

在 SQL 中处理日期
使用 SQL 按时间段对结果进行分组,比较周与周的总计,并找出两个日期之间的持续时间。
我们将介绍处理 SQL 日期时的三个常见场景。我们将使用 Metabase 随附的示例数据库,以便您可以跟随操作,并使用适用于许多数据库的常见 SQL 函数和技术。我们假设您已不是第一次进行 SQL 查询,并且正在寻求提升。但即使您刚开始,也应该能学到一些技巧。
本文档基于预定义的示例数据集,但您也可以使用AI 数据集生成器生成自己的练习数据。
| 场景 | 示例 |
|---|---|
| 按时间段对结果进行分组 | 每周有多少用户创建了账户? |
| 比较周与周的总计 | 本周的订单量与上周相比如何? |
| 找出两个日期之间的持续时间 | 客户创建账户到首次下单之间的天数是多少? |
按时间段对结果进行分组
我们经常想问这样的问题:每月有多少客户注册?或每周下了多少订单?在这里,我们将遍历结果表,计算行数,并将这些计数按时间段进行分组。
示例:每周有多少用户创建了账户?
在这里,我们要返回两列
| WEEK | ACCOUNTS CREATED |
|------|------------------|
| ... | ... |
让我们来看一下我们的 People 表。我们可以 SELECT * FROM people LIMIT 1 来查看字段列表,或者简单地单击书形图标来查看我们正在使用的数据库中表的元数据。
由于我们对客户创建账户的时间感兴趣,因此我们需要 created_at 字段,根据我们的数据参考,该字段是“用户记录创建的日期。也称为用户的‘加入日期’”。
我们需要对这些账户创建进行分组,但不是按日期分组,而是按周分组。要查看每个 created_at 日期属于哪一周,我们将使用 DATE_TRUNC 函数。
DATE_TRUNC 允许您将时间戳四舍五入(“截断”)到您关心的粒度:周、月等。DATE_TRUNC 接受两个参数:文本和一个时间戳,并返回一个时间戳。第一个文本参数是时间段,在本例中是‘week’,但我们可以指定不同的粒度,例如 month、quarter 或 year(请检查您的数据库关于DATE_TRUNC 的文档以查看选项)。在此,我们将编写 DATE_TRUNC('week', created_at),它将返回每周一的日期。顺便说一下,SQL 是不区分大小写的,所以您可以根据自己的喜好设置代码的大小写(date_trunc 也可以,或者如果您正在讽刺地查询,也可以使用 DaTe_TrUnc)。
我们还将为结果使用别名,以便为列提供更具体的名称。例如,使用 AS 关键字,我们将把 Count(*) 显示为 accounts_created。
SELECT
DATE_TRUNC('week', created_at) AS week,
COUNT(*) AS accounts_created
FROM
people
GROUP BY
week
ORDER BY
week
它返回
| WEEK | ACCOUNTS_CREATED |
|---------|------------------|
| 4/18/16 | 13 |
| 4/25/16 | 17 |
| 5/2/16 | 17 |
| ... | ... |
我们可以将此结果可视化为折线图
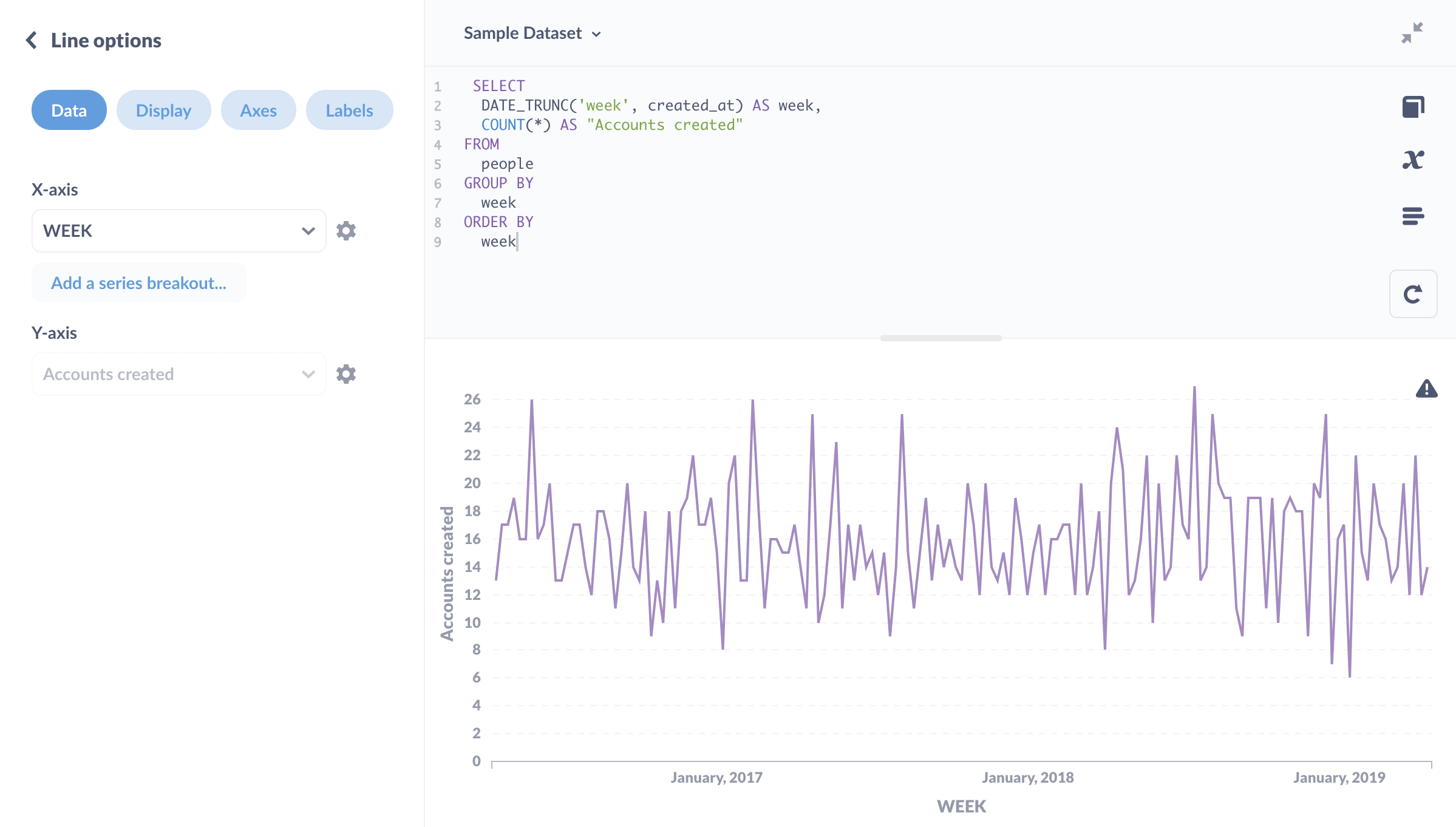
从随机数据集中看,这看起来基本符合预期。
比较周与周的总计
您常常希望看到计数从一周到下一周的变化情况,这可以通过将表自身连接起来,并将每周与前一周进行比较来实现。
示例:订单与上周相比如何?
在这里,我们要查找的是周、该周的订单数以及周与周的变化(订单是增加了、减少了,还是保持不变?)。
| WEEK | COUNT_OF_ORDERS | WOW_CHANGE |
|---------|-----------------|------------|
| ... | ... | ... |
要获取此数据,我们首先需要一个列出每周订单计数的表。我们将对 Orders 表执行与之前对 People 表相同的操作:使用 DATE_TRUNC 按周对订单计数进行分组。
