


在一个数据驱动的世界里,干净的数据对于做出明智的决策至关重要。然而,处理脏数据是一个普遍的挑战——它可能导致分析不佳和错误决策。在本文中,我们将介绍三种清洗脏数据的方法,将您的脏数据集转化为可以信任的东西。
如何清洗数据
让我们探讨将脏数据处理成干净数据的不同方法,从使用 Metabase 中的工具到设置完整的数据管道,甚至使用 AI。
使用 Metabase 中的模型清洗数据
在 Metabase 中清洗数据的简单方法是使用 模型。这些是 Metabase 中的关键元素,允许您根据特定标准定义和清洗数据。
模型可以用 SQL 或使用 查询构建器 来构建,从而允许您直接在 Metabase 中清洗和组织数据。它们非常适合小型到中型数据集,特别是当您需要快速解决方案时。
为什么使用 Metabase 中的模型?
在 Metabase 中实施数据清洗程序的一种最佳方法是开发一个模型,该模型基于特定标准表示数据。模型是 Metabase 的基本构建块。它们可以与派生表或专门保存的问题进行比较,作为新分析的起点。模型可以基于 SQL 或查询构建器问题构建,允许包含自定义列和计算列。
- 易于使用:无需高级技术技能即可直接在平台中清洗数据。
- 赋能您的团队:业务团队可以清洗和调整数据,而无需始终依赖数据团队。
缺点
- 不适用于大型数据集:模型可能难以处理更复杂或大型的数据集。
示例
让我们考虑一个在线商店销售交易的示例数据集。原始数据可能看起来像这样
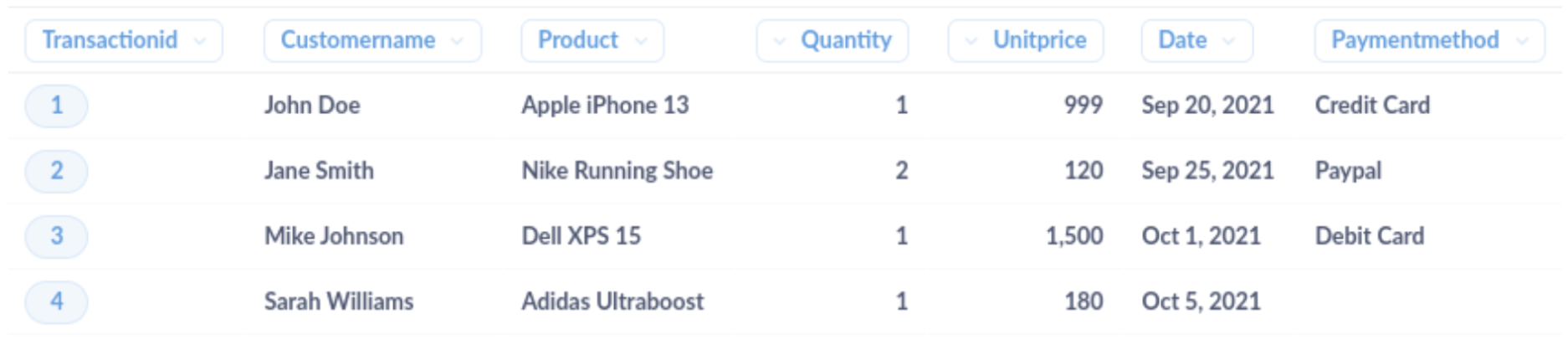
在此数据集中,有几个问题需要解决。为了解决它们,您可以在 Metabase 中实现模式或函数
