

SQL 性能调优:提升查询速度、降低成本的技巧
提升查询性能的技巧:索引、物化视图等。
究竟什么是 SQL 性能调优?
SQL 性能调优的本质就是让您的数据库查询运行得更快、消耗的资源更少。将其比作对汽车进行调校,使其行驶更平稳、燃油效率更高——只不过在这里,您是要确保 SQL 查询不会拖慢一切。
优化查询有什么好处?
- 加速大型数据库中的数据检索
- 减轻服务器的负载,避免其被拖垮。
- 通过出色的性能留住用户。
- 通过节省计算能力(尤其是在云端)来省钱。
随着数据量的增长和查询变得越来越复杂,优化查询可以极大地影响您的应用程序或分析工具的性能。
如何使用 EXPLAIN 查看查询的执行方式
在 SQL 中,您指定想要获取的数据,但并不指定获取数据的方式。每个数据仓库都有一个查询规划器,其职责是确定如何执行查询。该查询规划器根据执行时间、资源使用情况和/或数据库预设来确定运行查询的最佳方式。例如,查询规划器将决定是读取表中的所有行,还是根据特定条件将搜索范围缩小到特定行集。
要查看数据库将如何执行您的查询,可以在查询前面加上 EXPLAIN。查询规划器将列出它将执行的操作、执行顺序、使用的索引等。还有一个 EXPLAIN ANALYZE,它会提供实际的查询执行统计信息。但是,要获取这些统计信息,数据库将实际执行查询,这可能非常耗时,甚至对于修改数据的查询来说是不可取的。
要查看 EXPLAIN 的实际效果,让我们先在 PostgreSQL 数据库中创建一些模拟数据(其他数据库也可能适用,但可能需要调整代码)。运行以下语句(您需要数据仓库的写入权限)。
DROP TABLE IF EXISTS data_table;
CREATE TABLE data_table (
id SERIAL PRIMARY KEY,
date_field DATE NOT NULL,
category TEXT NOT NULL CHECK (category IN ('A', 'B', 'C')),
numeric_value NUMERIC NOT NULL
);
INSERT INTO data_table (date_field, category, numeric_value)
SELECT
CURRENT_DATE - (random() * 365)::INT, -- Random date within the last year
CASE FLOOR(random() * 3)
WHEN 0 THEN 'A'
WHEN 1 THEN 'B'
ELSE 'C'
END, -- Random category
(random() * 1000)::NUMERIC -- Random numeric value between 0 and 1000
FROM generate_series(1, 50000000);
此查询可能需要一些时间。要检查它是否成功,请运行
SELECT
*
FROM
data_table
LIMIT
10;
您将看到类似以下内容:
| id | date_field | category | numeric_value |
| --- | ----------------- | -------- | ------------- |
| 1 | August 2, 2024 | A | 874.17 |
| 2 | October 31, 2024 | A | 762.03 |
| 3 | August 23, 2024 | A | 718.73 |
| 4 | February 6, 2025 | C | 334.45 |
| 5 | August 28, 2024 | A | 59.4 |
| 6 | August 8, 2024 | A | 972.74 |
| 7 | October 18, 2024 | B | 296.99 |
| 8 | November 27, 2024 | B | 858.26 |
| 9 | September 5, 2024 | C | 137.84 |