SELECT
DATE_TRUNC('week', orders.created_at) AS week,
COUNT(*) AS order_count
FROM
orders
GROUP BY
week
这给了我们
| WEEK | ORDER_COUNT |
|----------|-------------|
| 7/1/2019 | 115 |
| 7/2/2018 | 119 |
| 7/3/2017 | 78 |
| ... | ... |
我们将使用这些结果来构建其余的查询。现在我们需要做的是,取每周的订单计数(我们将称之为 w1),然后减去前一周的计数(我们将称之为 w2)。这里的挑战是,为了执行减法,我们需要以某种方式将每周的计数与前一周的计数放在同一行。
以下是我们实现的方法
- 将我们的结果包装在通用表表达式 (CTE) 中。
- 通过偏移连接 1 周来将该 CTE 与自身连接
- 从每周的总计中减去上一周的订单计数总计,以获得周与周的变化。
我们将使用 WITH 关键字将上面的查询变成一个通用表表达式(CTE)。本质上,CTE 是一种为中间结果分配变量的方法,然后我们可以将其视为数据库中的实际表(如 Orders 或 Table)。我们将结果表称为 order_count_by_week。然后,我们将使用此表并将其自身连接,但带有偏移量:其行向后移动一周。
这是带有偏移连接的查询
WITH order_count_by_week AS (
SELECT
DATE_TRUNC('week', orders.created_at) AS week,
COUNT(*) AS order_count
FROM
orders
GROUP BY
week
)
SELECT
*
FROM
order_count_by_week w1
LEFT JOIN order_count_by_week w2 ON w1.week = DATEADD(WEEK, 1, w2.week)
ORDER BY
w1.week
此查询的输出结果为
| WEEK | ORDER_COUNT | WEEK | ORDER_COUNT |
|-----------|-------------|-----------|-------------|
| 4/25/2016 | 1 | | |
| 5/2/2016 | 3 | 4/25/2016 | 1 |
| 5/9/2016 | 3 | 5/2/2016 | 3 |
| ... | ... | ... | ... |
让我们来分析一下这里发生了什么。我们将 order_count_by_week CTE 别名为 w1,然后再次别名为 w2。接下来,我们左连接了这两个 CTE。关键在于 DATEADD 函数,我们使用它将一周添加到每个 w2.week 值,以偏移连接的列。
LEFT JOIN order_count_by_week w2 ON w1.week = DATEADD(WEEK, 1, w2.week)
DATEADD 函数接受一个时间段(WEEK),要应用的时间段数(在本例中为 1,因为我们想知道与一周前相比的差异),以及要应用此添加操作的日期列(w2.week)。(请注意,某些数据库使用 INTERVAL 而不是 DATEADD,例如 w2.week + INTERVAL '1 week')。这会“对齐”行,但会错开一周(注意上面第一行中第二组周/订单计数的值缺失)。
现在我们有了一个表格,其中包含计算每行周与周变化所需的所有内容。现在,我们只需修改 select 语句以返回我们正在查找的列即可
- 下订单的周
- 该周的订单数
- 周与周的变化(即本周计数与上一周计数之间的差值)。
这是完整的查询
WITH order_count_by_week AS (
SELECT
DATE_TRUNC('week', orders.created_at) AS week,
COUNT(*) AS order_count
FROM
orders
GROUP BY
week
)
SELECT
w1.week,
w1.order_count AS count_of_orders,
