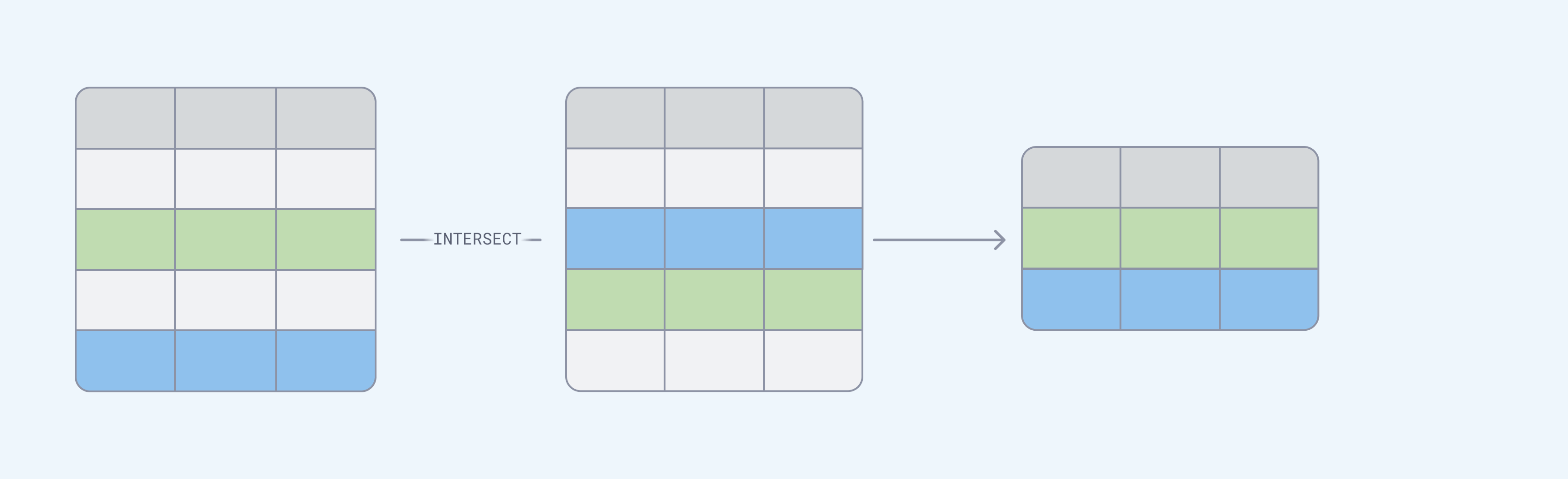
UNION 与 JOIN 和 INTERSECT:何时使用它们
在 SQL 中(至少)有三种合并查询结果的方法:JOIN、UNION 和 INTERSECT。它们有不同的用途
- 当您想向结果中添加更多行时,请使用
UNION。 - 当您想向结果中添加更多列时,请使用
JOIN。 - 当您想查找表之间的公共行集时,请使用
INTERSECT。
使用 SQL UNION 合并查询结果
要查看 UNION 的作用,让我们运行以下 SQL 查询(例如,您可以在 Metabase 中运行它 )
SELECT "Kitten" as pet_type, 0.5 as pet_age
UNION ALL
SELECT "Puppy", 2
UNION ALL
SELECT "Bird", 17;
结果是
| pet_type | pet_age |
| -------- | ------- |
| Kitten | 0.5 |
| Puppy | 2 |
| Bird | 17 |
发生了什么
- SQL 会执行
UNION子句之间的每个SELECT查询。 - 堆叠结果的行。
- 使用第一个查询中的别名(
AS "Kitten")作为列标题。
要 union 的查询(这是一个词吗?..)不需要返回单行 - 查询可以包含过滤器、分组、CTE 等。例如,假设您有两个查询
第一个查询
SELECT
breed,
count(*)
FROM kittens
GROUP BY breed;
第一个查询返回
| BREED | COUNT(*) |
| ------------------ | --------- |
| Domestic shorthair | 23 |
| Domestic longhair | 10 |
| Siamese | 3 |
第二个查询
SELECT
breed,
count(*)
FROM puppies
GROUP BY breed;
第二个查询返回
| BREED | COUNT(*) |
| ------------- | --------- |
| Beagle | 3 |
| Borzoi | 1 |
| Corgi | 5 |
| Very good boy | 37 |
那么这些查询的 union 是
-- First query
SELECT
breed,
count(*)
FROM kittens
GROUP BY color
UNION ALL
-- Second query
SELECT
breed,
count(*)
FROM puppies
GROUP BY color
以及 UNION ALL 查询的结果
| BREED | COUNT(*) |
| ------------------ | --------- |
| Domestic shorthair | 23 |
| Domestic longhair | 10 |
| Siamese | 3 |
| Beagle | 3 |
| Borzoi | 1 |
| Corgi | 5 |
| Very good boy | 37 |
因此 UNION ALL 只是逐个执行了查询,并堆叠了结果。在 UNION (ALL) 处理列名、列顺序和列数据类型方面有一些细微之处,但在最基本的层面上,它只是堆叠行。
UNION ALL 获取所有行,UNION 尝试去重行
UNION ALL获取查询结果并将其堆叠在一起。UNION(不带ALL)执行相同的操作,但也会尝试去重行。
例如,假设您有两个查询
第一个查询
SELECT
color,
count(*)
FROM kittens
GROUP BY color;
| COLOR | COUNT(*) |
| ------ | --------- |
| Orange | 18 |
| Black | 10 |
| White | 8 |
第二个查询
SELECT
color,
count(*)
FROM puppies
GROUP BY color;
| COLOR | COUNT(*) |
| ----- | --------- |
| Black | 10 |
| Brown | 23 |
| White | 15 |
那么 UNION ALL 的结果是
| COLOR | COUNT(*) |
| ------ | --------- |
| Orange | 18 |
| Black | 10 |
| White | 8 |
| Black | 10 |
| Brown | 23 |
| White | 15 |
一些颜色(“黑色”和“白色”)有多行。 UNION 将尝试去重重复的行
| COLOR | COUNT(*) |
| ------ | --------- |
| Orange | 18 |
| Black | 10 |
| White | 8 |
| Brown | 23 |
| White | 15 |
行 | Black | 10 | 出现在两个查询的结果中,因此 UNION 将删除其中一个行。至于 White 行:即使颜色 White 出现两次,这些行也不是重复的。一个行是 | White | 8 |,另一个是 | White | 10 |,所以 UNION 保留两者。
