


为什么你的团队需要一个指标层
“仪表板 A、B 和 C 上的用户数不同。你能解释一下发生了什么吗?”
“这个报告中这个计数器的定义已过时。我们能尽快修复它吗?”
如果你曾在分析领域工作过,你很可能反复听到这些问题。不一致的指标会导致混淆、浪费时间,并削弱对数据的信任。当报告显示相同的指标数值不同时,业务用户在做决策时会遇到困难。与此同时,数据团队忙于处理突发事件,而不是专注于战略性工作。
罪魁祸首是什么?缺乏一个集中的 指标层,它是一种在单一位置定义和存储指标的方式,以便你组织中的每个人都使用相同的逻辑。
什么是指标层?
指标层(也称为无头 BI 或指标存储)位于你的数据仓库和商业智能 (BI) 工具之间。它充当一个单一的事实来源,用于在不同的仪表板、报告和应用程序中定义和管理指标。
可以这样理解
- GitHub 为你的代码集中管理并进行版本控制。
- 你的数据仓库作为原始数据和转换后数据的中央存储库。
- 指标层确保关键指标的业务逻辑在所有 BI 工具中保持一致。
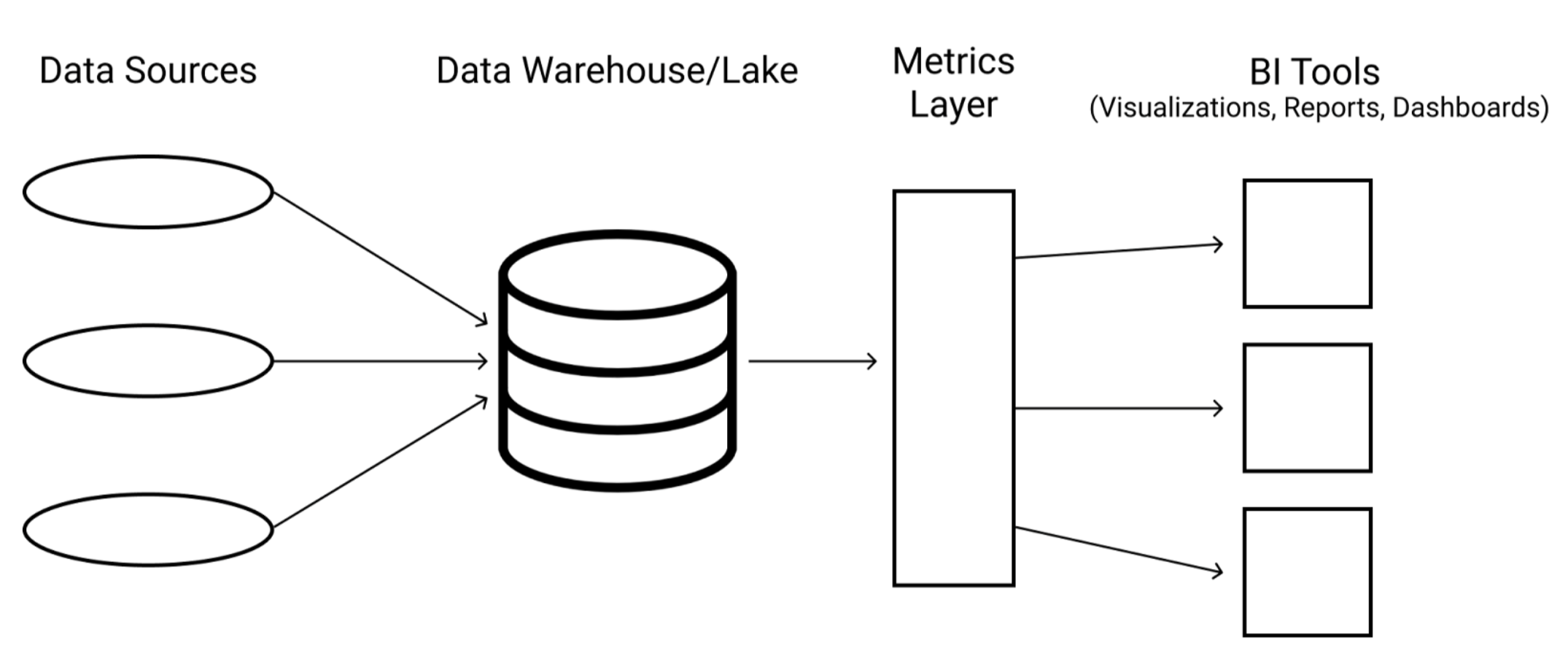
指标层应该位于数据存储位置和数据使用方式之间,以实现统一的定义。
你的组织有多个仪表板。它可能还有多个商业智能 (BI) 工具。你真的想在每个出口中都为指标定义业务逻辑吗?如果随着业务的发展,逻辑发生了变化怎么办?这会增加其中一个实例在有人查看并做出决策时略有偏差或过时的可能性。但是,一个在多个地方使用的单一、商定的定义可以解决这个难题,并且是 DRY 原则(不要重复自己)的一个很好的例子。
如何定义和构建指标层
一开始不需要大量的工程投入。这是一个简单的方法
步骤 1:定义你的指标
首先写下每个关键指标应如何计算。
问一些问题,例如
- 我应该使用什么时间范围?每日?每周?每月?
- 计算用户时,如何处理重复项?
- 什么才算“活跃”或“不活跃”用户?
- 我应该应用哪些过滤器或标志?
一个好的第一步是编写 SQL 查询并将其存储在共享文档中。但跨报告复制粘贴 SQL 会很快变得混乱。
步骤 2:集中化指标定义
将你的指标定义移到一个多个 BI 工具都可以访问的单一位置。
一些常见的方法
- 在数据仓库中创建存储预计算指标的视图或表。
- 使用语义层来定义可重用的指标。
- 将指标定义存储在 YAML 中(如果使用外部无头 BI 工具)。
步骤 3:测试和实施
一旦定义了指标,就在不同报告中进行测试,以确保它们返回一致的结果。目标是确保无论指标出现在哪里——仪表板、嵌入式报告还是 API 调用——它始终显示相同的数字。
一个结构良好的指标层可以减少不一致性,减少重复工作,并建立对你数据的信任。
在 Metabase 中阅读有关 指标 的更多信息。