w1.order_count - w2.order_count AS wow_change
FROM
order_count_by_week w1
LEFT JOIN order_count_by_week w2 ON w1.week = DATEADD(WEEK, 1, w2.week)
ORDER BY
w1.week
它返回
| WEEK | COUNT_OF_ORDERS | WOW_CHANGE |
|---------|-----------------|------------|
| 4/25/16 | 1 | |
| 5/2/16 | 3 | 2 |
| 5/9/16 | 3 | 0 |
| ... | ... | ... |
找出两个日期之间的持续时间
您经常想找出两个事件之间的时间量:注册和结账之间的秒数,或结账和送货之间的天数。
示例:客户创建账户到首次下单之间的天数是多少?
为了回答这个问题,我们将返回四列
- 客户 ID
- 客户创建账户的日期
- 客户首次下单的日期
- 这两个日期之间的差值
现在,要获取此信息,我们需要从 People 和 Orders 表中提取数据。但我们不想连接这两个表,因为我们只需要客户下的第一个订单。
让我们从找出每个客户何时下达了他们的第一个订单开始。
SELECT
user_id,
MIN(created_at) as first_order_date
FROM
orders
GROUP BY
user_id
这里我们按客户对订单进行分组(GROUP BY user_id),并使用 MIN 函数查找最早的订单日期。我们将这些结果存储为 first_orders,然后继续进行查询。
WITH first_orders AS (
SELECT
user_id,
MIN(created_at) as first_order_date
FROM
orders
GROUP BY
user_id
)
SELECT
people.id,
people.created_at AS account_creation,
first_orders.first_order_date,
DATEDIFF(
'day', people.created_at, first_orders.first_order_date
) AS days_before_first_order
FROM
PEOPLE
JOIN first_orders ON first_orders.user_id = people.id
ORDER BY
account_creation
这给了我们
| ID | ACCOUNT_CREATION | FIRST_ORDER_DATE | DAYS_BEFORE_FIRST_ORDER |
|------|------------------|------------------|-------------------------|
| 915 | 4/19/16 21:35 | 10/9/16 8:42 | 173 |
| 1712 | 4/21/16 23:46 | 8/15/16 4:01 | 116 |
| 2379 | 4/22/16 4:07 | 5/22/16 3:56 | 30 |
| ... | ... | ... | ... |
总结一下:我们提取了客户的 created_at 日期,并将查询连接到了我们的 CTE。我们使用 DATEDIFF 函数查找了从账户创建到他们首次下单的天数,然后将结果存储为 days_before_first_order。DATEDIFF 接受一个时间段(例如“day”、“week”、“month”),并返回两个时间戳之间的周期数。
(考虑到示例数据库是随机生成的,我们的响应与现实不太相符——人们在设置账户和购买之间等待 173 天的情况有多常见?)
延伸阅读
我们希望这些查询演练能为您自己提出的问题提供一些思路,但请记住,不同的数据库支持不同的 SQL 函数,因此在处理查询时,请养成查阅数据库文档的习惯。您还可以查看编写 SQL 查询的最佳实践。如果您对 JOIN 的工作原理有些模糊,可以查看Metabase 中的 JOIN。