

什么是模式?
Schema(模式)是指定义数据集组织方式的设计或结构:列如何分组到表中,表之间如何关联,以及定义这些列的规则和数据类型。
Schema 是一个被过度使用的术语;它是一个抽象的词,积累了很多不同的定义,因此可能令人困惑。根据上下文,Schema 可以表示:
最后,Schema 有时指的是你正在使用的特定数据库平台,例如在 Oracle 中,Schema 指的是同一个用户创建的数据库中的所有对象。
Schema 作为整体结构:设计与实现
一旦你从高层角度确定了数据的组织方式(即你的概念性 数据模型),下一步就是创建一个反映该数据模型的 Schema,将其从抽象转化为你的组织可以使用并填充信息的数据库。
广义上,这个过程包含两个主要步骤:
- 设计:规划你的数据库结构,在此过程中创建实体关系图(ERD)。
- 实现:使用 ERD 生成 SQL 命令,在数据库中运行这些命令即可创建你想要的 Schema。
你的 Schema 设计过程看起来如何,取决于你是处理 事务性数据库还是分析性数据库,以及你是从零开始还是已经开始收集数据。无论你何时设计 Schema,你都需要深入思考你的组织需求以及你预期会从你的数据中提出哪些问题。
写时模式 (Schema-on-write) vs. 读时模式 (Schema-on-read)
大多数传统的 关系型数据库 使用 **写时模式 (schema-on-write)** 系统,数据在写入数据库之前会被验证并格式化为 Schema。由于写入的数据必须符合你建立的任何特定数据完整性规则(例如要求字段中的所有值都是唯一的,不允许字段中出现空值,或以某种方式格式化日期),向数据库添加新数据可能会很慢。然而,读取数据的时间很快,因为数据已经过验证。
在 **读时模式 (schema-on-read)** 系统中,数据(如 数据湖 中的数据)仅在读取或从数据库中提取时才会被验证。读时模式系统通常更灵活,因为你可以存储非结构化数据,而不必担心它是否符合严格的数据模型。在这种情况下,写入数据更快(因为数据在加载时不需要验证),但查询需要更长时间来执行。
你选择写时模式还是读时模式策略,将取决于你组织的需要和具体用例。如果对你的组织来说,拥有严谨结构化且一致的数据集很重要,那么写时模式系统可能是你最好的选择。相反,如果你需要经常提取各种各样的数据,但又不总是确切知道这些数据是什么样的,你可能想使用写时模式系统。
逻辑 Schema 与物理 Schema