| 10 | February 24, 2025 | C | 701.68 |
让我们对 category 进行一次简单的 numeric_value 求和,看看需要多长时间。查询如下:
SELECT
category AS "Category",
SUM(numeric_value) AS "Sum"
FROM
data_table
GROUP BY
category
ORDER BY
category ASC
您将看到类似以下内容:
| Category | Sum |
| -------- | ---------------- |
| A | 8,336,275,140.07 |
| B | 8,330,139,598.5 |
| C | 8,334,188,258.65 |
在我们拥有 2 个 CPU 核心和 2GB RAM 的 PostgreSQL 17 上运行此查询大约需要 8 秒——相当长的时间。
现在,让我们对查询运行 EXPLAIN。 EXPLAIN 将输出查询的计划,以及其成本和其他关于查询的数据。只需在查询前面加上 EXPLAIN 即可
EXPLAIN
SELECT
category AS "Category",
SUM(numeric_value) AS "Sum"
FROM
data_table
GROUP BY
category
ORDER BY
category ASC;
您将看到以下输出(可能因您当前的部署而异):
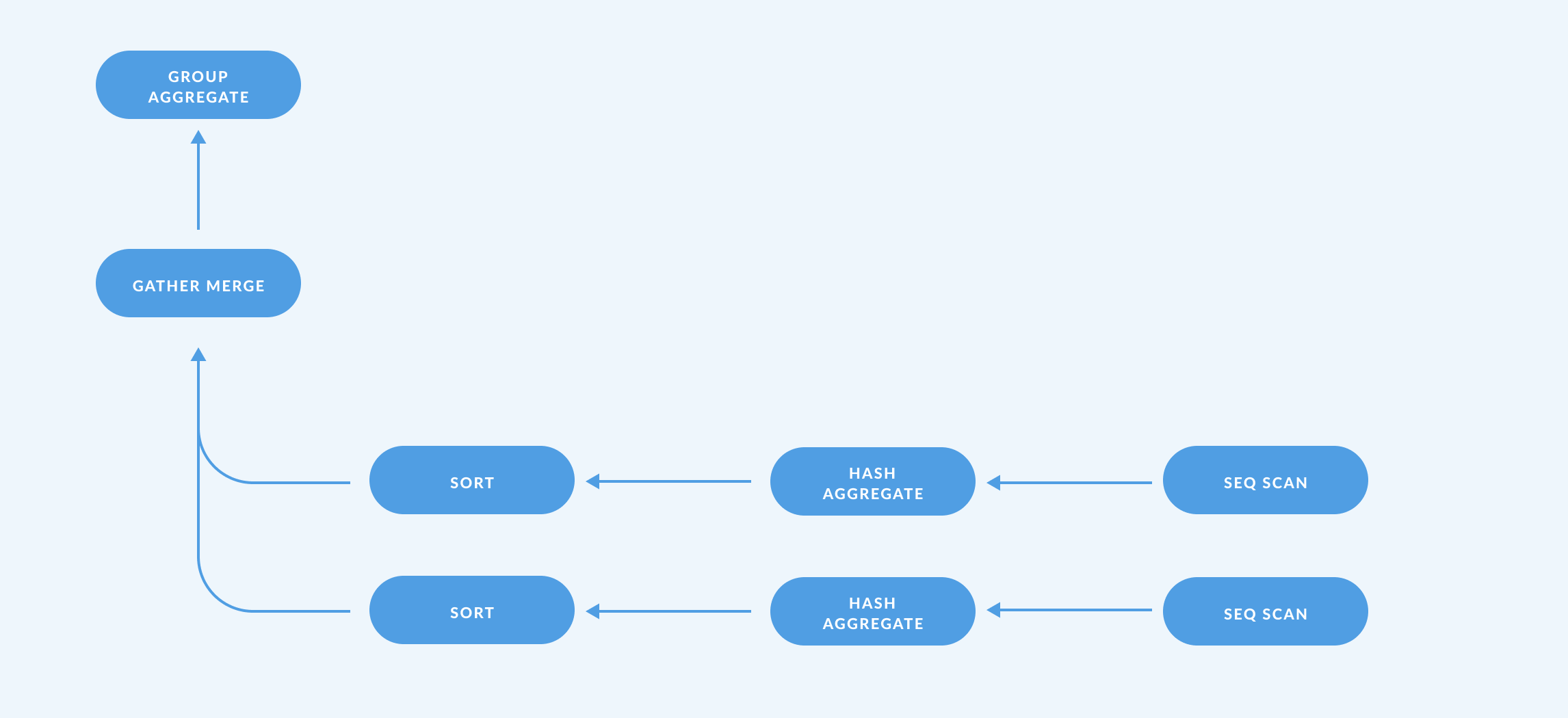
QUERY PLAN
Finalize GroupAggregate (cost=631972.08..631972.87 rows=3 width=34)
Group Key: category
-> Gather Merge (cost=631972.08..631972.78 rows=6 width=34)
Workers Planned: 2
-> Sort (cost=630972.06..630972.07 rows=3 width=34)
Sort Key: category
-> Partial HashAggregate (cost=630972.00..630972.04 rows=3 width=34)
Group Key: category
-> Parallel Seq Scan on data_table (cost=0.00..526805.33 rows=20833333 width=13)
JIT:
Functions: 7
Options: Inlining true, Optimization true, Expressions true, Deforming true
EXPLAIN 的输出应从下往上阅读。此查询计划表示:
-
数据库将首先在可用核心上并行地顺序扫描表中的所有记录(
Seq Scan)(Workers Planned: 2)。 -
然后,数据库将对数据进行聚合(
HashAggregate),并在每个工作节点上分别进行(Partial)。数据库必须进行聚合,因为我们包含了
GROUP BY子句和聚合函数SUM。聚合可以并行进行,因为求和操作是可以并行化的:对两个分区进行总和求和与对所有数据求和是相同的。 -
然后,数据库将分别在每个工作节点上对聚合结果进行排序(
Sort)。令人惊讶的是,
Sort存在,不是因为我们包含了ORDER BY子句——如果您删除ORDER BY子句,Sort步骤仍然存在。数据库对聚合结果进行排序是因为它需要合并来自两个工作节点的 결과,并且在结果已排序时合并更有效。如果
ORDER BY category被替换为ORDER BY "Sum",查询计划中将有两个排序——在GroupAggregate之后还有一个额外的排序。 -
接下来,数据库将合并来自两个工作节点的 결과(
Gather Merge)。此时,数据库尚未计算出每个类别的总和。我们知道它还没有计算出来,因为在聚合之后
