


我将颤抖的手指移到按钮上时,一滴汗珠顺着我的额头滑落。
我不是即将发射核弹的军队将军,也不是即将发射火箭进入太空的 SpaceX 指挥官。
我只是一名正在**将数据模型更改合并到生产环境**的业务智能分析师。即便如此,我也能想象我们的压力水平是相似的。
当然,我是在夸张。
但是,任何做数据分析师时间长的人都知道,对现有模型进行更改会带来多大的压力。特别是,如果你曾经发布过导致不准确、数据错误或结论错误的更改。
在进行数据模型更改时,避免丢失对数据的信任
作为数据分析师,没有什么比利益相关者在生产环境中发现数据不准确更糟糕的了。
看到他们对你的数据失去信任,我宁愿送给我的头号敌人。这就是为什么你可能总是会仔细检查数据,并希望能运行自动化测试,以确保没有重大的错误潜入。
确保你的数据模型更改是正确的
但通常你仍然会感到挥之不去的焦虑,担心你忽略了什么。
幸运的是,简单的解决方案是在数据模型更改中比较新旧数据
这是我们为确保 Infused Insight 一贯的高质量和准确数据而采用的众多策略之一。Infused Insight 是一家帮助使用 Infusionsoft 的企业通过数据洞察获得更多潜在客户和销售额的公司。而这个解决方案一直非常有帮助。
我们在首次应用此策略时就注意到了数据中一项意外的更改。此后,它一次又一次地被证明非常有用。
理论上,这个解决方案很简单
在对模型查询进行更改后,分析师应该写下关于他们期望结果数据如何变化的假设,例如:
“之前为 NULL 的广告号召性用语 URL,现在应该包含一个有效的 URL。”
接下来,他们应该对旧查询和新查询的结果进行比较,比较所有列值并检测所有新增和删除的行。
然后,他们检查是否只应用了预期的更改。这似乎是一项非常普遍的任务,应该有很多工具(最好是开源的)可以实现它。
选择正确的工具来支持你的数据模型更改
现实情况却并非如此。
有一些工具可以完全实现我想要的功能,并提供用户友好的界面,但它们是闭源的、相当昂贵,最重要的是,只能在 Windows 上使用。
我们的最终解决方案是创建一个 Jupyter Notebook,使用 python、pandas 和 datacompy 来比较表的旧版本和新版本。你可以与 pandas 支持的任何数据库一起使用它,甚至可以与 CSV 文件一起使用。
结果是一个 .txt 文件,其中包含更改摘要,以及一个 SQLite 数据库,你可以详细查询所有更改的列和行。