无论你是在使用写时模式还是读时模式系统,你都需要考虑数据库结构及其实现——即你的逻辑 Schema 和物理 Schema。逻辑 Schema 定义了数据的结构,而该结构的实际实现(例如数据库文件的存储方式和位置)则属于物理 Schema。
逻辑 Schema
**逻辑 Schema** 通过绘制表及其字段之间的关系来创建。在创建逻辑 Schema 时,你将建立表、关系、字段和视图,回答诸如以下问题:
- 我们正在收集或想要收集哪些数据?
- 你的数据库(或其中单个 Schema)需要哪些表?
- 这些表之间如何关联?
- 每个表需要哪些字段?
- 每个字段的数据类型是什么?
- 哪些字段是必需的?
Schema 作为图表:映射实体与关系
在回答这些和其他问题时,你可能会绘制一个 实体关系图 (ERD),该图定义了每个表、其字段、它们的完整性约束以及表之间的关系,包括建立这些连接的 主键 和 外键,以及表之间的关系是 一对一、一对多还是多对一。可视化你的表以及它们之间的关系,还可以揭示任何主要的遗漏或冲突。是的,有时你也会看到这些图表本身被称为 Schema。
下图展示了一个包含两个表 PRODUCTS 和 MANUFACTURER 的 Schema 的实体关系图。 “(PK)” 和 “(FK)” 标记告诉我们哪些字段是主键和外键,连接这些表的线表示一对多关系,即一个制造商可以关联多个产品。
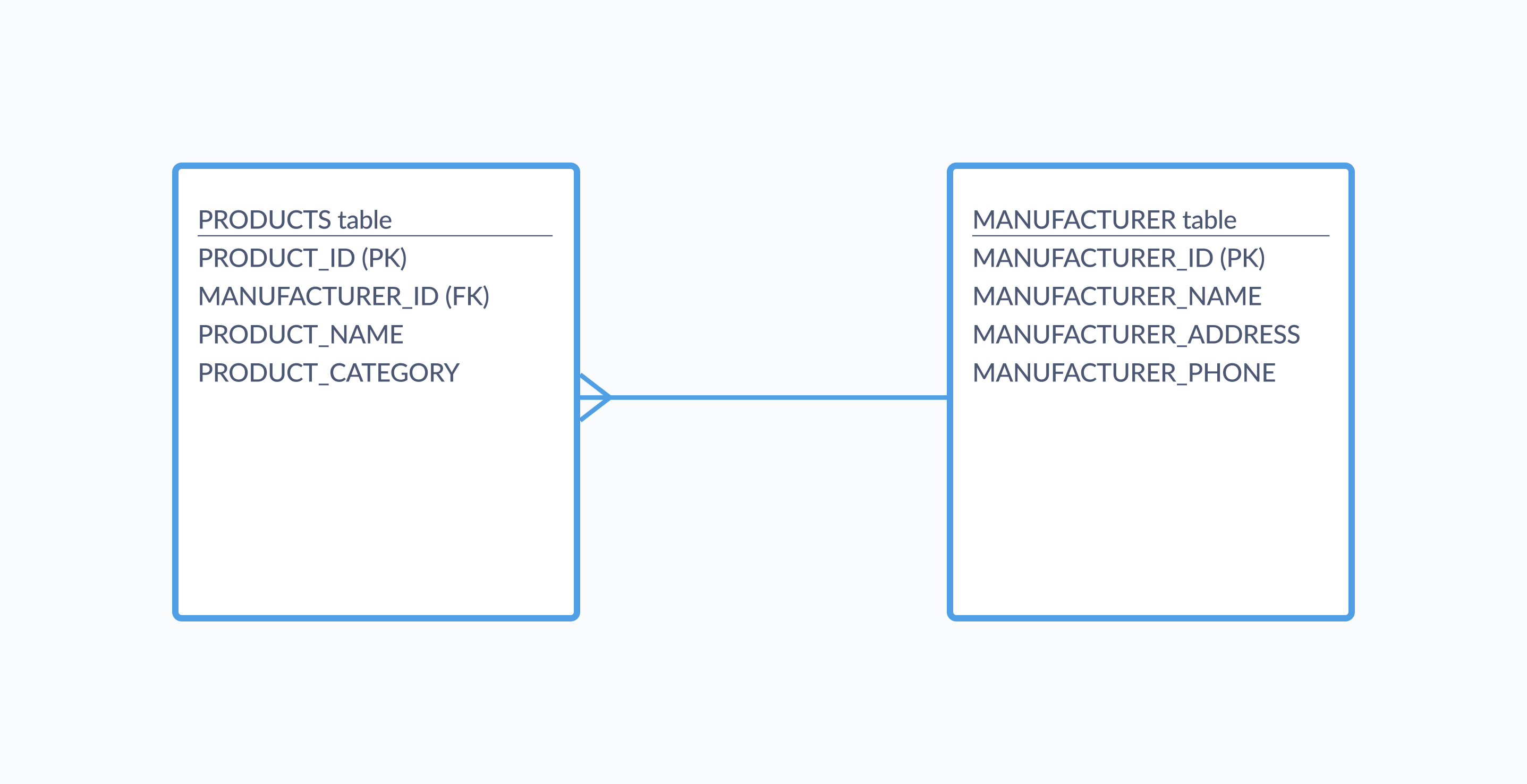
你可以在纸上或使用设计软件来绘制你的 Schema,该软件可以直接将你的图表转换为实现数据库所需的 SQL 命令。此时你的 Schema 是平台无关的;绘制这些规则和关系不会将你绑定到任何单一的数据库软件。
物理 Schema
一旦你确定了数据库的逻辑配置,你将创建一个 **物理 Schema** 来将其实现到特定的 RDBMS 中,定义数据库文件将存放在何处以及它们在磁盘上的存储分配。
Schema 作为许多表中的一个集合
虽然一个表的集合可能足够,如果你的数据库只有很少的用户,并且包含每个人都需要访问的数据,但你可能会发现依赖数据库中的单个 Schema 无法满足你组织的需求。如果你处理大量表的数据(想想几十个、几百个或几千个),将这些表分组到单独的 Schema 中,从组织的角度会很有帮助,可以让你将相似的信息存储在一起,同时保留在必要时跨 Schema 查询的能力。
在数据库中保留多个 Schema 在安全方面也很有帮助,例如将包含敏感信息的表分离到一个只有需要的人才能访问的 Schema 中,通常与 视图 结合使用。
事务性数据库与分析性数据库的 Schema 设计