rows的值为3:每个工作节点都有三行,每个类别(A、B 和 C)一行,但在Gather Merge之后我们有 6 行,因此数据库尚未合并每个工作节点的总和。 -
最后,数据库将对来自两个工作节点的 결과进行分组和聚合(
GroupAggregate)。
从性能角度来看,此输出告诉我们:
- 查询处理器使用了 2 个核心(
Workers Planned: 2)。 - 成本最高的 operasi 是
Parallel Seq Scan(0.00..526805.33)。 - 其他 operasi 对总查询时间的影响可以忽略不计(例如,
HashAggregate的时间为630972.00..630972.04——两个数字之间的差异,即成本,与Parallel Seq Scan的成本相比非常小)。
那么,我们如何才能让这个查询在用户每天早晨查看仪表板时不再耗尽数据库资源呢?数据库必须读取表中的每一行才能对其进行求和,因此我们无法减少扫描的总行数。我们所能做的最好的就是加快扫描速度。我们的选项包括:
- 增加 CPU 核心数量,这样每个核心需要处理的行数就减少了。
- 切换到具有优化架构的数据库,以加快对单个列的顺序扫描(例如,列式数据库)。
如果基础设施的更改不可行,您可以改为预先计算聚合结果——如果用户频繁运行查询,这将非常有用——并使用 缓存结果 或 物化视图。
为昂贵的 JOIN、CTE 和视图创建物化视图
物化视图 是在数据仓库中保存的预计算查询。物化视图通过存储计算结果供用户查询,从而减轻了数据库的负担,而不是每次用户查询数据库时都重新计算行。您可以定期刷新物化视图以使其结果与新数据保持同步。
让我们用之前的查询创建一个物化视图
CREATE MATERIALIZED VIEW preprocessed_sum_of_numeric_value_by_category AS
SELECT
category AS "Category",
SUM(numeric_value) AS "Sum"
FROM
data_table
GROUP BY
category
ORDER BY
category ASC
这将保存查询的结果
-- preprocessed_sum_of_numeric_value_by_category
| Category | Sum |
| -------- | ---------------- |
| A | 8,336,275,140.07 |
| B | 8,330,139,598.5 |
| C | 8,334,188,258.65 |
现在,为了获得每个类别的总和,我们只需要从此物化视图中选择即可
SELECT
*
FROM
preprocessed_sum_of_numeric_value_by_category;
查询物化视图可以将时间从几秒缩短到几毫秒。
取决于您的数据库,物化视图在底层数据更改时可能会更新,也可能不会。例如,如果您使用的是 PostgreSQL,您将需要更新您的物化视图。要重新计算结果,您需要一个脚本来在特定时间间隔内运行 REFRESH MATERIALIZED VIEW preprocessed_sum_of_numeric_value_by_category。刷新结果的频率取决于底层数据更改的频率以及用户查看结果的频率。
以下是一些您应该考虑物化视图的情况:
连接
表 JOIN 是关系数据库世界中最美妙的事物之一(至少我们是这么认为的)。 JOIN 允许您将业务组织成模块化部分,只需一个简单的关键字即可将它们组合在一起。但 JOIN 也可能非常危险:与巨型表进行 JOIN 可能会严重拖垮您的数据仓库。如果您每次查询都需要 JOIN 两个或三个以上的表,请考虑将 JOIN 的基本查询物化为一个物化视图。
CTE
CTE 非常适合模块化您的代码。但是,您的数据仓库每次运行这些查询时都必须计算这些 CTE。如果您发现自己每天都在运行相同的、包含大量 CTE 的查询,那么是时候以这样一种方式来建模您的数据了,即您的查询只是一个简单的 SELECT * FROM table,其中 table 是一个物化视图或一个您用这些 CTE 的结果创建的表。
