理解用户旅程的复杂性
直到最近,由于使用传统可视化工具分析复杂、分支的用户流几乎是不可能的,所以要全面了解用户旅程非常困难。我们没有清晰的方法来捕捉每个路径并精确地找出用户在哪里流失,导致我们的转化分析不完整。
- 主要问题在于,传统的工具无法显示多个分支路径,比如简单的漏斗图,因此关键的洞察常常被忽略。
我有机会通过 Metabase 新的 Sankey 图可视化,将数百万原始事件日志转化为从注册到潜在客户生成的清晰的转化漏斗可视化叙述,从而直接应对这一挑战。这一突破不仅揭示了复杂的用户转换,还提供了可操作的见解,帮助我们完善了转化策略。(有关更多技术细节,请随时查看我的 GitHub 仓库)
以下是 Thallys 讨论的整个设置的演练。
用户旅程中的数据挑战
处理数百万事件记录本身就带来了一系列挑战。
- 重复事件。用户可能会反复触发相同的操作(例如多次点击支持按钮),如果不进行过滤,这可能会夸大我们的指标。
- 时间顺序的完整性。事件按正确的顺序发生至关重要,例如,注册必须在凭据屏幕显示之前发生,并且该视图必须在任何后续操作之前。
- 有效的过滤和聚合。处理大型数据集需要一个强大的 SQL 查询,该查询可以有效地过滤和聚合数据,同时保持正确的顺序。
解决这些问题对于构建一个可靠的用户旅程 Sankey 图至关重要,该图显示了用户在哪里流失以及转化在哪里发生。
逐步使用 SQL 构建用户旅程
为了分解问题,我使用公用表表达式 (CTE) 将转化漏斗划分为不同的阶段。
第一步:早期过滤
我从一个基础 CTE 开始,对大量数据集进行早期过滤,这是处理大型数据集的关键步骤。
WITH events_data AS (
SELECT
ke.user_id
,ke.event_timestamp
,mu.user_creation_date
,ke.event_id
,mu.user_origin
,ke.plataform_origin
,mu.covenant
FROM dbdelivery.tb_konsidb_events ke
JOIN dbdelivery.tb_mongo_users mu
ON ke.user_id = mu.user_id
WHERE mu.covenant IN (
'PREFEITURA DE GOIÂNIA',
'GOVERNO DO RIO DE JANEIRO',
'GOVERNO DE AMAZONAS',
'GOVERNO DO PARANÁ'
)
AND event_id IN (
‘registration_completed','registration_completed_sms', 'registration_completed_email','opened_easy_consig_registries_screen', 'opened_registries_screen', 'opened_govpe_registries_screen',
'clicked_more_registry_easy_consig_screen','clicked_easy_consig_registries_support','clicked_registries_screen_support_button', 'clicked_del_registry_easy_consig_screen',
'clicked_finish_btn_easy_consig_screen', 'gave_registry',
...
...
...
'no_lead_covenant_confirmation_screen','no_lead_user_correct_covenant', 'wrong_registry_error_screen_opened','clicked_wrong_registry_screen_retry_btn','clicked_wrong_registry_support_btn','clicked_easy_consig_registries_support','clicked_blocked_benefit_card','splash_screen_view','opened_unavailable_access_screen', 'clicked_support_unavailable_access')
