


作为一名产品经理,我很高兴能在日常工作中依赖数据。我知道我可以顺畅地工作,而不会因为缺乏所需的洞察而被打断。我的目标是通过提供有用的仪表盘和数据可视化来提高团队的数据素养。这有助于我们保持正轨,并提前发现趋势和绩效变化。
但并非一直如此。
我曾经使用过大型 Google 表格,其中包含超过 10,000 行数据,运行非常缓慢。我构建了大量的透视表来分析数据,而等待结果却花费了我很长时间。
我通过学习 SQL 摆脱了这种困境。我与经理沟通,并获准测试 Google BigQuery,还得到了一位数据工程师的帮助。这为我们自助式产品分析奠定了基础。
我如何使用 Metabase 为我的产品团队设置自助式分析
我目前的职责之一是确定报告应如何呈现以及如何构建它们。与数据工程师密切合作,我们准备了所有基础设施,以便我们的团队能够做出数据驱动的决策。
我们在 Google BigQuery 之上设置了 Metabase 作为我们的商业智能工具。通过 API,我设置了将第三方数据进行每日提取。一些数据仍然存储在 Google 表格中,但现在也已连接到 Google BigQuery。我还使用 dbt 来转换所有原始数据以供进一步分析。
我遵循的步骤如下
-
确保数据每日摄入。
- 一些广告网络通过 API 提供数据(例如,Audience Networks Ads API,Google Ad Manager API)。我使用 Google Cloud Function 定期运行,将数据提取到 Google BigQuery。