-
不一致的产品名称:使用 regexextract 通过移除品牌名称并仅保留产品型号来标准化产品名称。示例模式:
REGEXEXTRACT([Product], '^(?:Apple|Nike|Dell|Adidas) (.*)$') -
缺少付款方式信息:实现一个函数,该函数检查缺失的付款方式值,并用默认值或占位符替换它们。示例 函数:
COALESCE([PaymentMethod], 'Not Provided')
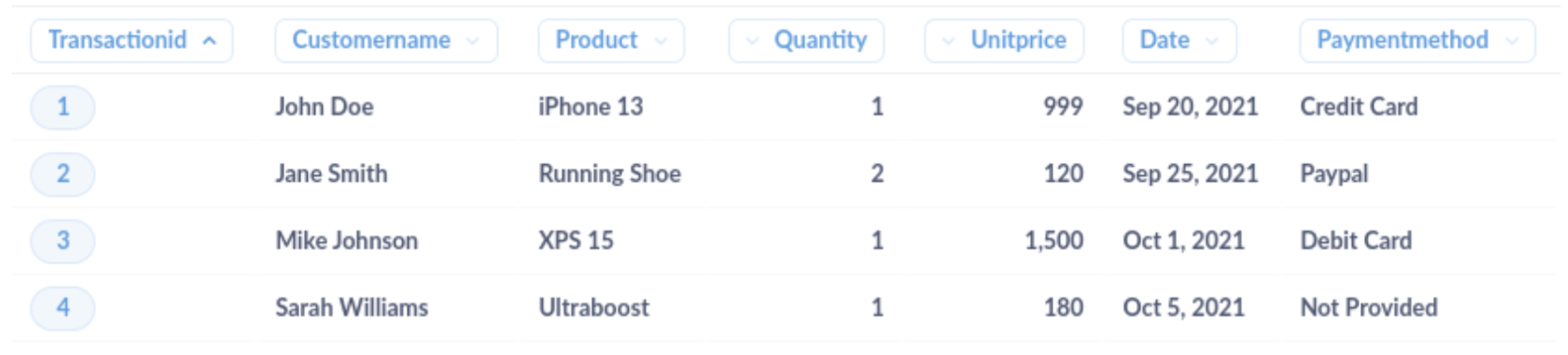
清洗后的数据集应如下所示
在您的转换管道中清洗数据
如果您处理的是大型或复杂的数据集,数据转换管道可以提供帮助。此过程允许您提前清洗数据,以便在无需额外工作的情况下即可进行分析。
通过编写 SQL 查询来自动化此过程,您可以在数据进入分析平台之前确保数据干净。
想了解更多?: ETL、ELT 和反向 ETL
为什么使用数据转换管道?
- 可扩展:适用于大型、复杂的数据集。
- 节省时间:自动化清洗过程,减少手动工作。
解决根本问题:在数据源处清洗数据,而不仅仅是应用快速修复。
缺点
需要技术技能:构建和维护管道可能需要更多的专业知识和资源。
转换管道示例
这是客户订单的示例数据集。
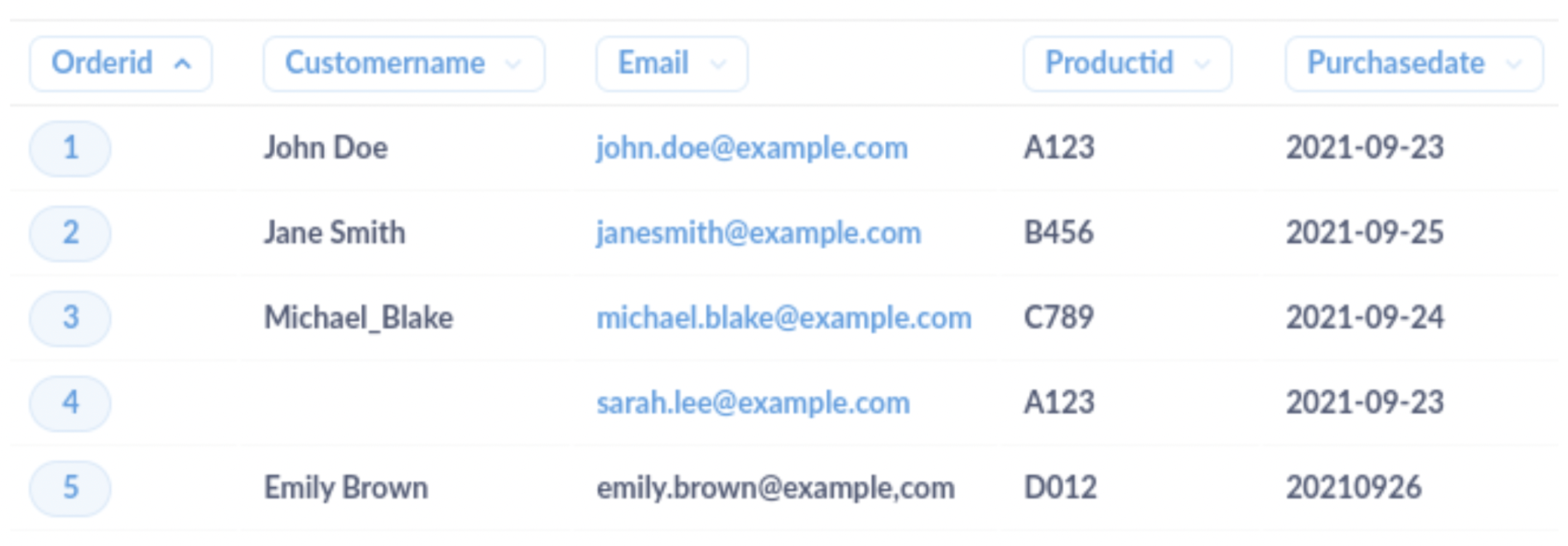
在此示例中,有几个问题需要进行清理
-
CustomerName字段中的格式不一致(例如,下划线而不是空格) -
CustomerName字段中的数据缺失(NULL 值) -
第 5 行
Email字段中的分隔符不正确(逗号而不是句点) -
第 5 行