),
第二步:分解漏斗
然后,我将转化漏斗划分为不同的阶段(例如,注册、凭据屏幕视图和潜在客户生成)。每个阶段都有自己的 CTE,这样可以更容易地独立处理和排除每个步骤的故障。
registration_completed AS (
-- This CTE identifies when users completed the registration process
SELECT
user_id
,user_creation_date
,user_origin
,plataforma
,covenant
,MIN(event_timestamp) AS event_timestamp
FROM events_data
WHERE event_id IN (
'registration_completed',
'registration_completed_email',
'registration_completed_sms'
)
GROUP BY 1, 2, 3, 4, 5
),
此查询捕获每个用户的第一个注册事件,反映其旅程的真正起点。
第三步:捕获用户旅程中的第一个事件
我使用了以下技术来确保我只捕获用户在给定阶段的第一个事件。
saw_credentials_screen AS (
SELECT
user_id
,event_timestamp
,user_creation_date
,user_origin
,plataforma
,covenant
FROM events_data
WHERE evento_id IN ('opened_contracting_psw_screen','credentials_screen_opened')
QUALIFY ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY event_timestamp ASC) = 1
),
使用 `ROW_NUMBER` 的 `QUALIFY` 可确保当用户注册时,即使发生多个注册事件,也只记录最早的一个。
第四步:确保时间顺序正确
然后,漏斗中的每个事件都必须发生在上一阶段之后。为了强制执行正确的顺序,我使用了特定的条件连接了 CTE。例如:
FROM registration_completed
JOIN saw_credentials_screen
ON registration_completed.user_id = saw_credentials_screen.user_id
AND registration_completed.event_timestamp < saw_credentials_screen.event_timestamp
-- Ensure the user passed through the previous funnel step
此连接确保只有在用户的凭据屏幕视图发生在注册之后才被计算在内,从而过滤掉任何不遵循正确顺序的数据。
使用 Databricks 和物化视图
为了处理我们庞大的数据集,我利用了我们的多层数据管道。我们的数据经过几个阶段,从原始数据摄取(Stage 和 Raw)到清理和验证(Trusted 和 Delivery),然后再到 Redshift。起初,我在 Delivery 表上运行了我的查询,这些表已经包含经过处理的数据。然而,查询的复杂性使得 Redshift 无法直接处理。
为了解决这个问题,我首先在 Databricks 中处理数据,创建了一个中间的、预聚合的表。然后,我将该表加载到 Redshift 中,并在其之上构建了一个物化视图,以确保我们在 Metabase 中的查询能够快速可靠地运行。
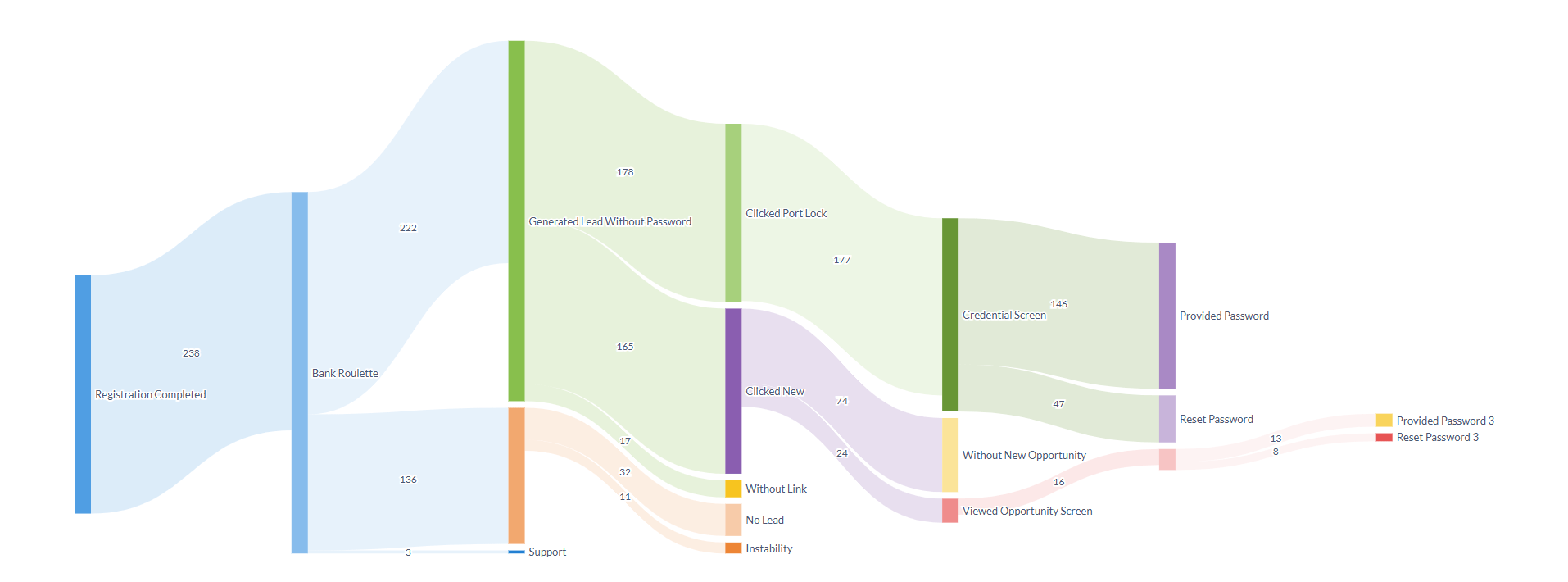
使用 Sankey 图揭示转化洞察
最终输出是一个清晰的用户旅程可视化表示,展示了整个转化漏斗,包括关键的流失点和转化成功点。这种可视化立即让团队了解我们的转化过程在哪里出现问题,以及哪些阶段需要有针对性的改进。