SQL UNION 在检索查询结果后执行去重,因此如果您有任何 LIMIT 或 ORDER 子句在单个查询中,UNION 的结果可能不会遵守这些。
为什么(一般来说)您应该优先使用 UNION ALL 而不是 UNION
当您使用 UNION 而不是 UNION ALL 时,SQL 会尝试去重结果 - 即使没有重复项。去重可能需要很长时间,因为 SQL 需要遍历每个查询中的所有记录。
只有当您确实需要删除重复行时,才使用 UNION。
SQL UNION 的完整表
您无法 UNION ALL 普通表。您只能 union 查询结果:这样做无效
--this won't work:
SELECT * FROM (
kittens
UNION ALL
puppies
);
如果您想将多个表堆叠在一起,您需要选择每个表的所有记录
-- UNION of two full tables
SELECT * FROM kittens
UNION ALL
SELECT * FROM puppies;
(虽然通常您应该避免在 UNION 中使用 SELECT *,而是显式指定列,请参阅Union 的表必须具有相同的列数)。
UNION ALL 示例:使用 SQL 构建销售漏斗
假设您将销售漏斗中的信息存储在三个表中
leads表,包含销售线索信息prospects表,包含候选人数据customers表,包含(您猜对了)客户信息
您可以对这些表中的每一个运行 COUNT(*) 来独立查找潜在客户、候选人和客户的数量,但将这些信息合并到一个表中会更有帮助(例如,如果您想了解转化率)。这就是 UNION ALL 可以派上用场的地方
SELECT COUNT(*) from leads
UNION ALL
SELECT COUNT(*) from prospects
UNION ALL
SELECT COUNT(*) from customers;
此查询返回类似如下的内容
| COUNT(*) |
| --------- |
| 1749 |
| 832 |
| 562 |
因此,您可以查看查询每个阶段的下降情况 - 例如,大约 48% 的潜在客户会成为候选人。
我们在此使用 UNION ALL 来加快查询速度,同时也确保重复项不会被排除:例如,如果您有一个转化率为 100% 的杀手级应用程序,并且您的候选人数量与客户数量相同,那么使用 UNION 而不是 UNION ALL 将意味着那些重复的客户数量将被删除。
这些结果有两个问题:首先,列名 COUNT(*) 没有帮助,其次,数字缺乏很多上下文:哪个对应哪个阶段?因此,让我们添加列名和存储阶段名称的附加字段
SELECT 'Leads' as stage, COUNT(*) as ct from leads
UNION ALL
SELECT 'Prospects', COUNT(*) from prospects
UNION ALL
SELECT 'Customers', COUNT(*) from customers;
| stage | ct |
| --------- | ---- |
| Leads | 1749 |
| Prospects | 832 |
| Customers | 562 |
请注意,我们只需要在 UNION 的第一个查询中添加列名 - 这是因为SQL UNION 只获取第一个查询的列名。
UNION ALL 示例:使用 SQL 跟踪用户流
为了举一个更复杂的例子,假设您正在经营一家电子商务网站,并且您想跟踪用户流动的过程
- 目录访问:查看产品目录。
- 产品访问:进入特定产品的页面。
- 添加到购物车:他们几乎把钱给你了。
- 订单。他们实际上给了你钱。
您的数据分布在多个表中
- 网站页面(如目录页面或产品页面)的访问量在
page_views表中。 - 按钮点击等事件单独跟踪在
events表中。 - 实际客户订单在
orders表中。
您可以计算产品列表页面上的总访问量,如下所示
-- Count all views to the catalog page
SELECT
COUNT(*)
FROM page_views
WHERE
page_url = 'https://www.whskr.co/catalog'
接下来,您想计算访问特定产品页面的次数 - 但不是所有的访问,只是来自目录页面的访问(而不是,例如,搜索或直接链接)。这使用了相同的 page_views 表,但具有不同的过滤器
-- Count views to the product page coming from the catalog page
SELECT
COUNT(*)
FROM page_views
WHERE
page_url = 'https://www.whskr.co/product/smart-mouse-1234567'
AND referer_url = 'https://www.whskr.co/catalog'
接下来,您想计算将产品添加到购物车的人数,因此您过滤所有交互事件。这可能看起来像这样