在考虑 **事务性数据库**(也称为操作型数据库)的 Schema 时,你的数据需要一定程度的规范化并遵循数据完整性标准,因为对这些小事务和 OLTP 的效率和性能至关重要。
设计 **分析性数据库** 的 Schema 会有所不同。首先,你可能已经收集了原始数据,可能来自多个来源,现在需要施加一些结构来分析它。在这种情况下,冗余是可以接受的,因为分析性数据库更注重可探索性,而不太注重性能。这里你的 Schema 也可以更宽松地定义,因为不需要固定的模式(如 规范化)。分析性数据库的 Schema 设计更多是关于理解你各种来源的数据在哪里,以及知道你需要连接哪些表来回答你的问题。
星型 Schema
分析性数据库中常见的一种结构是 **星型 Schema**,它将数据分为事实表(即定量数据),这些事实表与描述这些事实的多个 维度 表相关联。在星型 Schema 的简单实现中,几个维度表都围绕并关联着一个单一的事实表,在图表中看起来像一颗星,事实表位于中心,如下图所示:
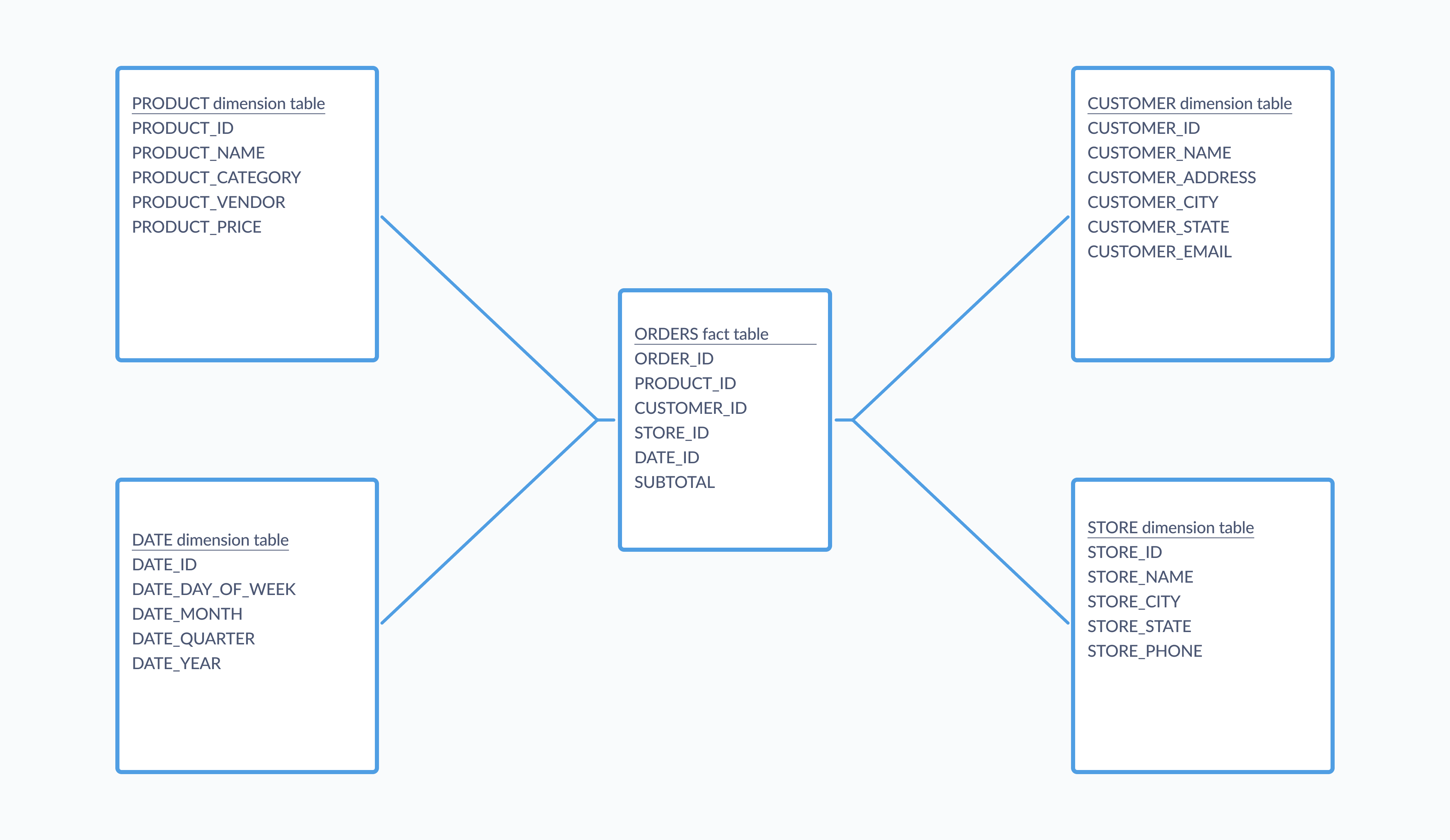
星型 Schema 中的表通常是反规范化的,这可以提高分析性查询的性能。
创建数据库 Schema
大多数数据库平台(如 Redshift 和 PostgreSQL)使用“Schema”来表示数据集的配置以及该数据集内非嵌套的表和其他命名对象的组,尽管 Oracle 将 Schema 定义为由单个数据库用户创建并属于该用户的所有对象。
要在你的 RDBMS 中创建 Schema,请使用查询 CREATE SCHEMA,例如在本例中,我们创建了一个包含两个表,并通过 customer_id 字段链接的 Schema:
CREATE SCHEMA new_schema;
CREATE TABLE new_schema.orders (
order_id
product_id
customer_id
subtotal
order_date
)
CREATE TABLE new_schema.customers (
customer_id
customer_name
customer_address
customer_email
);
这是一个非常简单的 Schema;我们没有为表中的字段指定数据类型或任何其他约束。如果我们想在 customers 表中要求 customer_id 字段,并指示其数据类型为整数,我们将这样格式化该字段:
customer_id INT NOT NULL
请注意,在 MySQL 中,CREATE SCHEMA 与 CREATE DATABASE 同义。