- 一些广告网络要求我们从其后台或电子邮件下载数据。与其手动下载 CSV/XLS,不如使用 Python 脚本将 CSV/XLS 格式转换为 Google BigQuery。
- 我添加了测试作为监控,以检查数据是否每日摄入。如果没有,我将收到 Slack 频道的警报。
-
准备数据转换。
- 所有原始数据都存储在 Google BigQuery 中的 `
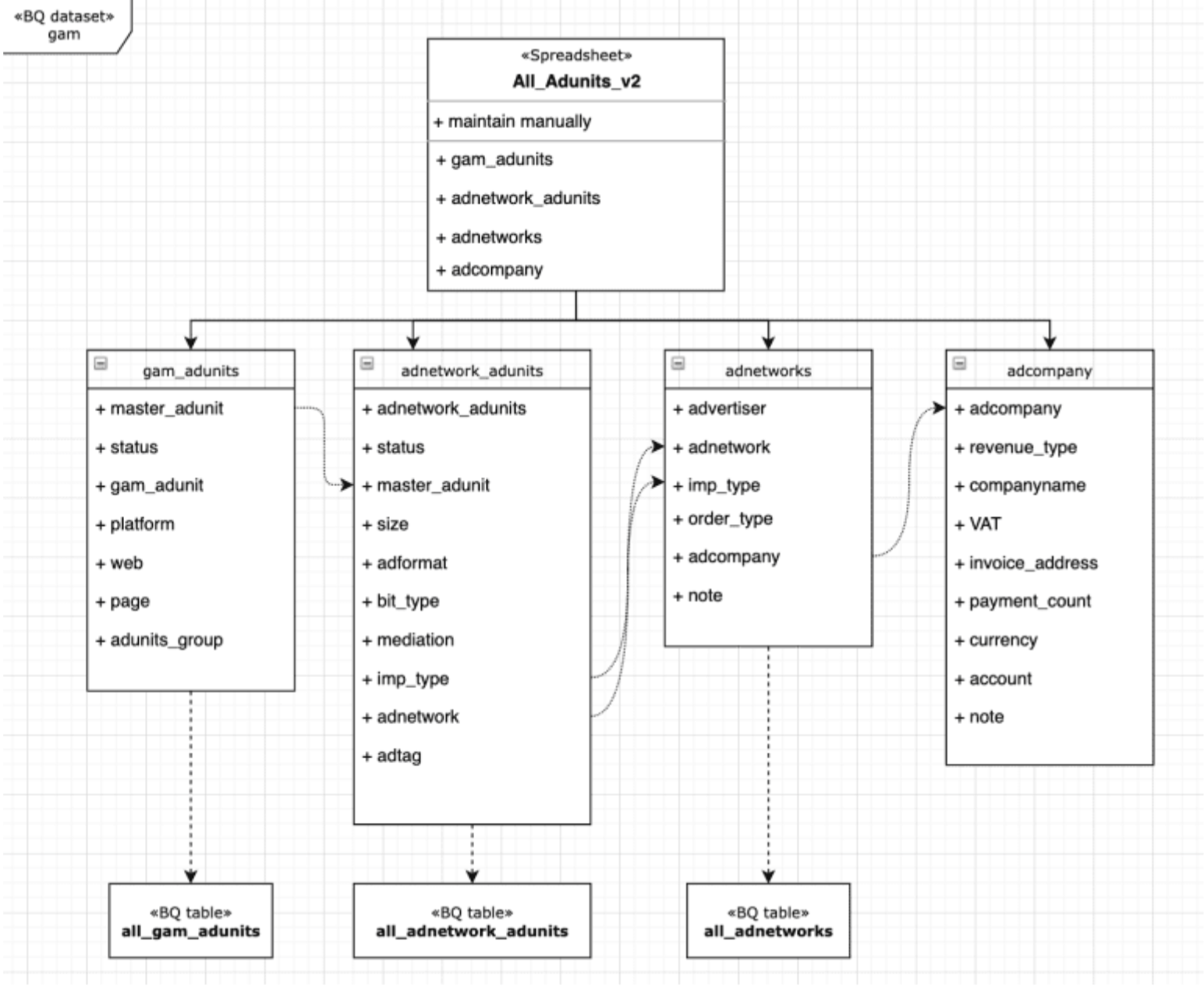
raw_XX` 表中(参见下面的架构)。 - 一些表格通过连接到 Google BigQuery 的 Google 表格进行手动编辑。这些是业务规则,例如我们合作的广告网络以及我们添加的广告单元。请参阅下面的 `
All_Adunits_v2`。
- 所有原始数据都存储在 Google BigQuery 中的 `
-
传输原始数据
- 我的目标是构建 `
report_adnetwork` 和 `report_adrevenue`。`report_adnetwork` 整合了所有原始数据和业务规则,以便轻松查看广告网络中广告单元的展示次数。`report_adrevenue` 是 `report_adnetwork` 的扩展,这样我就可以轻松比较所有广告网络广告单元的展示次数。
- 我的目标是构建 `
-
创建基于已传输到 Google BigQuery 的数据的仪表盘。
结构如下:原始数据 → 按广告网络分类的表 → 按广告收入分类的表