视图(非物化视图)
您不必每次进行查询时都编写数百行 SQL,只需从您保存的视图中选择行即可:您将获得相同的结果。视图只是抽象;它们不会带来任何性能优势。当您想降低查询的复杂性时,请使用视图。如果您经常使用结果,请考虑物化视图。
通过索引经常查询的列来加速查询
您可能在某个时候听说过索引。您的查询很慢,一位数据库专家告诉您创建一个索引,然后:查询就变快了。索引就像一个查找表,可以帮助您的数据库快速找到特定行,而无需扫描整个表。就像书的索引帮助您找到主题而无需阅读每一页一样,数据库索引直接指向数据存储的位置。当您需要查找部分数据而不是全部数据时,它们效果很好。
当您将索引添加到一列或多列时,数据库将创建这些列的副本,该副本经过优化,可以查找特定值,并且还包含一个指针,用于从其他(非索引)列中获取值。
例如,假设您有一个包含客户数据的表,其中包含客户 ID、姓名、注册日期等。如果您想查找具有特定姓名的客户,数据库将不得不扫描每条记录,并将姓名与您请求的姓名进行比较,直到找到匹配项。但是,如果您在姓名列上创建了索引,数据库将有其他方法来执行此操作。索引的实际实现可能有所不同,但大致来说,您可以将其视为一个已排序的列表,其中包含所有姓名,并附带一个指向数据库中该姓名确切记录的指针。因为索引中的姓名列表已排序,所以数据库需要更少的时间来定位您请求的姓名。一旦找到姓名,它将使用索引中存储的指针来检索该客户的其他数据。
您的数据库将始终为主键创建索引(这就是为什么按 ID 查找记录通常比按姓名和姓氏查找快)。
让我们回到之前的例子:对表中的所有类别的 SUM(numeric_value)。索引会使这个问题更快吗?绝对不会,因为这个问题仍然需要遍历整个表来计算结果。
现在,让我们想象一下有人想执行一个只查找表中一部分数据的查询:按类别汇总数值,但仅限过去 60 天。让我们试试
SELECT
category AS "Category",
SUM(numeric_value) AS "Sum"
FROM
data_table
WHERE
date_field <= CURRENT_DATE + INTERVAL '1' DAY
AND date_field >= CURRENT_DATE - INTERVAL '60' DAY
GROUP BY
category
ORDER BY
category ASC
这花费了很长时间!让我们运行 EXPLAIN 看看发生了什么。
QUERY PLAN
Finalize GroupAggregate (cost=857409.42..857410.21 rows=3 width=34)
Group Key: category
-> Gather Merge (cost=857409.42..857410.12 rows=6 width=34)
Workers Planned: 2
-> Sort (cost=856409.40..856409.41 rows=3 width=34)
Sort Key: category
-> Partial HashAggregate (cost=856409.34..856409.38 rows=3 width=34)
Group Key: category
-> Parallel Seq Scan on data_table (cost=0.00..839305.33 rows=3420801 width=13)
Filter: ((date_field <= (CURRENT_DATE + '1 day'::interval day)) AND (date_field >= (CURRENT_DATE - '60 days'::interval day)))
JIT:
Functions: 9
Options: Inlining true, Optimization true, Expressions true, Deforming true
再次,我们看到昂贵的顺序扫描操作。 date_field 上的索引会有帮助吗?