-- Clicks on "Add to cart" button on the product page
SELECT
COUNT(*)
FROM events
WHERE
event_type = 'button_clicked'
AND event_subtype = 'add-to-cart'
AND source_page = 'https://www.whskr.co/product/smart-mouse-1234567'
最后,您想知道人们订购该产品的总次数
-- Number of orders for the product
SELECT COUNT(*)
FROM orders
WHERE product_id = 1234567
(这里我们假设下订单的唯一方法是从产品页面。)
现在,您想将所有这些计数放入一个表中,以便比较每个人通过每个阶段的数量。您还想添加一个标识每个阶段的列。这就是 UNION (ALL) 的用武之地
-- Count all views to the catalog page
SELECT
'Catalog visits' as stage,
COUNT(*)
FROM page_views
WHERE
page_url = 'https://www.whskr.co/catalog'
UNION ALL
-- Count views to the product page coming from the catalog page
SELECT
'Product visits',
COUNT(*)
FROM page_views
WHERE
page_url = 'https://www.whskr.co/product/smart-mouse-1234567'
AND referer_url = 'https://www.whskr.co/catalog'
UNION ALL
-- Clicks on "Add to cart" button on the product page
SELECT
'Add to cart',
COUNT(*)
FROM interaction_events
WHERE
event_type = 'button_clicked'
AND event_subtype = 'cart'
AND source_page = 'https://www.whskr.co/product/smart-mouse-1234567'
UNION ALL
-- Number of orders for the product
SELECT
'Orders',
COUNT(*)
FROM orders
WHERE product_id = 1234567
在这里,我们将 page_views 表上的两个查询与两个不同的过滤器、一个 events 表上的查询和一个 orders 表上的查询结合起来。我们正在使用 UNION ALL,因为这种情况不需要去重数据。
结果将类似于
| stage | COUNT(*) |
| -------------- | --------- |
| Catalog visits | 5842 |
| Product visits | 851 |
| Add to cart | 592 |
| Orders | 346 |
UNION ALL 示例:合并历史表中的数据
有时,当表很大且查询耗时很长时,人们会按日期将一个大表分成几个表。例如,您可能有一个包含每年数据的单独表,例如包含 2023、2024、2025 年数据的表…… 2025 年,您可能不会不断查询例如 1998 年的数据,因此除非绝对必要,否则无需让数据库处理这些数据。
但有时在这样的设置中,您确实需要检索前几年的数据,这就是 UNION (ALL) 可以派上用场的地方。例如,如果您想获取所有年份的所有订单 ID、日期、总额,您可以编写如下查询(假设世界始于 2023 年)
SELECT id, created_at, total FROM orders_2023
UNION ALL
SELECT id, created_at, total FROM orders_2024
UNION ALL
SELECT id, created_at, total FROM orders_2023
UNION ALL 示例:添加汇总行
假设您正在使用以下查询按类别计算产品数量
SELECT
category,
COUNT(*) as ct
FROM products
GROUP BY category;
结果如下
| CATEGORY | ct |
| --------- | --- |
| Doohickey | 42 |
| Gadget | 53 |
| Gizmo | 51 |
| Widget | 54 |
您可以使用 UNION ALL 添加包含记录总数的行
-- Query results
SELECT
category,
COUNT(*) as ct
FROM products
GROUP BY category
ORDER BY ct
UNION ALL
-- Total row
SELECT
'Total',
COUNT(*)
FROM products;
结果将如下所示