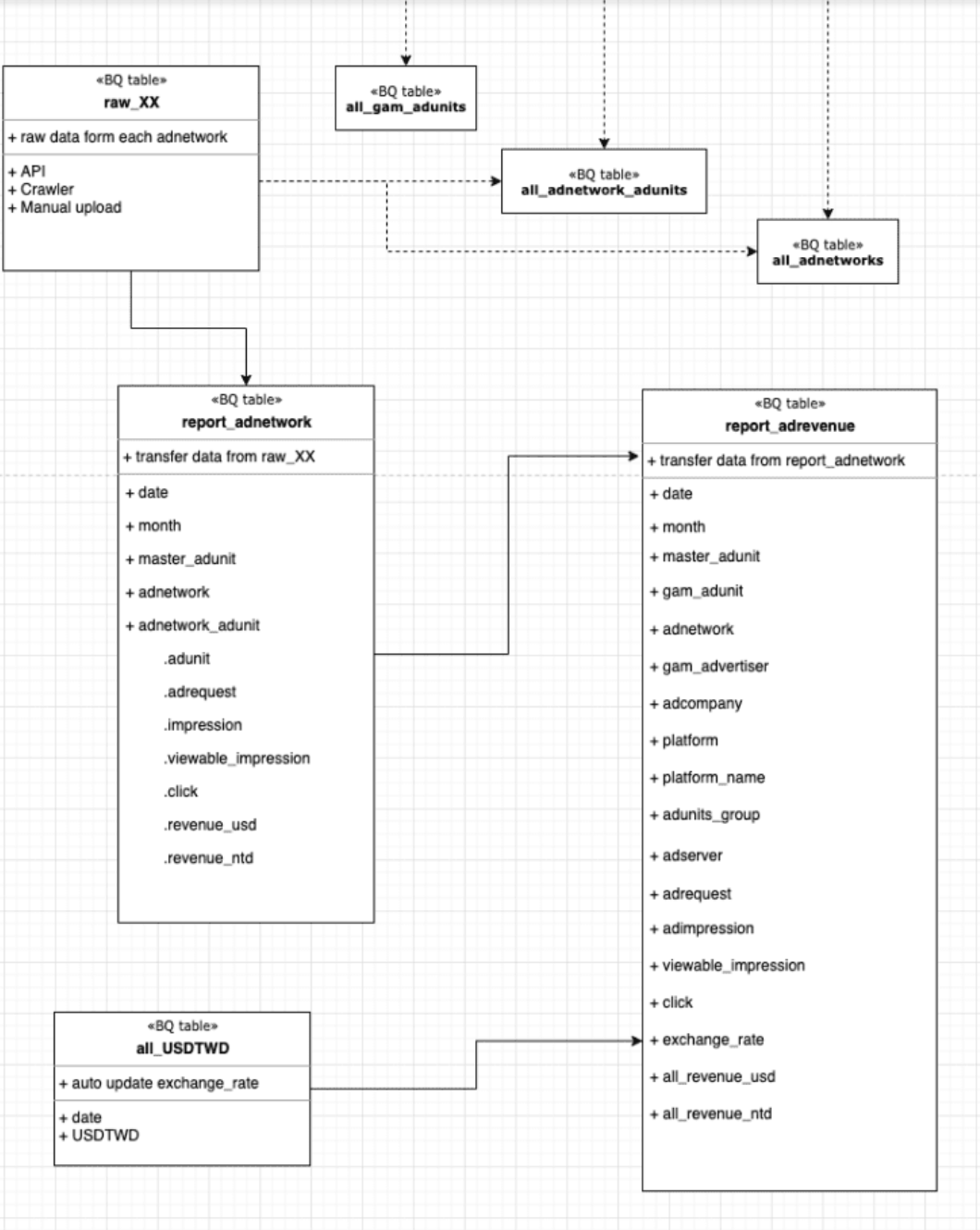
最终表格显示了不同时期的收入。通过这个表格,我的团队可以从不同角度分析数据:按平台、按广告网络、按广告单元等。
对于许多项目,我使用了 Metabase 和 Google Data Studio 来帮助我。我的团队非常喜欢使用 Metabase Dashboard Subscriptions 功能,该功能会将报告发送到我们公司的 Slack 频道,并将最重要的指标呈现在我们面前。我们还使用 Data Studio 来制作一些自助式仪表盘。
尽管我花了几个月的时间学习和构建仪表盘,但这确实帮助我的团队更好地理解了我们的业绩。
作为产品经理,以下是我借助仪表盘追踪的内容
- 我们高级计划的客户获取漏斗:我的团队可以看到有多少用户注册、尝试了高级功能并转化;
- 正在进行的实验:我们运行 A/B 测试并监控其效果。我通常在实验启动前构建仪表盘,从而实现顺畅的跟踪过程;
- 用户旅程:我的团队监控用户在关键路径上的表现。
仪表盘帮助我的团队提高了效率
- 设计师们开始分析哪些步骤可能导致用户摩擦;
- 工程师们开始运行更多实验;
- 其他部门也采纳了这种思维方式,因为他们可以合理地追踪其各项举措的表现;
作为产品经理,我从这种数据驱动的方法中获益良多。当出现任何对话时,我可以快速提取所有需要的信息并做出深思熟虑的决定。
最棒的是,数据通常不言自明,并且能团结团队。当我们进行实验时,我们都能看到其表现,并且不再需要花费时间争论。