PurchaseDate字段中的日期格式不一致
您可以使用 SQL 来清洗数据。以下是如何执行此操作的示例
-- Create a temporary table with cleaned data
CREATE TEMPORARY TABLE cleaned_orders AS
SELECT
OrderID,
-- Replace underscores with spaces and handle NULL values in the CustomerName field
COALESCE(NULLIF(REPLACE(CustomerName, '_', ' '), ''), 'Unknown') AS CleanedCustomerName,
-- Replace comma with period in the Email field
REPLACE(Email, ',', '.') AS CleanedEmail,
ProductID,
-- Standardize the date format in the PurchaseDate field
STR_TO_DATE(PurchaseDate, '%Y-%m-%d') AS CleanedPurchaseDate
FROM
raw_orders;
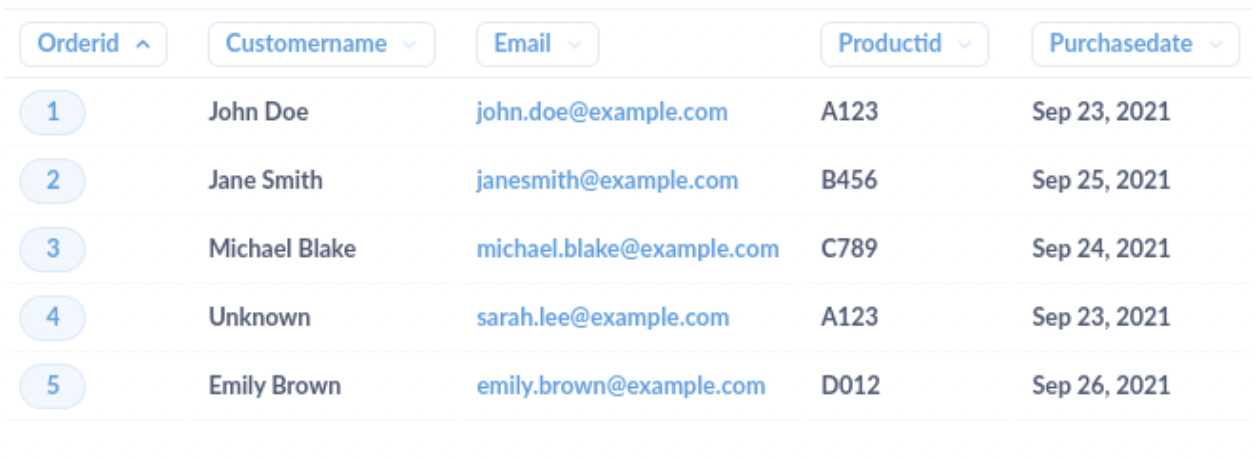
清洗后的数据集将如下所示
使用 AI 清洗数据
AI 正在改变我们处理数据清洗的方式。特别是像 OpenAI 的 ChatGPT 模型这样的大型语言模型,先进的算法和机器学习技术可以自动化数据清洗过程。
为什么使用 AI 进行数据清洗?