| CATEGORY | ct |
| --------- | --- |
| Doohickey | 42 |
| Gadget | 53 |
| Gizmo | 51 |
| Widget | 54 |
| Total | 200 |
您可以使用相同的想法添加其他类型的汇总。例如,您可以添加一行用于类别之间的平均计数
WITH ct_by_category AS (
SELECT
category,
COUNT(*) as ct
FROM products
GROUP BY category
)
SELECT category, ct FROM ct_by_category
UNION ALL
SELECT 'Average', AVG(ct) FROM ct_by_category;
在这里,我们将COUNT 提取到一个CTE 中,以使查询更简洁。
SQL UNION 如何工作
SQL UNION (ALL) 假设您知道自己在做什么,并且不会阻碍您 - 但也不会试图变得聪明并帮助您。SQL UNION (ALL) 只会执行您正在 union 的查询(是的,现在这是一个词了),并尝试堆叠结果行。如果出现问题 - 例如列数不同或列类型不匹配 - UNION (ALL) 将直接放弃。
以下是一些需要注意的事项
SQL UNION 获取第一个查询的列
UNION (ALL) 将从第一个查询获取列名,并忽略后续查询中的任何列名。
因此,假设您有一个这样的查询
SELECT 'Kitten' as pet_type, 0.5 as pet_age
UNION ALL
SELECT 'Bird' as category, 17 as age_in_years;
结果将是
| pet_type | pet_age |
| -------- | ------- |
| Kitten | 0.5 |
| Bird | 17 |
SQL UNION (ALL) 不会创建新列。因此,只要列的数量和数据类型匹配,SQL UNION (ALL) 就会简单地堆叠行。这可能不是您想要的!
例如,来看以下查询
SELECT 'Kitten' as pet_type, 0.5 as pet_age
UNION ALL
SELECT 'Senior Software Engineer' as job_title, 32768 as favorite_number;
您想要的结果
| pet_type | pet_age | job_title | favorite_number |
| -------- | ------- | ------------------------ | --------------- |
| Kitten | 0.5 | | |
| | | Senior Software Engineer | 32768 |
但查询实际返回的结果
| pet_type | pet_age |
| ------------------------ | ------- |
| Kitten | 0.5 |
| Senior Software Engineer | 32768 |
如果您想保留不同的列并将 null 值插入到没有相应数据的单元格中,您可以尝试使用全外连接。
SQL UNION 列必须按相同顺序排列
如果您希望 SQL UNION (ALL) “匹配”的列,您必须在每个查询中以相同的顺序放置它们。SQL UNION (ALL) 将只尝试将所有第一个列的值放在一起,所有第二个列的值放在一起,依此类推,并且不会尝试基于名称、类型或其他特征进行匹配。
例如,在这里,查询创建者可能打算有两个列 pet_type 和 pet_age,但两个查询中的列顺序不同
-- This will cause an error in most databases:
SELECT 'Kitten' as pet_type, 0.5 as pet_age
UNION ALL
SELECT 17 as pet_age, 'Bird' as pet_type;
您可能期望的结果
-- Expected, but not actual the result of the query above
| pet_type | pet_age |
| -------- | ------- |
| Kitten | 0.5 |
| Bird | 17 |
但实际结果将取决于数据库。大多数数据库会给出错误,类似于
ERROR: Data conversion error converting "Kitten";
这是在 Metabase 示例数据库上看到的错误消息 - 其他数据库可能会给出不同的错误消息。
一些其他数据库(如 MySQL)会给出
| pet_type | pet_age |
| -------- | ------- |
| Kitten | 0.5 |
| 17 | Bird |
但结果永远不会是
-- Can't get this result with query above
| pet_type | pet_age |
| -------- | ------- |
| Kitten | 0.5 |
| Bird | 17 |
这里发生了什么?