创建索引
让我们在 date_field 列上创建一个索引
CREATE INDEX idx_data_table_date
ON data_table (date_field);
数据库需要一些时间来创建索引,并且在索引完成之前,它将阻止对该表的任何写入操作。
您可以使用查询检查索引
SELECT
tablename,
indexname,
indexdef
FROM
pg_indexes
WHERE tablename = 'data_table'
编写利用索引的查询
一旦索引建立,让我们再次运行查询,看看它是否使用了索引并减少了返回结果所需的时间。
如果您再次运行 EXPLAIN,您会发现索引根本没有被使用,您仍然会看到并行顺序扫描(并且查询仍然很慢)。
让我们看看是否能让数据库使用特定的、非相对日期。
EXPLAIN
SELECT
category AS "Category",
SUM(numeric_value) AS "Sum"
FROM
data_table
WHERE
date_field BETWEEN DATE '2025-01-01' AND DATE '2025-03-01'
GROUP BY
category
ORDER BY
category ASC;
这给了我们
QUERY PLAN
Finalize GroupAggregate (cost=649104.46..649105.24 rows=3 width=34)
Group Key: category
-> Gather Merge (cost=649104.46..649105.16 rows=6 width=34)
Workers Planned: 2
-> Sort (cost=648104.44..648104.44 rows=3 width=34)
Sort Key: category
-> Partial HashAggregate (cost=648104.38..648104.41 rows=3 width=34)
Group Key: category
-> Parallel Seq Scan on data_table (cost=0.00..630972.00 rows=3426475 width=13)
Filter: ((date_field >= '2025-01-01'::date) AND (date_field <= '2025-03-01'::date))
JIT:
Functions: 9
Options: Inlining true, Optimization true, Expressions true, Deforming true
使用特定日期将成本从 cost=0.00..839305.33 降低到 cost=0.00..630972.00。
但是,引擎仍然在执行全表扫描吗?是的,它在执行(Parallel Seq Scan on data_table)。为了让数据库使用索引,我们需要缩小时间范围。让我们将 BETWEEN 条件更改为将时间范围缩小到两周,例如 2025-03-01 到 2025-03-15。再次运行 EXPLAIN。您会看到类似以下内容:
QUERY PLAN
Finalize GroupAggregate (cost=633296.94..633297.72 rows=3 width=34)
Group Key: category
-> Gather Merge (cost=633296.94..633297.64 rows=6 width=34)
Workers Planned: 2
-> Sort (cost=632296.92..632296.92 rows=3 width=34)
Sort Key: category
-> Partial HashAggregate (cost=632296.86..632296.89 rows=3 width=34)
Group Key: category
-> Parallel Bitmap Heap Scan on data_table (cost=27900.15..628034.34 rows=852503 width=13)
Recheck Cond: ((date_field >= '2025-03-01'::date) AND (date_field <= '2025-03-15'::date))