- 自动化:AI 自动化清洗过程,减少人为错误。
- 处理大型数据集:随着数据量的增长,可以快速扩展。
- 随时间改进:AI 在处理更多信息时,清洗数据的能力会提高。
缺点
- 初始投资:设置 AI 驱动的解决方案可能需要更多的前期工作。
- 仍需要人工监督:虽然 AI 可以清洗很多内容,但通常需要人工审查结果。
使用 AI 的示例
AI 可以执行的数据清洗的更复杂示例是识别和解决来自多个数据源的服装产品属性中的不一致之处。这通常涉及理解不同属性(如颜色、尺寸和款式)之间的上下文、语义和关系。
示例数据集

在此示例数据集中,来自三个不同数据源的产品属性不一致,需要为在线服装店进行标准化。传统的清洗方法可能难以有效识别和解决这些不一致之处,因为属性的术语、顺序和结构各不相同。
但是,由 AI 驱动的解决方案可以分析不同属性之间的上下文、语义和关系,并将它们映射到标准化的属性集。例如,AI 可以识别“Women’s Dress, Blue, Size M”、“Female, Dress, M, Blu”和“Dress, Medium, Woman, Color: Blue”都指向相同的产品属性,并将它们映射到单个标准化格式,如“Gender: Female, Category: Dress, Color: Blue, Size: Medium”。
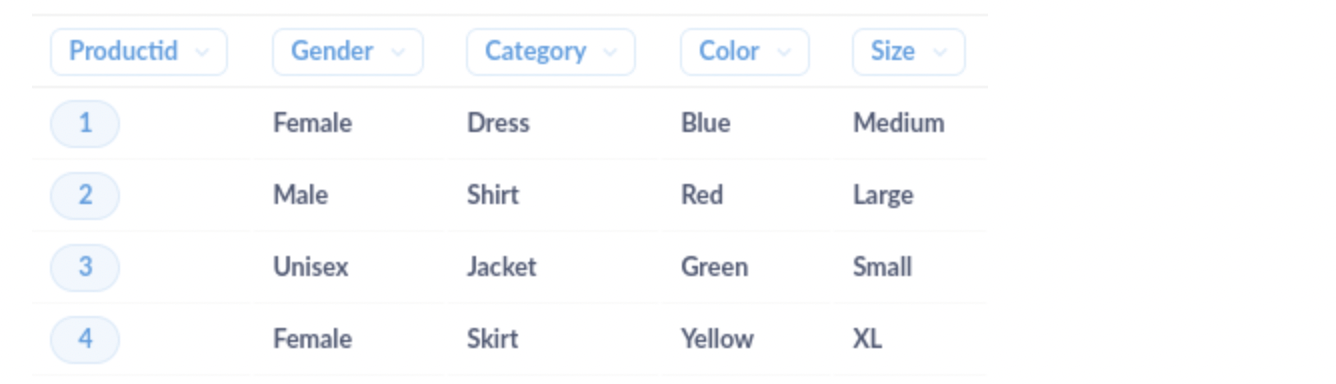
清洗后的数据集将如下所示

现在我们可以将产品属性拆分成单独的列,以便更轻松地进行分析。
您应该采取哪种方法?
最适合您业务的数据清洗方法取决于多种因素,例如数据的类型和质量、数据集的大小和复杂性、可用资源以及特定的业务目标。在选择一种方法集成到您的技术堆栈之前,测试和评估不同的清洗方法至关重要。通常,公司会混合使用上述方法。检查数据源是否与您首选的方法兼容,并确保您拥有执行所选解决方案所需的资源。