-
首先,SQL
UNION不关心第二个查询中的列名,因此它会忽略它们,并尝试将'Kitten'和17组合到一个列中,将0.5和'Bird'组合到另一个列中。 -
然后,由于类型不匹配 -
'Kitten'是字符串而17是数字 - 大多数数据库会直接拒绝该操作。MySQL 稍微宽容一些,会将17转换为字符串'17'。
当类型不不匹配时,这种行为尤其令人困惑,因此没有错误。例如,SQL 将愉快地执行以下查询而不会出错,因为所有列都是字符串
-- This query will not error out but will produce unexpected results
SELECT 'Kitten' as pet_type, 'Mittens' as pet_name
UNION ALL
SELECT 'Professor Beakman' as pet_name, 'Bird' as pet_type;
并返回
| pet_type | pet_name |
| ----------------- | -------- |
| Kitten | Mittens |
| Professor Beakman | Bird |
这可能不是您想要的。
Union 的表必须具有相同数量的列
如果查询结果的列数不同,UNION (ALL) 将不起作用 - 即使列之间存在重叠。例如,以下查询无论 ... 中是什么都无法正常工作。
--- This query won't work
SELECT category, week_num, COUNT(*) FROM ...
UNION ALL
SELECT category, COUNT(*) FROM ...
第一个查询返回三列,第二个查询返回两列,因此 UNION ALL 无法堆叠这些结果。它不会为缺少的列创建一个带有 null 值的附加列。相反,您的数据库将返回一个错误,类似于
ERROR: each UNION query must have the same number of columns
当您使用 SELECT * 而不是显式指定列时,这可能会导致意外错误,尤其是在您从中选择 FROM 的内容可能会更改的情况下。假设您有单独的表来存储每年的订单信息:orders_2024、orders_2025 等。要获取所有年份的所有订单,您可以运行
SELECT * FROM orders_2023
UNION ALL
SELECT * FROM orders_2024
UNION ALL
SELECT * FROM orders_2025;
但如果有人向 orders_2025 添加新列,此查询将开始失败。
因此,在使用 UNION (ALL) 时,请务必明确指定要选择的列(这对于编写任何 SELECT 语句来说都是一个好习惯,无论是否使用 UNION)。
SELECT id, created_at, amount FROM orders_2023
UNION ALL
SELECT id, created_at, amount FROM orders_2024
UNION ALL
SELECT id, created_at, amount FROM orders_2025;
列数据类型在 SQL UNION 中必须匹配
查询结果中的列类型必须匹配。例如,在 UNION ALL 中,每一行的第一列都必须是数字,第二列都必须是文本,依此类推。如果类型不匹配,例如,一个查询的第一列是文本,而另一个查询的第一列是数字,那么 UNION 查询可能无法正常工作。是否能工作取决于数据库和数据类型。大多数数据库在类型不完全匹配时会显示错误。像 MySQL 这样的数据库会尝试进行类型转换(例如,数字转字符串),但如果无法转换,则会显示错误。隐式类型转换也可能导致意外的结果。
例如,来看以下查询
SELECT true
UNION ALL
SELECT DATE '2025-04-19'
在这里,我们尝试将布尔值和日期堆叠在一起。大多数数据库(例如 PostgreSQL)会直接给出错误。
MySQL 则会返回
| TRUE |
| ---------- |
| 1 |
| 2025-04-19 |
在这里,MySQL 将 TRUE 作为列标题,因为我们没有提供其他选项。如果您查看返回列的数据类型,会发现它现在是一个 VARCHAR 列。因此,MySQL 将 true 和 2025-04-19 都转换为了字符串,而 true 被转换为字符串值 1,因为 MySQL 实际上没有布尔数据类型,而是将布尔值存储为整数 1 或 0,在这个查询中,MySQL 也将其转换为字符串。因此,您可以看到这可能会多么令人困惑!请确保 UNION 中的列数据类型匹配,以避免出现此类意外结果。