-> Bitmap Index Scan on idx_data_table_date (cost=0.00..27388.65 rows=2046008 width=0)
Index Cond: ((date_field >= '2025-03-01'::date) AND (date_field <= '2025-03-15'::date))
JIT:
Functions: 9
Options: Inlining true, Optimization true, Expressions true, Deforming true
看到 Index Cond 了吗?现在我们正在利用我们创建的索引。之前是顺序扫描,现在是索引扫描。
看起来很神奇,对吧?嗯……没那么神奇。因为正如您已经看到的,如果您查询的时间跨度足够长,仍然会触发全表扫描。这是有原因的。
让我们设想以下场景:您有一本千页的书。您是一位热情的读者,每天阅读一百页。现在,假设您想在书中查找特定行。您无法使用索引来查找这些行;您需要扫描整本书。现在,假设您需要查找涵盖某个主题的章节,而不是查找特定行:这种情况索引就派上用场了。
等等,但这些是计算机,对吧?像,速度极快的读者?我不能为每一列创建一个索引来覆盖所有可能的情况吗?嗯,您绝对可以,但所有这些索引都会阻碍表的写入能力:每次有新行插入时,引擎都必须更新所有索引。此外,数据库需要越来越多的空间来保存这些索引。
所以索引可以(非常有帮助),但它们也有局限性。以下是加快查询速度的其他一些方法。
其他提高 SQL 查询性能的技巧
只请求您需要的数据
更多的行意味着更慢的查询(大多数情况下)。与教科书类似,书页越多,阅读时间就越长。数据库也是如此。因此,只请求您需要的数据。减少行数的一个常见方法是过滤较短的时间范围。
缓存结果
缓存只是保存查询结果,以便将来可以检索结果。您可以决定结果在需要通过另一个数据库调用进行刷新之前保持有效的多长时间。查看您的 BI 工具中的 缓存选项。
根据您当前的需求对数据进行建模,而不是永远
在这里,数据建模仅指您如何将数据组织到表中,以及这些表之间如何相互关联。您的分析需求将与您的操作需求不同(您的应用程序的数据模型可能不是分析查询的最佳模型)。良好建模的数据可以真正提高性能,但没有完美的数据模型。好的数据模型是能够解决您今天(以及未来几个月)遇到的问题的模型。能够生存下来的公司将随着时间的推移而成长和发展,因此您过去所做的设计选择可能不再适合您。
检查数据库的工作负载管理功能
数据库的设计是为了同时为多个客户端运行查询。但有一个缺点:对于数据库引擎来说,一个大型查询和一个快速查询具有相同的优先级,因此您可能会遇到这种情况:大型查询会消耗服务器的所有资源,而快速查询则耐心地等待资源释放。
某些数据库引擎提供工作负载管理功能,允许您将查询分配到不同的队列,从而可以减轻那些大型查询对服务器的冲击。
避免在应用程序的生产数据库上运行查询
除非您是一家只有少数人使用您应用程序的初创公司,否则我们不建议在与您的应用程序在生产环境中使用相同的数据库上运行查询。一个昂贵的查询可能会给您的日常运营带来混乱。我们建议您至少创建一个独立的、只读的数据仓库(通常称为读取副本,因为它与您的生产数据库是副本),并将您的分析工具连接到它。
对于数据湖,请使用分区键
如果您正在使用数据湖,这里概述的基本原则也适用。此外,如果您的数据湖具有分区功能,您应该使用分区键来帮助您避免大规模读取。为了充分利用并行化,您需要在使用所有查询时使用分区键。
考虑列式数据仓库
像 PostgreSQL 这样的传统关系数据仓库是全能型的,它们可以带您走上分析之路。但如果查询时间变得无法忍受——并且您已经尝试了本文中的所有技术——请考虑将您的分析工作负载迁移到列式引擎。列式数据仓库专为分析工作负载而设计,因此它们可以为您带来巨大的性能提升(当然,这需要付出代价)。
有关列式存储的性能技巧,您需要参考特定列式引擎的文档,因为每个引擎都有其独特的怪癖和定价。
您无法让所有查询都快如闪电
您可以做的是在以下几点之间取得平衡:
- 基础设施成本:即使您投入更多的核心和内存来解决问题,您的查询速度也会停滞不前。
- 您创建的索引:如果您创建了过多的索引,写入速度会变慢。
- 数据的新鲜度:如果您不需要实时更新数据,可以保存并重用结果。