SQLite 数据看起来是这样的
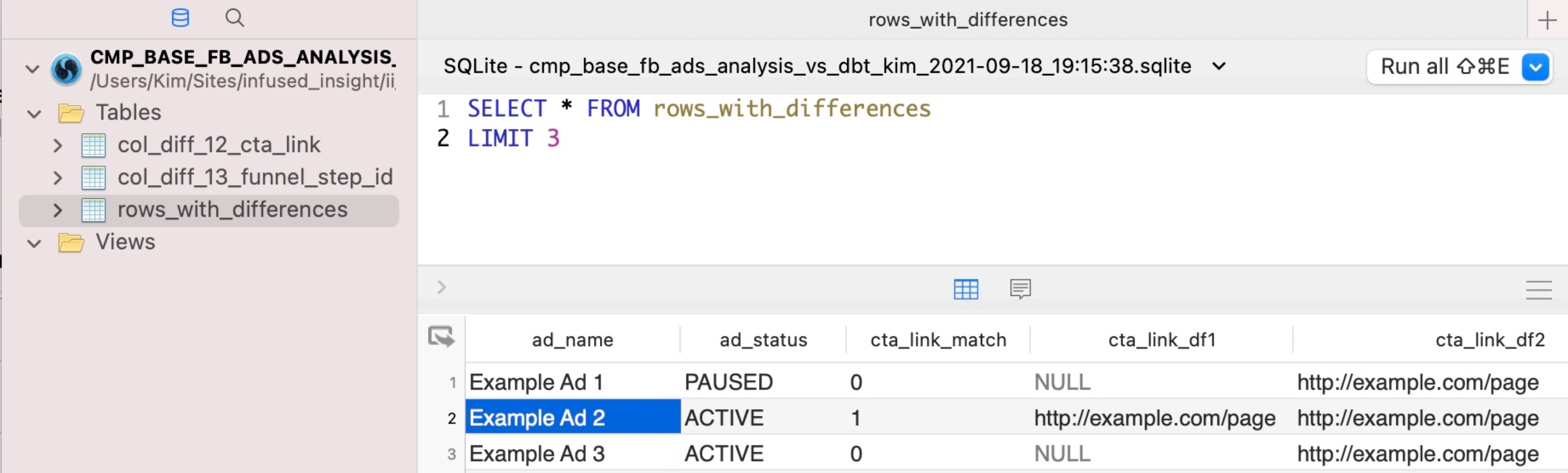
在截图中,你可以看到对 rows_with_differences 表的查询。此表包含在两个版本之间找到差异的所有行。
对于发生更改的列(例如 cta_link 列),你将获得三列(_match、_df1 和 _df2),让你看到更改是什么,并轻松过滤数据。但是,在所有行中都没有更改的列(例如 ad_name 和 ad_status)则没有这些额外的列。
这样,你就可以一目了然地看到发生了什么变化,同时也能将更改的数据与该行其余数据联系起来。
我已将代码发布到 GitHub 上的 Jupyter Notebook,你可以在下方继续学习。
如何对你的数据模型更改执行相同的比较
首先,你需要下载代码并安装 python 依赖项。
git clone git@github.com:Infused-Insight/sql_data_compare.git
cd sql_data_compare
pip install -r requirements.txt
接下来,你将需要打开 data_compare.ipynb 文件。你可以使用 jupyter server 打开它……
jupyter notebook data_compare.ipynb
或者你可以下载 VSCode,并通过它运行。这是我偏好的方法。打开 jupyter notebook 后,你需要调整设置。
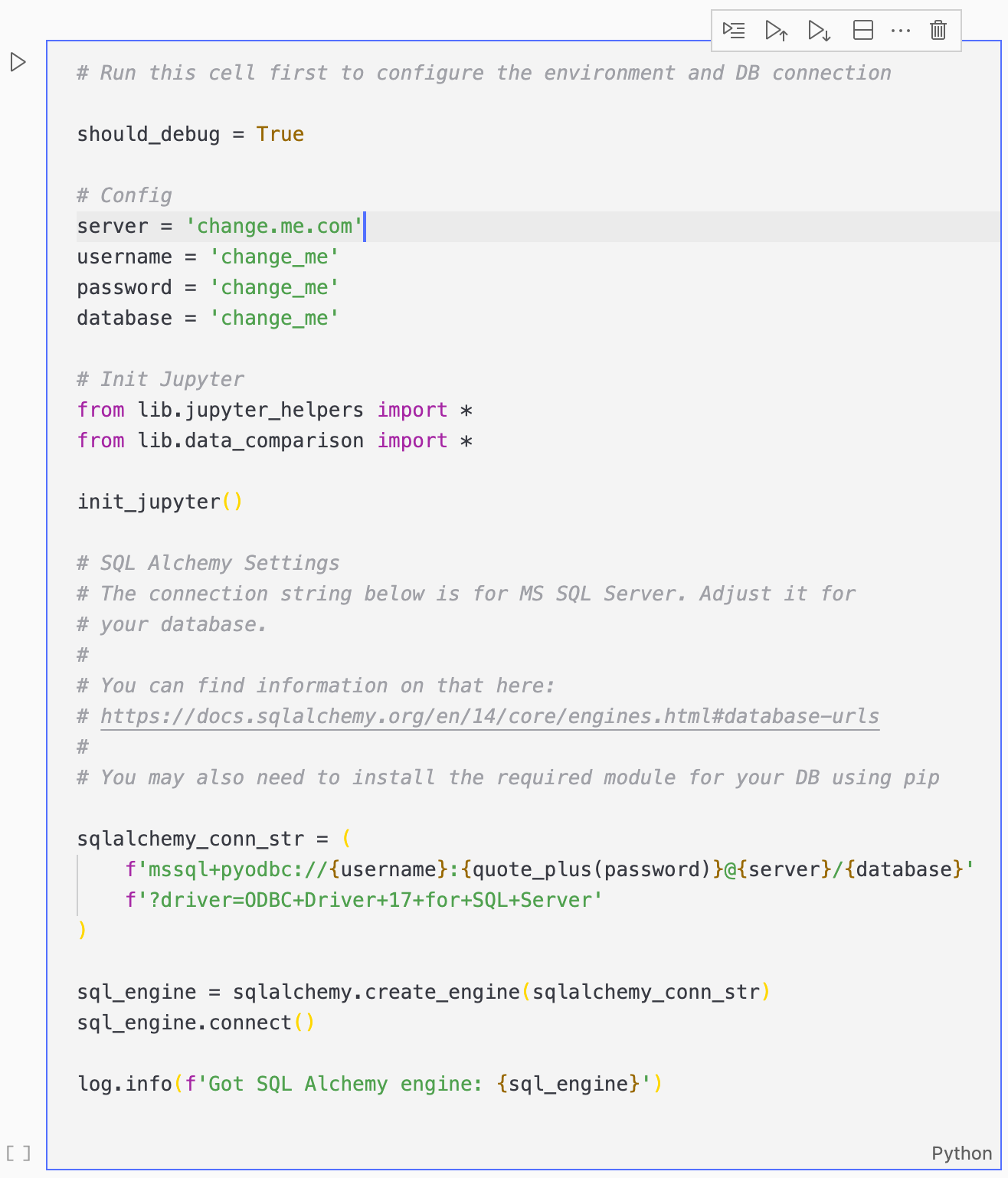
该解决方案使用 python 的 SQLAlchemy 模块从 SQL 数据库加载数据,然后使用 pandas 和 datacompy 进行比较,最后将结果写入 SQLite 数据库。
因此,第一步是配置 SQL 数据库设置和 SQLAlchemy 连接字符串。
在上面的示例中,它配置为连接到 MS SQL 服务器,但你可以将其更改为 SQLAlchemy 支持的任何数据库。
有关更多详细信息,你可以参考 他们的数据库 URL 文档。
之后,你可以在第二个 jupyter cell 中开始比较。

只需调整设置并运行它。
你将在 ./comparison/ 目录中找到结果报告和包含更改的 SQLite 数据库。
结论:数据模型更改
我希望这个简单的解决方案能帮助你避免错误,并让你有信心在不担心破坏任何东西的情况下改进现有模型。